pytorch的padding怎么使用?支持哪些padding方式方法?padding有什么意义?
pytorch的padding怎么使用?支持哪些padding方式方法?padding有什么意义?前言pytorch支持哪些padding?1. zeros(常量填充)2. reflect(反射填充)3. replicate(复制填充)4. circular(循环填充)总结前言搭建深度学习模型,必不可少使用卷积,卷积中有一个参数padding需要理解且应该掌握选择哪种方式进行padding,本文对
pytorch的padding怎么使用?支持哪些padding方式方法?padding有什么意义?
前言
相关代码请关注公众号:CV市场,回复padding获取,感谢支持!
搭建深度学习模型,必不可少使用卷积,卷积中有一个参数padding需要理解且应该掌握选择哪种方式进行padding,本文对pytorch中支持的四种padding进行详细描述。
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
Conv2d的具体参数说明,参见我的另一篇博客pytorch的Conv2d参数详解
为了更具体的、更舒服地看pytorch的padding进行了哪些操作,顺着源码可以看出Conv2d对你指定的padding_mode判断,如果是默认的zeros ,那么直接在你指定的padding个行和列上填充0。 如果你指定的padding_mode不是zeros,那么调用了F.pad进行不同方法的填充。详细对比不同之处如下。
如果你指定的padding_mode不是zeros,那么调用了F.pad进行不同方法的填充。详细对比不同之处如下。
pytorch支持哪些padding?
padding_mode可选择四种padding方法:zeros(常量填充)(默认0填充)、reflect(反射填充)、replicate(复制填充)、circular(循环填充)。
首先我们先定义卷积的输入,一张3通道,高和宽都为4的输入:
x = torch.reshape(torch.range(1,48),(1,3,4,4))
print(x.size())
print(x)
打印结果如下:
torch.Size([1, 3, 4, 4])
tensor([[[[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.],
[13., 14., 15., 16.]],
[[17., 18., 19., 20.],
[21., 22., 23., 24.],
[25., 26., 27., 28.],
[29., 30., 31., 32.]],
[[33., 34., 35., 36.],
[37., 38., 39., 40.],
[41., 42., 43., 44.],
[45., 46., 47., 48.]]]])
接下来对这个输入进行padding实验。
1. zeros(常量填充)
常量填充是最好理解的,默认情况是使用0填充,可选择整形int或者tuple元组。
zero_padding = torch.nn.Conv2d(3,3,1,1,padding=1,padding_mode='zeros',bias=False)
# 为了只得到padding的结果对比,对卷积核的取值都设置为1
zero_padding.weight = torch.nn.Parameter(torch.ones(3,3,1,1))
out = zero_padding(x)
print(out.size())
print(out)
这里我们使用了输入维度为3,输出维度为3,步长为1,卷积核为1.,查看并对比上面x的定义:
torch.Size([1, 3, 6, 6])
tensor([[[[ 0., 0., 0., 0., 0., 0.],
[ 0., 51., 54., 57., 60., 0.],
[ 0., 63., 66., 69., 72., 0.],
[ 0., 75., 78., 81., 84., 0.],
[ 0., 87., 90., 93., 96., 0.],
[ 0., 0., 0., 0., 0., 0.]],
[[ 0., 0., 0., 0., 0., 0.],
[ 0., 51., 54., 57., 60., 0.],
[ 0., 63., 66., 69., 72., 0.],
[ 0., 75., 78., 81., 84., 0.],
[ 0., 87., 90., 93., 96., 0.],
[ 0., 0., 0., 0., 0., 0.]],
[[ 0., 0., 0., 0., 0., 0.],
[ 0., 51., 54., 57., 60., 0.],
[ 0., 63., 66., 69., 72., 0.],
[ 0., 75., 78., 81., 84., 0.],
[ 0., 87., 90., 93., 96., 0.],
[ 0., 0., 0., 0., 0., 0.]]]], grad_fn=<ThnnConv2DBackward>)
很明显,在3个通道的输入中的每一个通道的每一行和列都进行了0填充。
当指定padding=2时,输出如下:
torch.Size([1, 3, 8, 8])
tensor([[[[ 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 51., 54., 57., 60., 0., 0.],
[ 0., 0., 63., 66., 69., 72., 0., 0.],
[ 0., 0., 75., 78., 81., 84., 0., 0.],
[ 0., 0., 87., 90., 93., 96., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0.]],
[[ 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 51., 54., 57., 60., 0., 0.],
[ 0., 0., 63., 66., 69., 72., 0., 0.],
[ 0., 0., 75., 78., 81., 84., 0., 0.],
[ 0., 0., 87., 90., 93., 96., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0.]],
[[ 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 51., 54., 57., 60., 0., 0.],
[ 0., 0., 63., 66., 69., 72., 0., 0.],
[ 0., 0., 75., 78., 81., 84., 0., 0.],
[ 0., 0., 87., 90., 93., 96., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0.]]]],
grad_fn=<ThnnConv2DBackward>)
2. reflect(反射填充)
如果你指定paddding_mode=zero以外的其他填充模式,那么顺着pytorch的源码,可以看出其将输入input封装了一层F.pad。 F.pad的第一个输入参数是输入的特征图,第二个参数是一个元组,第三个参数是padding方式。即使你输入的padding=1, self._reversed_padding_repeated_twice会将padding格式变成2的倍数大小的整形元组。例如:padding=1,那么self._reversed_padding_repeated_twice就会等于(1,1);如果padding=(2,2),那么self._reversed_padding_repeated_twice就会等于(2, 2, 2, 2)。
F.pad的第一个输入参数是输入的特征图,第二个参数是一个元组,第三个参数是padding方式。即使你输入的padding=1, self._reversed_padding_repeated_twice会将padding格式变成2的倍数大小的整形元组。例如:padding=1,那么self._reversed_padding_repeated_twice就会等于(1,1);如果padding=(2,2),那么self._reversed_padding_repeated_twice就会等于(2, 2, 2, 2)。
reflect、replicate和circular会分别调用 torch._C._nn.reflection_pad2d、torch._C._nn.replication_pad2d和_pad_circular。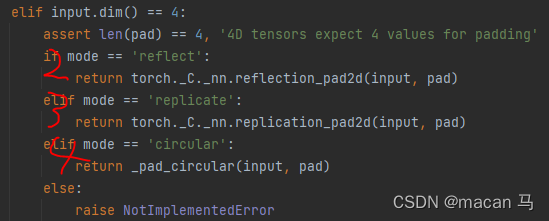
所以此小节看torch._C._nn.reflection_pad2d就可以得出reflect(反射填充)的规律
输入还是那个输入:
x = torch.reshape(torch.range(1,48),(1, 3, 4, 4))
print(x.size())
print(x)
进行反射填充:
x = torch._C._nn.reflection_pad2d(x, (1, 1, 1, 1)) # Conv2d指定padding=1时,reflection_pad2d的第二个参数就会转换成(1, 1, 1, 1)
print(x.size())
print(x)
结果如下,蓝色矩形框内为原始数据,蓝色矩形框外为padding结果。很明显,reflect就是以矩阵中的某个行或列为轴,中心对称的padding到最外围。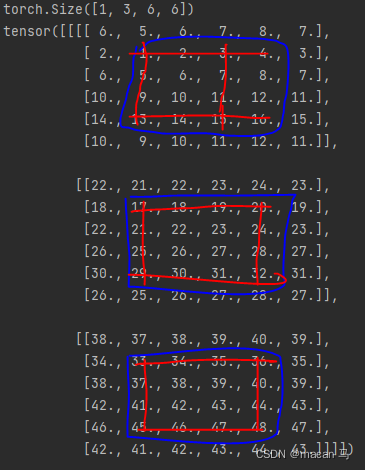
3. replicate(复制填充)
输入还是那个输入,就不多说明了。
进行replicate(复制填充):
x = torch._C._nn.replication_pad2d(x, (1, 1, 1, 1)) # Conv2d指定padding=1时,replication_pad2d的第二个参数就会转换成(1, 1, 1, 1)
print(x.size())
print(x)
结果如下:
蓝色为原始矩阵,红色为padding后的结果。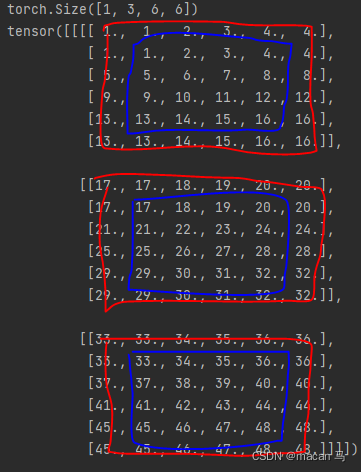
所以很明显,replicate将矩阵的边缘复制并填充到矩阵的外围。
4. circular(循环填充)
发现_pad_circular不能直接调用,那么我们就用zero填充方式时的方法来观察circular的具体规律。
输入:
x = torch.reshape(torch.range(1,48),(1, 3, 4, 4))
print(x.size())
print(x)
torch.Size([1, 3, 4, 4])
tensor([[[[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.],
[13., 14., 15., 16.]],
[[17., 18., 19., 20.],
[21., 22., 23., 24.],
[25., 26., 27., 28.],
[29., 30., 31., 32.]],
[[33., 34., 35., 36.],
[37., 38., 39., 40.],
[41., 42., 43., 44.],
[45., 46., 47., 48.]]]])
进行circular(循环填充),先看padding=1的:
conv_circular = torch.nn.Conv2d(3,3,1,1,padding=1,padding_mode='circular',bias=False)
# 将卷积核的权重设置为1,这样可使卷积后的输出即为填充后的输入矩阵
conv_circular.weight = torch.nn.Parameter(torch.ones(3,3,1,1))
out = conv_circular(x)
print(out.size())
print(out)
结果: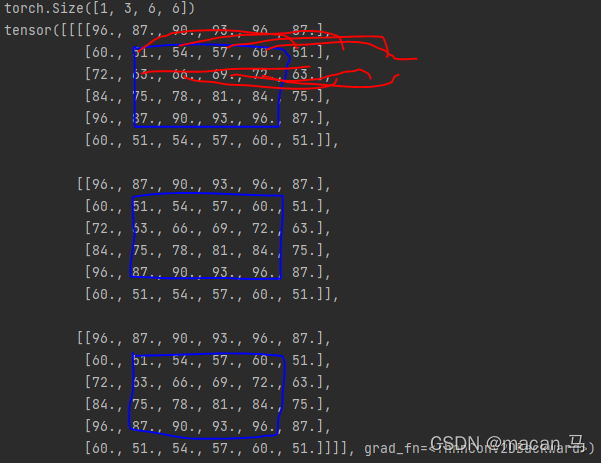
padding=1时现象好像不明显,所以下面时padding=4的,也就是补4行:
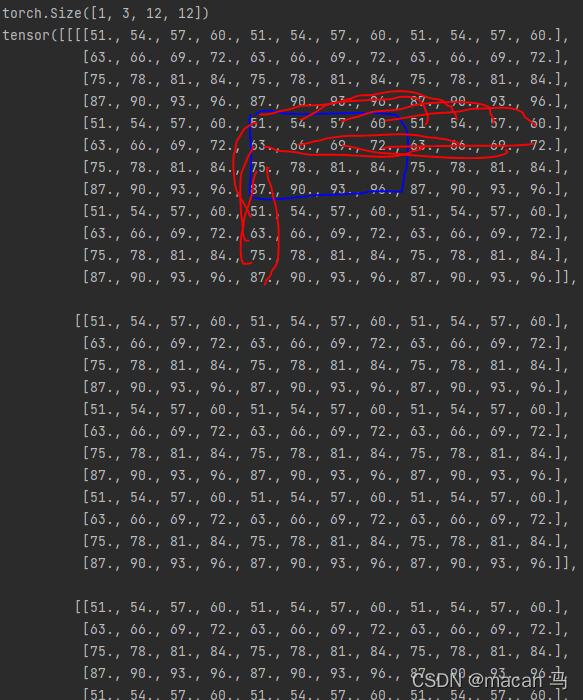
从上到下进行无限的重复延伸
总结
- zeros(常量填充),默认情况是使用0填充,可选择整形int或者tuple元组
- reflect(反射填充),以矩阵中的某个行或列为轴,中心对称的padding到最外围。
- replicate(复制填充),replicate将矩阵的边缘复制并填充到矩阵的外围
- circular(循环填充),从上到下进行无限的重复延伸
相关代码请关注公众号:CV市场,回复padding获取,感谢支持!

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)