基于jupyter notebook的简单爬虫学习记录
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录前言一、pandas是什么?二、使用步骤1.引入库2.读入数据总结前言本人为编程小白,目前为零基础入门者,目标为从事数据分析行业,因此努力在往后日子里提升数分能力(软件实操能力、逻辑思考水平)。本文为个人爬虫学习经过,供个人回顾复习用,各版块学习教程均来源于网络(具体后文会贴上,方便其他感兴趣的同学一起学习)。若有逻辑/语法错
目录
前言
本人为编程小白,目前为零基础入门者,目标为从事数据分析行业,因此努力在往后日子里提升数分能力(软件实操能力、逻辑思考水平)。本文为个人爬虫学习经过,供个人回顾复习用,各版块学习教程均来源于网络(具体后文会贴上,方便其他感兴趣的同学一起学习)。若有逻辑/语法错误,请pro们轻喷~
使用工具:python语言、jupyter notebook
目标:熟悉简单的爬虫过程、操作,顺利爬取某站弹幕、评论,为后续数据分析提供数据基础。
学习教程:爬虫入门教程①— 爬虫简介 - 简书 (jianshu.com),此教程内有非常详细的爬虫入门知识。
一、基础理解
爬虫基本步骤:
①获取数据:找到网页,定位数据
②解析数据:数据中存在无用信息,对其进行过滤,获取有用信息
③存储数据:对过滤得到的数据进行存储,存储为便于后续处理的格式
关于网页的基础知识:
从我们在浏览器地址栏输入网址敲下了回车之后,到一个鲜活的网页呈现在我们面前,这中间究竟发生了什么呢?

一个请求对应一个响应。构成了一个完整的HTTP请求。爬虫如果要获取到一个网页,那么就一定要发送一个HTTP请求,就必须经过这些过程。
上述内容转载简书- 终可见丶
二、前期准备
安装requests(Python HTTP请求工具)

安装lxml(解析网页结构工具)

安装beautifulsoup(网页文档解析工具)

三、爬虫实操【入门】
本节目标为爬取某电影网站首页的影片信息数据。
3.1、引入库
import requests
import csv
from bs4 import BeautifulSoup
# 导入要使用的库3.2、请求网页
利用requests获取网页源代码。在原教程中,作者为了方便调试代码,先将网页保存到本地,此处略过,详细可查其教程第⑧期。
获取源代码之后,将结果赋值给response。
url = "https://movie.douban.com/cinema/later/chengdu/" # ulr:个人理解为网页地址
fake_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'
}
# 伪装成浏览器的header,好比张麻子拿着上任书冒充马邦德当县长,可以帮助我们骗过网站的反爬机制
response = requests.get(url, headers=fake_headers)
# requests向网站发起一个get请求,并将请求的结果赋值给response对象,请求参数里面把假的请求header加上3.3、解析网页
利用BeatuifulSoup加载网页源代码并进行解析转换。
soup = BeautifulSoup(response.content.decode('utf-8'), 'lxml')
# 逗号前的参数,表示此时输出的响应结果为二进制,在响应结果之后加上.decode('utf-8')可对其进行解码
# 逗号后的参数,‘lxml’是BeautifulSoup采用的网页解析器。
print(soup) # 尝试输出BeautifulSoup转换后的内容,若无报错可以继续下一步3.3.1、网页解读
个人认为解读网页源代码是较重要的一步,尤其是对后续理解代码。
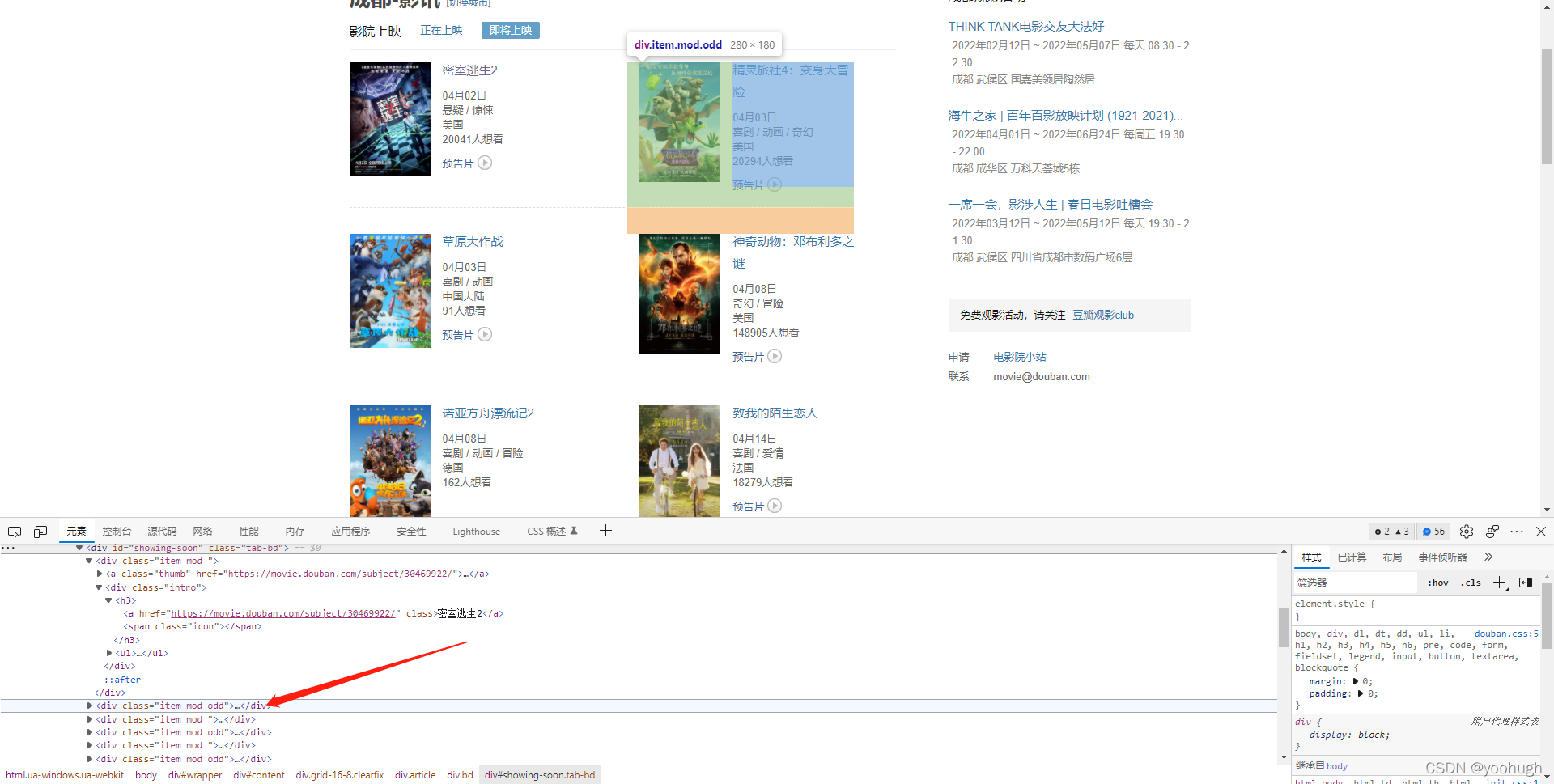
打开电影网站。将鼠标移动到第一步电影名称上,在网页出现响应(字体变色)时单击右键,选择检查,网页底端将会弹出源代码窗口,此时代码定位为「电影链接」与「电影名称」。

移动鼠标至<div id="showing-soon">行,网页会自动定位到至整个电影简介区域

将鼠标移动至<div class="item mod odd">,网页会自动定位到单部电影简介区域。(这里item mod和item mod odd唯一区别应该是:前者在第一列,后者在第二列)
展开<ul>...</ul>一列,并将鼠标移动至其中以 [li] 开头的任一行,网页都会定位至相应的电影具体信息区域。

由此可以得知,我们想要爬取的信息都会在以上的源代码中,下一步就可基于以上源代码,通过BeatuifulSoup对信息进行提取。
3.3.2、熟悉部分BeautifulSoup语法规则
soup.find('a', id='next'),搜索soup包含的源代码中,遇到的第一个有属性为id,值为next的<a>对象,比如<a id="next">...</a>。
soup.find_all('a', class_='next'),搜索soup包含的源代码中,遇到的所有属性为class,值为next的<a>的 可迭代对象,比如<a class="next">...</a>。
由于Python中class是关键字,因此在find的过程中,遇到可用class_=' '代替。
此处原教程利用for循环,对all_movies中的代码进行遍历搜寻,找到每一项'div', class_="item"(即每一个包含单部电影信息的代码),并赋值给each_movie,当all_movies中不再有单部影片信息的代码时,循环终止。
all_movies = soup.find('div', id="showing-soon") # 先找到最大的div
# print(all_movies) # 尝试输出最大的div的内容,判断是否有误
for each_movie in all_movies.find_all('div', class_="item"): # 从最大的div里面找到影片的div
# print(each_movie) # 尝试输出每个影片div的内容,判断是否有误
all_a_tag = each_movie.find_all('a') # 找到所有的a标签
all_li_tag = each_movie.find_all('li') # 找到所有的li标签
movie_name = all_a_tag[1].text # 从第二个a标签的文字内容提取影片名字
moive_href = all_a_tag[1]['href'] # 从第二个a标签的文字内容提取影片链接
movie_date = all_li_tag[0].text # 从第1个li标签的文字内容提取影片上映时间,下同
movie_type = all_li_tag[1].text
movie_area = all_li_tag[2].text
movie_lovers = all_li_tag[3].text
print('名字:{},链接:{},日期:{},类型:{},地区:{}, 关注者:{}'.format(
movie_name, moive_href, movie_date, movie_type, movie_area, movie_lovers))3.4、数据存储
到上一步,我们需要的信息都已从源代码中抓出来,下一步是对信息进行存储,转换为便于我们处理的格式。我想要将文件存储为csv格式,因此需要导入csv包。
可以通过csv.writer()将文件对象作为参数进行传输赋值给writer,接下来便能够对writer进行读写操作。调用writer中的writerow(),可以把由字符串组成的数组写入csv文件中。
import requests
import csv
from bs4 import BeautifulSoup
url = "https://movie.douban.com/cinema/later/chengdu/"
fake_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'
}
response = requests.get(url, headers=fake_headers)
soup = BeautifulSoup(response.content.decode('utf-8'), 'lxml')
all_movies = soup.find('div', id="showing-soon")
csv_file = open('data.csv', 'w', encoding="gbk", newline='')
writer = csv.writer(csv_file)
# 语法规则为file_obj = open("file_name", 'mode', encoding="encoding")
# file_obj是一个文件对象,之后我们读取、写入数据都通过这个对象进行操作
# file_name为文件名;mode为操作文件的方式,如r,w,a, r+
# encoding为遵循的编码格式,Windows的默认编码是gbk,linux系统基本上是utf-8
# newline='' 是为了让writer自动添加的换行符和文件的不重复,防止出现跳行的情况
writer.writerow(["影片名", "链接", "上映日期", "影片类型", "地区", "关注者"]) # 写入标题
for each_movie in all_movies.find_all('div', class_="item"):
all_a_tag = each_movie.find_all('a')
all_li_tag = each_movie.find_all('li')
movie_name = all_a_tag[1].text
moive_href = all_a_tag[1]['href']
movie_date = all_li_tag[0].text
movie_type = all_li_tag[1].text
movie_area = all_li_tag[2].text
movie_lovers = all_li_tag[3].text.replace("想看", '')
print('名字:{},链接:{},日期:{},类型:{},地区:{}, 关注者:{}'.format(
movie_name, moive_href, movie_date, movie_type, movie_area, movie_lovers))
writer.writerow([movie_name, moive_href, movie_date, movie_type, movie_area, movie_lovers])
# .format()这个方法的用法是把字符串里面的{}字符,按次序一一替换成 format() 接受的所有参数
csv_file.close()
print("write_finished!")最后,就可以在默认存储的文件夹中得到data文件啦~


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)