Pytorch 在 Kaggle 上使用 GPU
Kaggle 上使用 GPU0. 环境介绍环境使用 Kaggle 里免费建立的 Notebook教程使用李沐老师的 动手学深度学习 网站和 视频讲解小技巧:当遇到函数看不懂的时候可以按 Shift+Tab 查看函数详解。1. Kaggle 上使用 GPU找到右边 Settings 里面的 Accelerator:选择 GPU:每周可以使用 36 小时:查看显卡信息:!nvidia-smi可以看到显
Kaggle 上使用 GPU
0. 环境介绍
环境使用 Kaggle 里免费建立的 Notebook
小技巧:当遇到函数看不懂的时候可以按 Shift+Tab 查看函数详解。
1. Kaggle 上使用 GPU
找到右边 Settings 里面的 Accelerator:
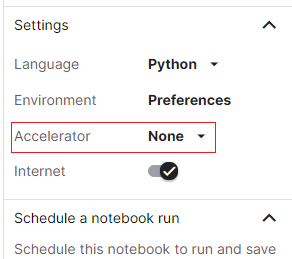
选择 GPU:
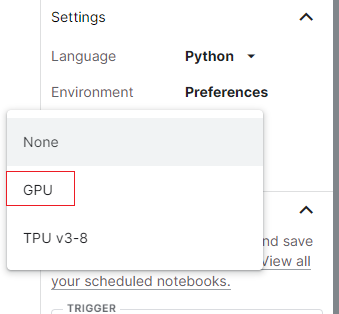
每周可以使用 36 小时:
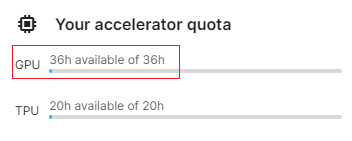
查看显卡信息:
!nvidia-smi
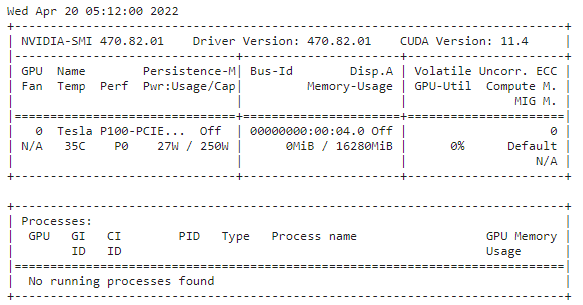
可以看到显卡为 Tesla P100,拥有 16G 显存。
2. 计算设备
我们可以指定用于存储和计算的设备,如 CPU 和 GPU。 默认情况下,张量是在内存中创建的,然后使用 CPU 计算它。
在 PyTorch 中,CPU 和 GPU 可以用
torch.device('cpu')和torch.device('cuda')表示。 应该注意的是,cpu 设备意味着所有物理 CPU 和内存, 这意味着 PyTorch 的计算将尝试使用所有 CPU 核心。 然而,gpu 设备只代表一个卡和相应的显存。 如果有多个GPU,我们使用torch.device(f'cuda:{i}')来表示第 i i i 块 GPU(从 0 0 0 开始)。 另外,cuda:0和cuda是等价的。
import torch
from torch import nn
torch.device('cpu'), torch.device('cuda'), torch.device('cuda:1')

查询可用 gpu 的数量:
torch.cuda.device_count()

定义了两个函数, 这两个函数允许我们在不存在所需所有GPU的情况下运行代码:
def try_gpu(i=0): #@save
"""如果存在,则返回gpu(i),否则返回cpu()"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def try_all_gpus(): #@save
"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]"""
devices = [torch.device(f'cuda:{i}')
for i in range(torch.cuda.device_count())]
return devices if devices else [torch.device('cpu')]
try_gpu(), try_gpu(10), try_all_gpus()

3. 张量与 GPU
查询张量所在的设备。 默认情况下,张量是在 CPU 上创建的:
x = torch.tensor([1, 2, 3])
x.device
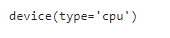
3.1 存储在 GPU 上
X = torch.ones(2, 3, device=try_gpu())
X

存储在另一个 GPU,实际上我是没有另外一个 GPU 的,所以会使用 CPU :
Y = torch.rand(2, 3, device=try_gpu(1))
Y

无论何时我们要对多个项进行操作, 它们都必须在同一个设备上。 例如,如果我们对两个张量求和, 我们需要确保两个张量都位于同一个设备上, 否则框架将不知道在哪里存储结果,甚至不知道在哪里执行计算。
X 在 GPU 上,Y 在 CPU,我们对它们进行求和:
X + Y

可以使用 X.cpu() 或者 Y.cuda() 使它们在一个设备上进行运算:
X.cpu() + Y, X + Y.cuda()

3.2 旁注
人们使用GPU来进行机器学习,因为单个 GPU 相对运行速度快。 但是在设备(CPU、GPU 和其他机器)之间传输数据比计算慢得多。 这也使得并行化变得更加困难,因为我们必须等待数据被发送(或者接收), 然后才能继续进行更多的操作。 这就是为什么拷贝操作要格外小心。 根据经验,多个小操作比一个大操作糟糕得多。 此外,一次执行几个操作比代码中散布的许多单个操作要好得多(除非你确信自己在做什么)。 如果一个设备必须等待另一个设备才能执行其他操作, 那么这样的操作可能会阻塞。 这有点像排队订购咖啡,而不像通过电话预先订购: 当你到店的时候,咖啡已经准备好了。
最后,当我们打印张量或将张量转换为 NumPy 格式时, 如果数据不在内存中,框架会首先将其复制到内存中, 这会导致额外的传输开销。 更糟糕的是,它现在受制于全局解释器锁,使得一切都得等待 Python 完成。
4. 神经网络和 GPU
神经网络模型可以指定设备。 下面的代码将模型参数放在 GPU 上:
net = nn.Sequential(nn.Linear(3, 1))
net = net.to(device=try_gpu())
net(X)

确认模型参数存储在同一个 GPU 上::
net[0].weight.data.device


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)