饱暖思淫欲之美女图片的Python爬虫实例(一)
美女图片的Python爬虫实例==该爬虫面向成年人且有一定的自控能力(涉及部分性感图片,仅用于爬虫实例研究)==前言目标思路步骤第一步:查看网页结构F12大法粗略获取网页对应网页结构细看图片信息对应网页结构第二步:获取对应网页开发环境:网页信息python获取:第一步:获取网页第二步:解析网页第三步:获取首页封面图片至此,首页观看人数超500的封面图片已保存至对应目录下第三步:获取写真专辑图片目的
美女图片的Python爬虫实例
该爬虫面向成年人且有一定的自控能力(涉及部分性感图片,仅用于爬虫实例研究)
前言
最近写论文写的心态炸了,感觉得找个乐呵乐呵的事情放松一下。逛网页看到了个捋图片的软件:[秀人网]美图下载1.1 版 — By、笑孤城
奈何试用效果不佳,准备自己动手,丰衣足食(主要是里面的妹子,要啥有啥)
饱暖思淫欲,动手方足食
目标
通过爬虫,得到 [秀人网] 里面的小姐姐并给她们一个温暖的家
衣沾不足惜,但使愿无违
思路
- 百度 秀人网,得到网址:https://www.xrmn5.com/XiuRen/,去首页:https://www.xrmn5.com/
- F12看网页结构,通过正则表达式对链接和结构进行解析并获取
- Pycharm+Python 3.7,要啥有啥
- 成功获取,大功告成
乱花渐欲迷人眼
步骤
第一步:查看网页结构
F12大法
粗略获取网页
通过对首页进行 “检查” ,我们得到了这样的信息:
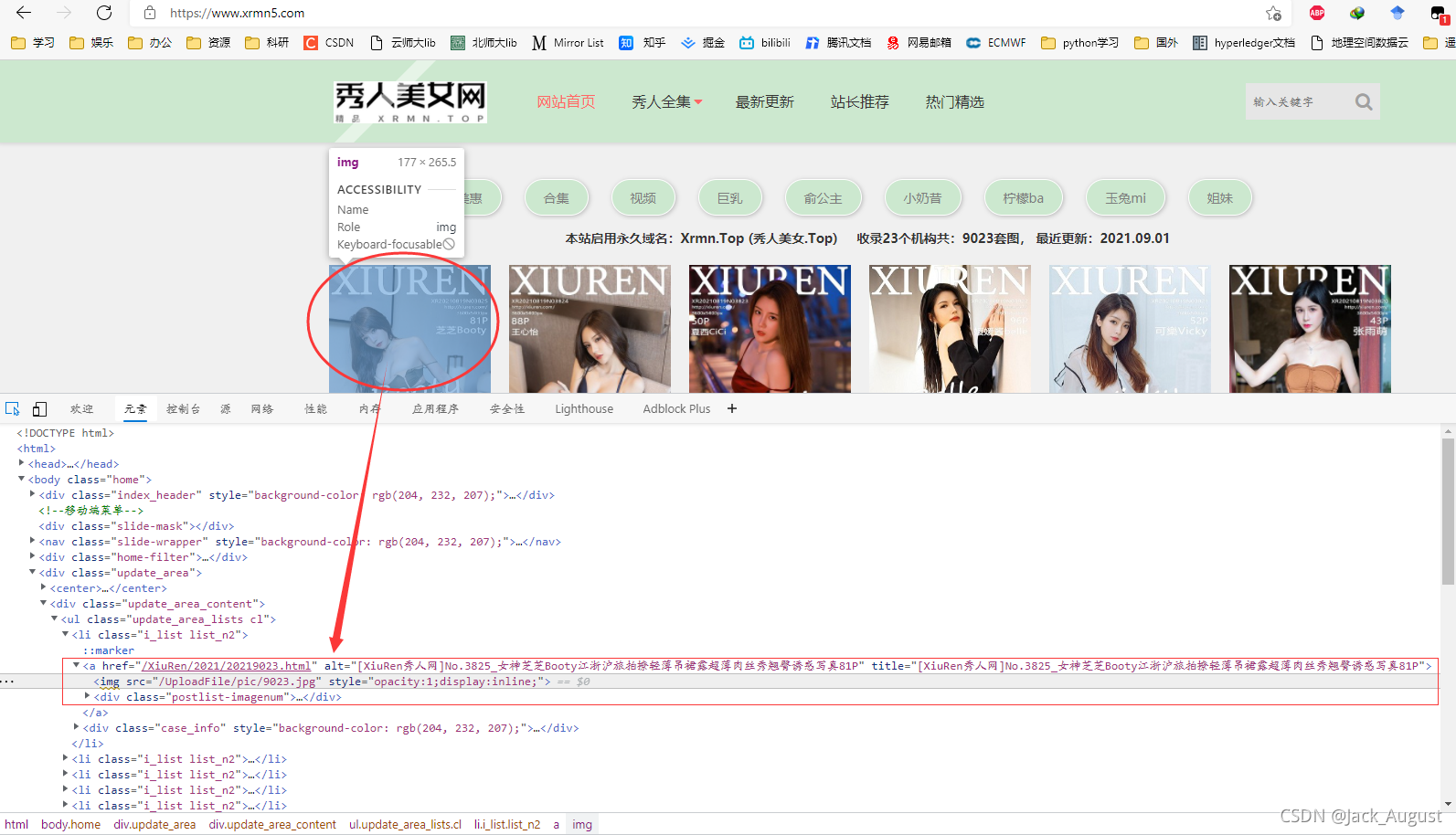
<a href="/XiuRen/2021/20219023.html" alt="[XiuRen秀人网]No.3825_女神芝芝Booty江浙沪旅拍撩轻薄吊裙露超薄肉丝秀翘臀诱惑写真81P" title="[XiuRen秀人网]No.3825_女神芝芝Booty江浙沪旅拍撩轻薄吊裙露超薄肉丝秀翘臀诱惑写真81P"><img src="/UploadFile/pic/9023.jpg" style="opacity:1;display:inline;">
<div class="postlist-imagenum"><span>芝芝</span></div></a>
再通过鼠标点击 <img src="/UploadFile/pic/9023.jpg"> 我们可以得到这样的信息:
这两个图表示啥呢?
对应网页结构
- 网页URL(即首页网址):https://www.xrmn5.com
- 首页重点——以上图小姐姐图片为例: src="/UploadFile/pic/9023.jpg"
- 图片对应网页地址:href="/XiuRen/2021/20219023.html"
- 图片对应标题:
[XiuRen秀人网]No.3825_女神芝芝Booty江浙沪旅拍撩轻薄吊裙露超薄肉丝秀翘臀诱惑写真81P(少儿不宜) - 图片对应人物:span>芝芝</span
细看图片信息
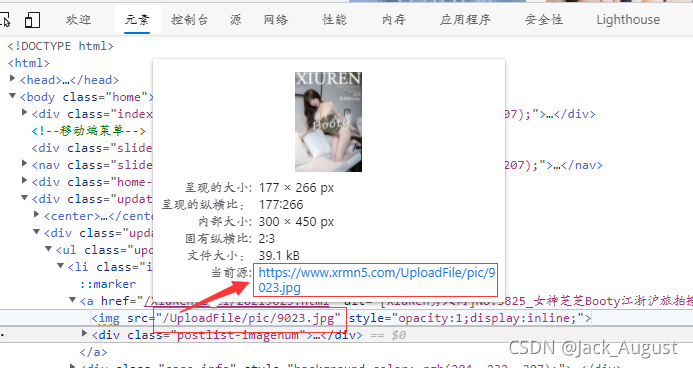
我们再仔细看看这张图,发现在标题下面还有时间和观看人数(貌似)

具体的网页代码如下
<div class="case_info" style="background-color: rgb(204, 232, 207);"><div class="meta-title">[XiuRen秀人网]No.3825_女神芝芝Booty江浙沪旅拍撩轻薄吊裙露超薄肉丝秀翘臀诱惑写真81P</div>
<div class="meta-post"><i class="fa fa-clock-o"></i>2021.09.01<span class="cx_like"><i class="fa fa-eye"></i>101</span></div></div>
对应网页结构
从这里可以得出:
- 图片创建时间:/i>2021.09.01<span
- 图片观看次数:/i>101</span
第二步:获取对应网页
开发环境:
Windows 10 64位专业版 + PyCharm + Python3.7 +
import os
import time
import requests
import re
其中:
- os 用于路径获取
- time 用于延时
- requests 用于获取网页信息
- re 用于解析
网页信息
从 第一步:查看网页结构 中可以知道:
-
首页图片链接地址为:首页链接+src中的链接,即:https://www.xrmn5.com/UploadFile/pic/9023.jpg (其实具体网页为:https://pic.xrmn5.com/Uploadfile/pic/9023.jpg ,但上面链接可用)
-
图片对应专辑名称为:
[XiuRen秀人网]No.3825_女神芝芝Booty江浙沪旅拍撩轻薄吊裙露超薄肉丝秀翘臀诱惑写真81P -
图片对应专辑网址为:首页链接+href中的链接,即:https://www.xrmn5.com/XiuRen/2021/20219023.html
-
图片对应人物:芝芝
-
图片创建时间:2021.09.01
python获取:
第一步:获取网页
通过 requests.get 我们可以获取到网页,由于有中文,进行 ‘utf-8’编码,最后转text进行展示(headers 内的是通过F12获取的当前网页headers信息),至此,首页信息获取至 Get_html 中
'''
第一步:请求网页
'''
import requests
# 头标签
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 Edg/92.0.902.84'
}
Get_url = requests.get('https://www.xrmn5.com/',headers=headers)
Get_url.encoding = 'utf-8'
# print(Get_url.text)
# print(Get_url.request.headers)
Get_html = Get_url.text
第二步:解析网页
最开始用的是re.findall(规则,数据)的方式,然后感觉太麻烦了,换成re.compile(规则,re.S).findall(数据)
重点是规则部分,urls 在这里是获取图片对应的 专辑网页信息(即href中的链接) 、标题信息和图片自身路径信息
inforName这里是获取人物信息和标题信息
likeNum这里是获取专辑对应的创建时间和观看人数
至此,相关信息已全部获取
'''
第二步:解析网页
'''
import re
# 正则表达式对应的为:
# (.*?):获取()内的所有
# \"(.*?)\" 用于匹配网页
# re.findall 用于获取()内的数据并每存为元组
urls = re.findall('<li class="i_list list_n2"><a href=\"(.*?)\" alt=(.*?) title=.*?><img src=\"(.*?)\"',Get_html)
patren1 = '<div class="postlist-imagenum"><span>(.*?)</span></div></a><div class="case_info"><div class="meta-title">\[.*?\](.*?)</a></div>'
patren2 = '<div class="meta-post"><i class="fa fa-clock-o"></i>(.*?)<span class="cx_like"><i class="fa fa-eye"></i>(.*?)</span>'
inforName = re.compile(patren1,re.S).findall(Get_html)
likeNum = re.compile(patren2,re.S).findall(Get_html)
第三步:获取首页封面图片
首先是指定图片存储目录:(这里是我自行设置的)
dir = r"D:/Let'sFunning/Picture/PythonGet/"
然后我做了个判断,观看人数超过500的写真专辑我才获取封面图片,将它保存在
dir 下的 人名 下的 时间名 下的 专辑名 文件夹中
os.makedirs() 用于创建文件夹
urls[i][2].split(’/’)[-1] 这里是把图片对应的路径如:/UploadFile/pic/9023.jpg 最后一截,即 9023.jpg 作为图片的名称进行保存
最后把图片路径与网页一拼接,就是图片的url,通过 requests.get() 直接获取后写入即可
'''
第三步:存储封面
'''
import os
import time
dir = r"D:/Let'sFunning/Picture/PythonGet/"
url = "https://pic.xrmn5.com"
# 创建目录:人名+时间+专辑名
num = len(likeNum)
for i in range(num):
if (int(likeNum[i][1]) > 500):
getImgDir=dir+str(inforName[i][0])+'/'+str(likeNum[i][0])+'/'+str(inforName[i][1]+'/')
# 创建对应目录
if not os.path.exists(getImgDir):
os.makedirs(getImgDir)
imgUrl = url+urls[i][2]
imgName = getImgDir+urls[i][2].split('/')[-1]
print(imgName)
time.sleep(1)
# 获取封面图片
Get_Img = requests.get(imgUrl, headers=headers)
with open(imgName,'wb') as f:
f.write(Get_Img.content)
# 进入具体网页
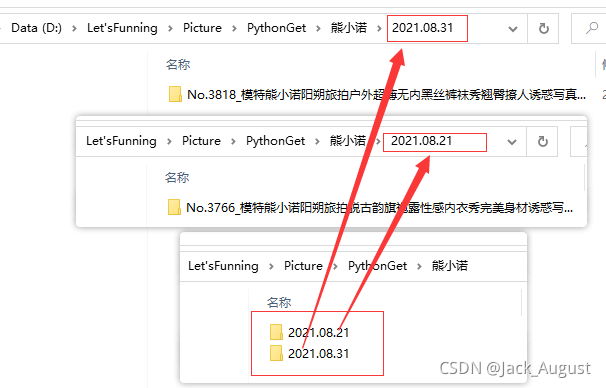
至此,首页观看人数超500的封面图片已保存至对应目录下
第三步:获取写真专辑图片
通过 第二步:获取对应网页,我们成功获取了首页的小姐姐图片,但是这些并不是爬虫,我们只在首页上爬了几张图片而已,我们应该深入到内部,去获取完整的写真图片。
目的
获取观看人数超500的写真套图,而不只是封面
思路
第一步:获取套图所在网页链接:
即:第二步:获取对应网页 的 网页信息
- 图片对应专辑网址为:首页链接+href中的链接,即:https://www.xrmn5.com/XiuRen/2021/20219023.html
第二步:分析写真套图对应网页:
同样的F12,我们可以知道,这一页一共有三张图片:
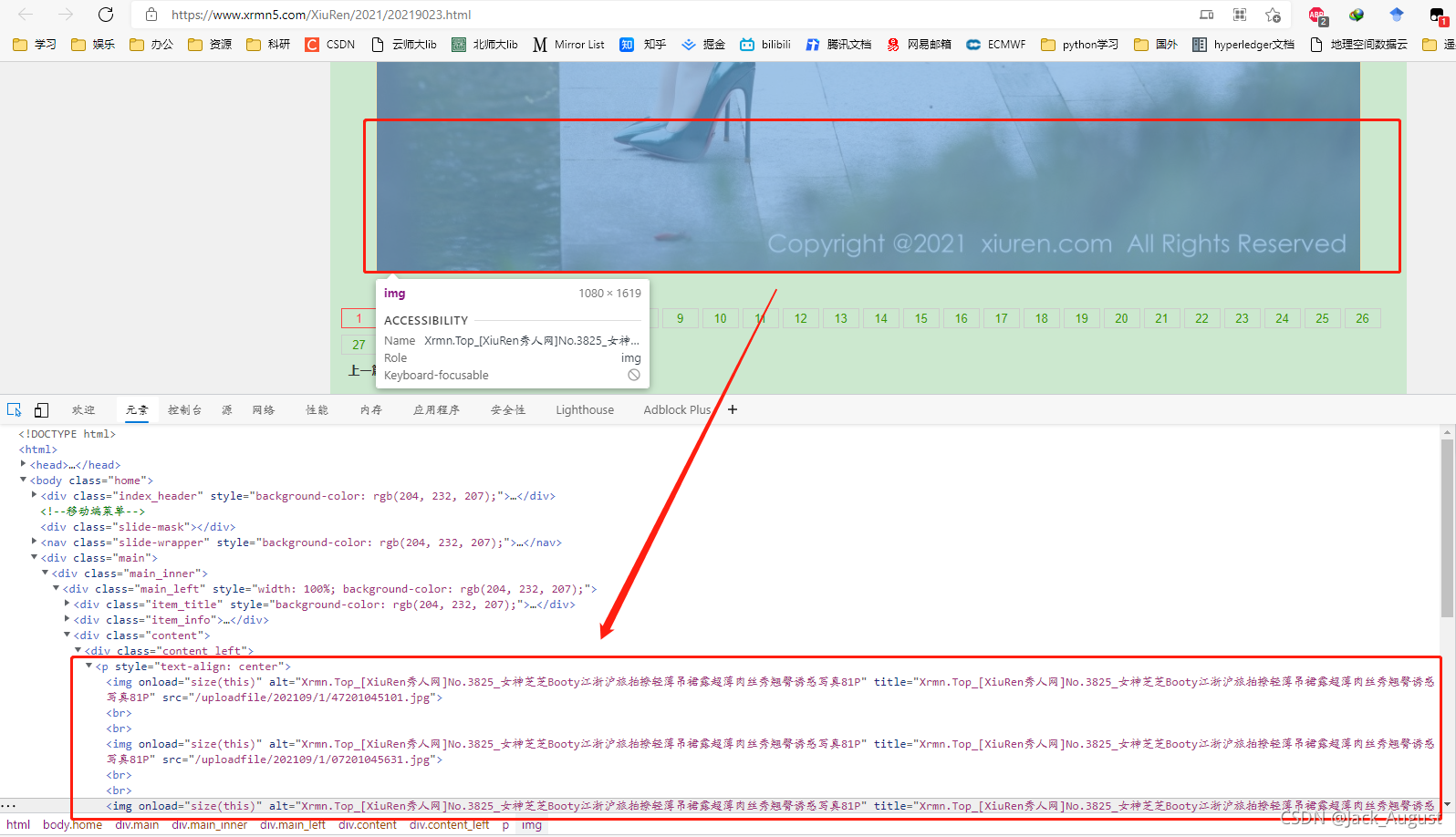
其图片对应代码如下:
<p style="text-align: center"><img onload="size(this)" alt="Xrmn.Top_[XiuRen秀人网]No.3825_女神芝芝Booty江浙沪旅拍撩轻薄吊裙露超薄肉丝秀翘臀诱惑写真81P" title="Xrmn.Top_[XiuRen秀人网]No.3825_女神芝芝Booty江浙沪旅拍撩轻薄吊裙露超薄肉丝秀翘臀诱惑写真81P" src="/uploadfile/202109/1/47201045101.jpg"><br>
<br>
<img onload="size(this)" alt="Xrmn.Top_[XiuRen秀人网]No.3825_女神芝芝Booty江浙沪旅拍撩轻薄吊裙露超薄肉丝秀翘臀诱惑写真81P" title="Xrmn.Top_[XiuRen秀人网]No.3825_女神芝芝Booty江浙沪旅拍撩轻薄吊裙露超薄肉丝秀翘臀诱惑写真81P" src="/uploadfile/202109/1/07201045631.jpg"><br>
<br>
<img onload="size(this)" alt="Xrmn.Top_[XiuRen秀人网]No.3825_女神芝芝Booty江浙沪旅拍撩轻薄吊裙露超薄肉丝秀翘臀诱惑写真81P" title="Xrmn.Top_[XiuRen秀人网]No.3825_女神芝芝Booty江浙沪旅拍撩轻薄吊裙露超薄肉丝秀翘臀诱惑写真81P" src="/uploadfile/202109/1/16201045377.jpg"><br>
<br>
</p>
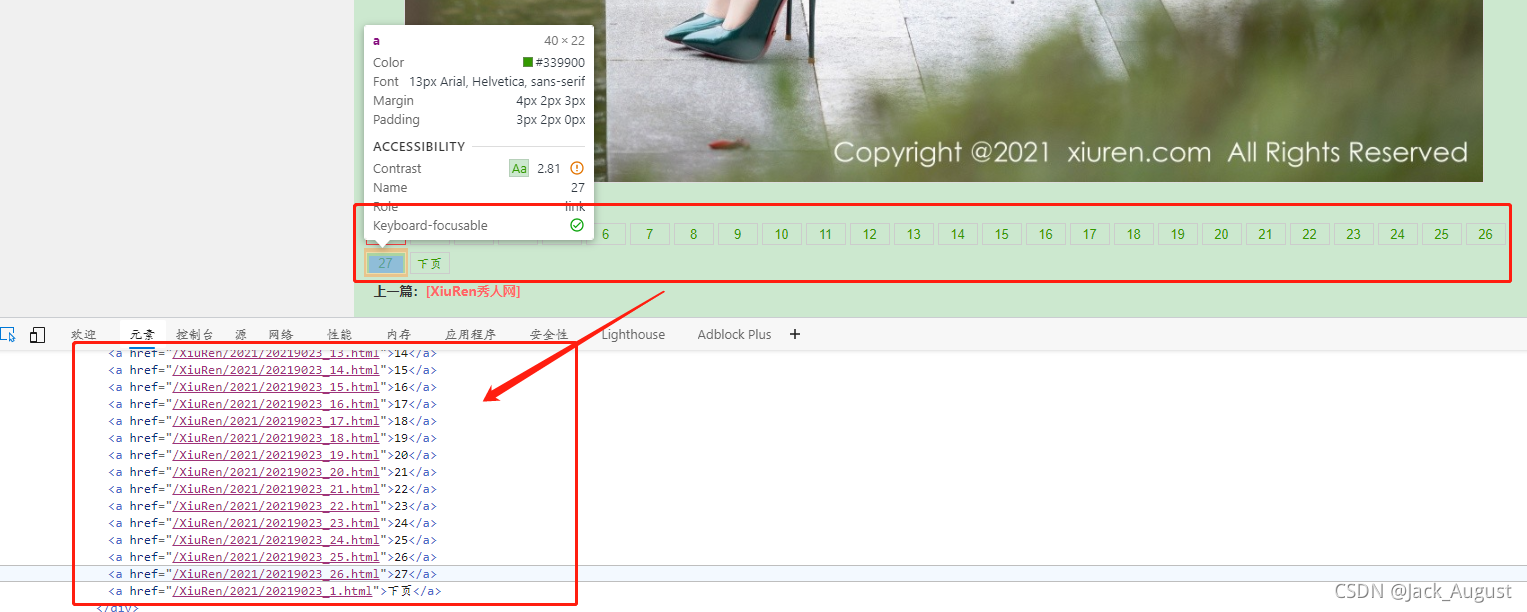
对应页面代码如下:
<div class="page"><a href="/XiuRen/2021/20219023.html" class="current">1</a><a href="/XiuRen/2021/20219023_1.html">2</a><a href="/XiuRen/2021/20219023_2.html">3</a><a href="/XiuRen/2021/20219023_3.html">4</a><a href="/XiuRen/2021/20219023_4.html">5</a><a href="/XiuRen/2021/20219023_5.html">6</a><a href="/XiuRen/2021/20219023_6.html">7</a><a href="/XiuRen/2021/20219023_7.html">8</a><a href="/XiuRen/2021/20219023_8.html">9</a><a href="/XiuRen/2021/20219023_9.html">10</a><a href="/XiuRen/2021/20219023_10.html">11</a><a href="/XiuRen/2021/20219023_11.html">12</a><a href="/XiuRen/2021/20219023_12.html">13</a><a href="/XiuRen/2021/20219023_13.html">14</a><a href="/XiuRen/2021/20219023_14.html">15</a><a href="/XiuRen/2021/20219023_15.html">16</a><a href="/XiuRen/2021/20219023_16.html">17</a><a href="/XiuRen/2021/20219023_17.html">18</a><a href="/XiuRen/2021/20219023_18.html">19</a><a href="/XiuRen/2021/20219023_19.html">20</a><a href="/XiuRen/2021/20219023_20.html">21</a><a href="/XiuRen/2021/20219023_21.html">22</a><a href="/XiuRen/2021/20219023_22.html">23</a><a href="/XiuRen/2021/20219023_23.html">24</a><a href="/XiuRen/2021/20219023_24.html">25</a><a href="/XiuRen/2021/20219023_25.html">26</a><a href="/XiuRen/2021/20219023_26.html">27</a><a href="/XiuRen/2021/20219023_1.html">下页</a></div>
第三步:写真套图对应网页信息:
从上面两张图和对应代码,我们可以知道,
- 这个套图一共有27页 >27</a
- 每一页有三张图片 src="/uploadfile/202109/1/47201045101.jpg">、src="/uploadfile/202109/1/07201045631.jpg">、src="/uploadfile/202109/1/16201045377.jpg">
- 除此页外的剩下页对应链接均有: 如href="/XiuRen/2021/20219023_2.html">
代码实现
思路很简单,在原有基础上深入一层至对应网页再循环获取即可
前面部分类似
前面部分类似,把首页扔了个变量:WebURL 然后添加了新的规则 patren3 用于获取套图的三张图片信息。
'''
第一步:请求网页
'''
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 Edg/92.0.902.84'
}
WebURL = "https://www.xrmn5.com/"
Get_url = requests.get(WebURL,headers=headers)
# print(Get_url.text)
# print(Get_url.request.headers)
Get_html = Get_url.text
'''
第二步:解析网页
'''
import re
# 正则表达式对应的为:
# (.*?):获取()内的所有
# \"(.*?)\" 用于匹配网页
# re.findall 用于获取()内的数据并每存为元组
urls = re.findall('<li class="i_list list_n2"><a href=\"(.*?)\" alt=(.*?) title=.*?><img src=\"(.*?)\"',Get_html)
patren1 = '<div class="postlist-imagenum"><span>(.*?)</span></div></a><div class="case_info"><div class="meta-title">\[.*?\](.*?)</a></div>'
patren2 = '<div class="meta-post"><i class="fa fa-clock-o"></i>(.*?)<span class="cx_like"><i class="fa fa-eye"></i>(.*?)</span>'
inforName = re.compile(patren1,re.S).findall(Get_html)
likeNum = re.compile(patren2,re.S).findall(Get_html)
# 针对套图所在网页的图片链接信息,添加新的解析规则
# <img οnlοad="size(this)" alt=.*? title=.*? src="/uploadfile/202109/1/07201045631.jpg" />
patren3 = '<img οnlοad=.*? alt=.*? title=.*? src=\"(.*?)\" />'
'''
第三步:进一步解析网页
'''
'''
第三步:存储封面
'''
import os
import time
dir = r"D:/Let'sFunning/Picture/PythonGet/"
url = "https://pic.xrmn5.com"
后面进行循环获取
这里主要思路如下:
- 进入具体网页中,即再次 requests.get()
- 解析此时获取的网页,将套图对应的所有页面路径存入 AllPage 中 (注意 我正则表达式存在一点问题,把最后一个链接:即 a href="/XiuRen/2021/20219023_1.html">下页</a 这个也获取到了,所以做了个break跳出,导致套图的最后一页图片是无法获取到的,即最终会少3张(if放for循环后面就行,懒得改了)
- 然后就对每一页的图片进行循环获取,就是把每一页的图片链接扔给==GetPageImg ,再进行requests.get()==保存完事了
# 创建目录:人名+时间+专辑名
num = len(likeNum)
for i in range(num):
if (int(likeNum[i][1]) > 500):
getImgDir=dir+str(inforName[i][0])+'/'+str(likeNum[i][0])+'/'+str(inforName[i][1]+'/')
# 创建对应目录
if not os.path.exists(getImgDir):
os.makedirs(getImgDir)
imgUrl = url+urls[i][2]
imgName = getImgDir+urls[i][2].split('/')[-1]
print(imgName)
time.sleep(1)
# 获取封面图片
Get_Img = requests.get(imgUrl, headers=headers)
with open(imgName,'wb') as f:
f.write(Get_Img.content)
# 进入具体网页
IntoPageUrl = WebURL + urls[i][0]
Get_InPage = requests.get(IntoPageUrl, headers=headers)
Get_InPage.encoding = 'utf-8'
Get_InPagehtml = Get_InPage.text
AllPage = re.findall('</a><a href=\"(.*?)\">([0-9]*)', Get_InPagehtml)
for k in range(len(AllPage)):
if k == len(AllPage) - 1:
break
else:
imgPageUrl = re.compile(patren3, re.S).findall(Get_InPagehtml)
PageNum = len(imgPageUrl)
# 循环获取并保存图片
for l in range(PageNum):
GetPageImg = url+imgPageUrl[l]
print(GetPageImg)
PageImgeName = getImgDir+imgPageUrl[l].split('/')[-1]
print(PageImgeName)
time.sleep(1)
# 获取内部图片
Get_PImg = requests.get(GetPageImg, headers=headers)
with open(PageImgeName, 'wb') as f:
f.write(Get_PImg.content)
# 继续下一页获取图片
NewPaperUrl = WebURL + AllPage[k][0]
time.sleep(1)
Get_InPage = requests.get(NewPaperUrl, headers=headers)
Get_InPage.encoding = 'utf-8'
Get_InPagehtml = Get_InPage.text
至此,首页观看人数超500的套图已保存至对应目录下
第四步:获取全站写真专辑图片
问题
OK,现在我们是已经获取到所有的套图了,但是我们发现,我们只是获取到首页的观看人数超500的套图,但实际上的套图远不止一页,因此我们需要找到网站对应的所有套图:
于是我们发现:如果我们进入网页为https://www.xrmn5.com/XiuRen/, 则可以看到有:128 页

这里才是我们要爬的对象。
目的
获取 https://www.xrmn5.com/XiuRen/ 中所有的图片
思路
思路类似,只不过在获取首页之前,先获取此网页的数据,然后在循环内进行获取即可
代码实现
第一步:获取https://www.xrmn5.com/XiuRen/ 的所有页数
具体来说,就是加了个规则patrenForPageNum, 再把当前页所能到达的数量获取出来:这里是匹配了个数字并返回
PageNum = "".join(list(filter(str.isdigit, temp)))
再进行格式拼接生成所有网页URL并保存到==GetAllPage ==中
import os
import time
dir = r"D:/Let'sFunning/Picture/PythonGet/"
url = "https://pic.xrmn5.com"
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 Edg/92.0.902.84'
}
URL = "https://www.xrmn5.com/XiuRen/"
WebURL = "https://www.xrmn5.com/"
Get_url = requests.get(URL,headers=headers)
Get_url.encoding = 'utf-8'
Get_html = Get_url.text
print(Get_html)
import re
patrenForPageNum = '</a><a href=\"(.*?)\">'
Get_PageNum = re.compile(patrenForPageNum,re.S).findall(Get_html)
temp = str(Get_PageNum[len(Get_PageNum)-1])
PageNum = "".join(list(filter(str.isdigit, temp)))
print(temp)
print(PageNum)
# 获取所有网页,存入AllPage中
AllPageTemp = []
GetAllPage = ()
for i in range(int(PageNum)):
if i > 0:
AllPageTemp.append(WebURL+"/XiuRen/index"+str(i+1)+".html")
GetAllPage += tuple(AllPageTemp)
第二步:在PageNum中进行循环获取图片即可
这里其实也有点问题,就是第128页的数据是拿不到的,这里有点逻辑缺陷,但基本上这个网页 https://www.xrmn5.com/XiuRen/ 内的所有超过500观看的套图都能爬到
for pagenum in range(int(PageNum)):
urls = re.findall('<li class="i_list list_n2"><a href=\"(.*?)\" alt=(.*?) title=.*?><img class="waitpic" src=\"(.*?)\"', Get_html)
patren1 = '<div class="postlist-imagenum"><span>(.*?)</span></div></a><div class="case_info"><div class="meta-title">\[.*?\](.*?)</a></div>'
patren2 = '<div class="meta-post"><i class="fa fa-clock-o"></i>(.*?)<span class="cx_like"><i class="fa fa-eye"></i>(.*?)</span>'
inforName = re.compile(patren1, re.S).findall(Get_html)
likeNum = re.compile(patren2, re.S).findall(Get_html)
print(urls)
print(inforName)
print(likeNum)
num = len(likeNum)
patren3 = '<img οnlοad=.*? alt=.*? title=.*? src=\"(.*?)\" />'
for i in range(num):
if (int(likeNum[i][1]) > 500):
getImgDir = dir + str(inforName[i][0]) + '/' + str(likeNum[i][0]) + '/' + str(inforName[i][1] + '/')
# 创建对应目录
if not os.path.exists(getImgDir):
os.makedirs(getImgDir)
imgUrl = url + urls[i][2]
imgName = getImgDir + urls[i][2].split('/')[-1]
print(imgName)
time.sleep(1)
# 获取封面图片
Get_Img = requests.get(imgUrl, headers=headers)
with open(imgName, 'wb') as f:
f.write(Get_Img.content)
# 进入具体网页
IntoPageUrl = WebURL + urls[i][0]
Get_InPage = requests.get(IntoPageUrl, headers=headers)
Get_InPage.encoding = 'utf-8'
Get_InPagehtml = Get_InPage.text
AllPage = re.findall('</a><a href=\"(.*?)\">([0-9]*)', Get_InPagehtml)
for k in range(len(AllPage)):
imgPageUrl = re.compile(patren3, re.S).findall(Get_InPagehtml)
PageNum = len(imgPageUrl)
# 循环获取并保存图片
for l in range(PageNum):
GetPageImg = url + imgPageUrl[l]
print(GetPageImg)
PageImgeName = getImgDir + imgPageUrl[l].split('/')[-1]
print(PageImgeName)
time.sleep(1)
# 获取封面图片
Get_PImg = requests.get(GetPageImg, headers=headers)
with open(PageImgeName, 'wb') as f:
f.write(Get_PImg.content)
if k == len(AllPage) - 1:
break
# 继续下一页获取图片
NewPaperUrl = WebURL + AllPage[k][0]
time.sleep(1)
Get_InPage = requests.get(NewPaperUrl, headers=headers)
Get_InPage.encoding = 'utf-8'
Get_InPagehtml = Get_InPage.text
Get_url = requests.get(GetAllPage[pagenum],headers=headers)
Get_url.encoding = 'utf-8'
Get_html = Get_url.text
君欲善其事,必先利其器
结果


Hello World!

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

{kind=link}
所有评论(0)