模型训练或测试时候显存爆掉(RuntimeError:CUDA out of memory)的几种可能及解决方案
RuntimeError:CUDA out of memory的几种排查方案
·
1. 真的显存不足,这种可以通过从单卡变为在多卡上面运行解决
这种时候可以使用nvidia-smi查看一下显卡情况,如下
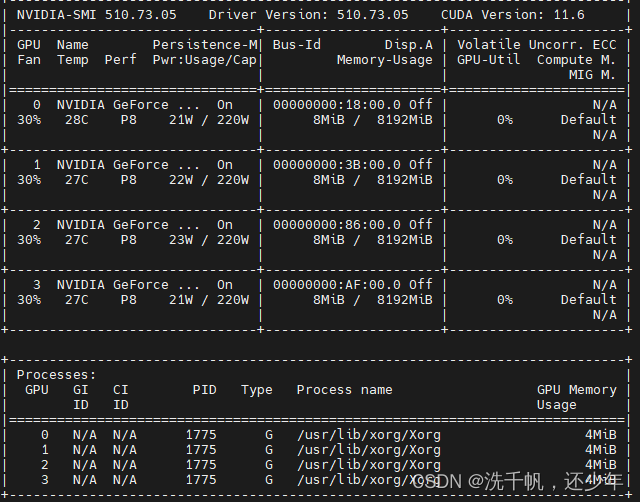
或者改一下num_of_worker:

改小试试看,如果不行继续排查
2. cuda和pytorch的版本不匹配
注意这里也有个小坑!
30系显卡不能装cuda11以前的!!
30系显卡架构换了,所以不能用之前的驱动,参考目录:https://docs.nvidia.com/deeplearning/cudnn/support-matrix/index.html,从参考目录中可以看见,cuda10系列不支持ampere架构的显卡
3. 测试的时候爆显存有可能是忘记设置no_grad, 示例代码如下:
当时的报错:

仅加model.eval()还是会有会有影响(在我使用LeNet的时候显存是不会爆炸的,使用Resnet就会,所以以防万一还是加上with torch.no_grad())
# 此处是test函数内部,大家加载自己定义的test的迭代器外部即可
model.eval()
with torch.no_grad():
for idx, (data, target) in enumerate(data_loader):
if args.gpu != -1:
data, target = data.to(args.device), target.to(args.device)
log_probs = net_g(data)
probs.append(log_probs)
# sum up batch loss
test_loss += F.cross_entropy(log_probs, target, reduction='sum').item()
# get the index of the max log-probability
y_pred = log_probs.data.max(1, keepdim=True)[1]
correct += y_pred.eq(target.data.view_as(y_pred)).long().cpu().sum()
4. 训练的时候爆内存(这个我没有自己使用过)
Pytorch 训练时有时候会因为加载的东西过多而爆显存,有些时候这种情况还可以使用cuda的清理技术进行修整,当然如果模型实在太大,那也没办法。
使用torch.cuda.empty_cache()删除一些不需要的变量代码示例如下:
参考:https://blog.csdn.net/xiaoxifei/article/details/84377204
try:
output = model(input)
except RuntimeError as exception:
if "out of memory" in str(exception):
print("WARNING: out of memory")
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
else:
raise exception
附录:
如果模型过大,
- 首先可以查一下模型里面有写经典的block是不是pytorch里面自带的有,比如ResNet结构,可以从pytorch自带的里面截取你需要的部分,我曾经的实验结果表明pytorch对于这些基本模型是有底层加速的。
- 可以降低下数据精度,比如从float32降半精度,使用这样的代码model.half()来申明半精度;这样也会减少些内存,我看你的GPU跑的情况使用半精度
如果想要模型运行时的显存监控:可以参考以下链接
https://oldpan.me/archives/pytorch-gpu-memory-usage-track
如果想要检测模型loss异常nan的情况可以使用:
from torch import autograd
with autograd.detect_anomaly():
inp = torch.rand(10, 10, requires_grad=True)
out = net(inp)
out.backward()

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)