python爬虫-视频爬虫(1)
python爬虫-视频爬虫(1)一、视频爬虫介绍本篇文章主要是针对直接可以找到完整视频的链接(可能需要拼接成完整链接)进行下载的那一类视频爬虫二、视频爬虫步骤和所有的爬虫一样,首先熟悉你需要爬虫的网页,从中找到我们需要下载的视频的链接、或者可以拼接成视频的下载链接,最后才是把这个过程用python代码来实现自动化。三、爬虫代码的实现以【好看视频】网址为例和图片的爬虫不同,图片的链接都是可以在网页的
python爬虫-视频爬虫(1)
一、视频爬虫介绍
本篇文章主要是针对直接可以找到完整视频的链接(可能需要拼接成完整链接)进行下载的那一类视频爬虫
二、视频爬虫步骤
和所有的爬虫一样,首先熟悉你需要爬虫的网页,从中找到我们需要下载的视频的链接、或者可以拼接成视频的下载链接,最后才是把这个过程用python代码来实现自动化。
三、爬虫代码的实现
以【好看视频】网址为例
和图片的爬虫不同,图片的链接都是可以在网页的源码中找到的,而视频需要你打开F12刷新网页查看接口请求,从接口的响应里面获取数据;
让我们先打开视频,然后再打开F12查看接口请求,视频一定要播放一会儿或者正在播放着,方便于你找寻接口;
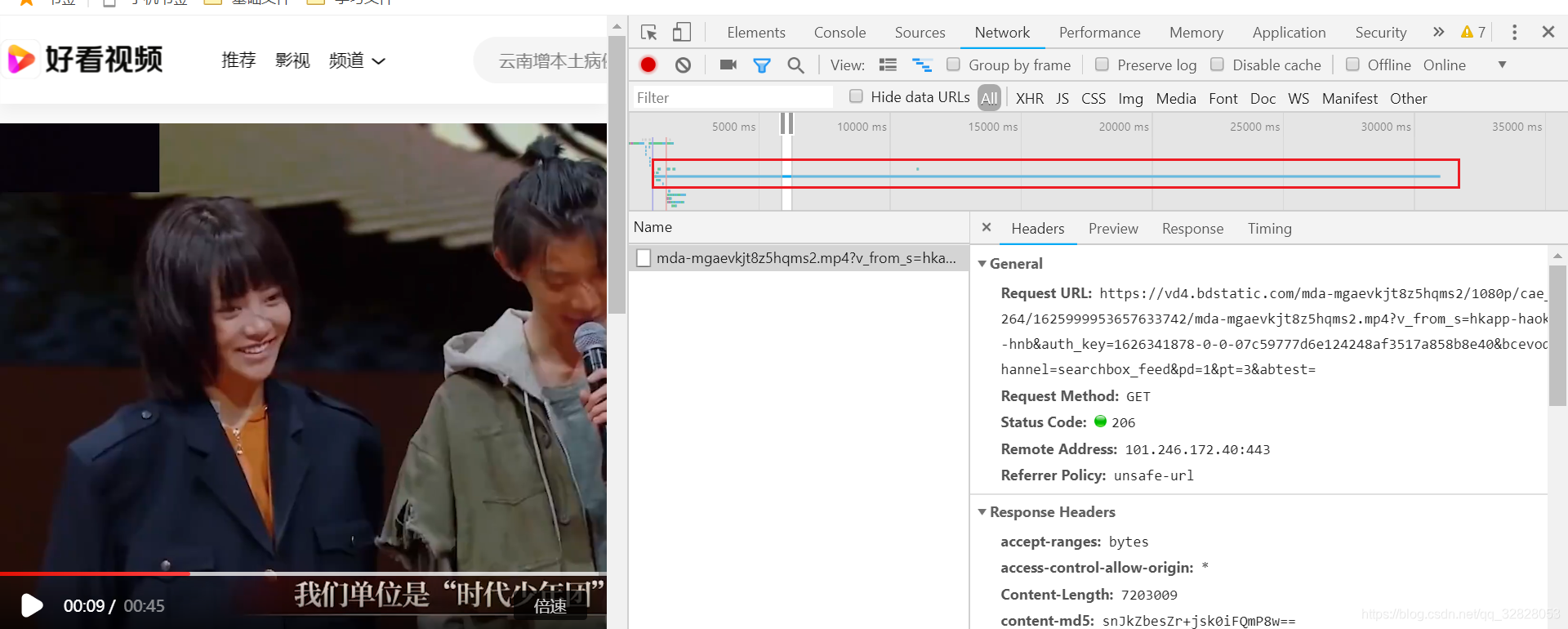
我们会看到在所有的接口请求中有一段接口请求时间会很长持续性请求,在这个网页中会有什么样的接口做这个操作呢,毋容置疑肯定是视频的播放请求接口,让我们选中看一下
就是图中的那个接口,然后让我们把这个接口单独复制出去请求一下看看

就是它,是不是发现和播放的视频一样,没错,我们找到这个视频的链接了,可以直接通过这个链接进行下载

很好,说明只要我们获取到这个视频的url就可以直接执行下载操作了
但是视频的url我们又不知道总不能每次打开一下这个视频然后从接口里面获取吧,那岂不是疯了,这样我们看一下视频从哪里来的,看看他的上游是不是获取到我们需要的信息;
他的上游是哪个?那肯定是我们跳转过来的列表啦
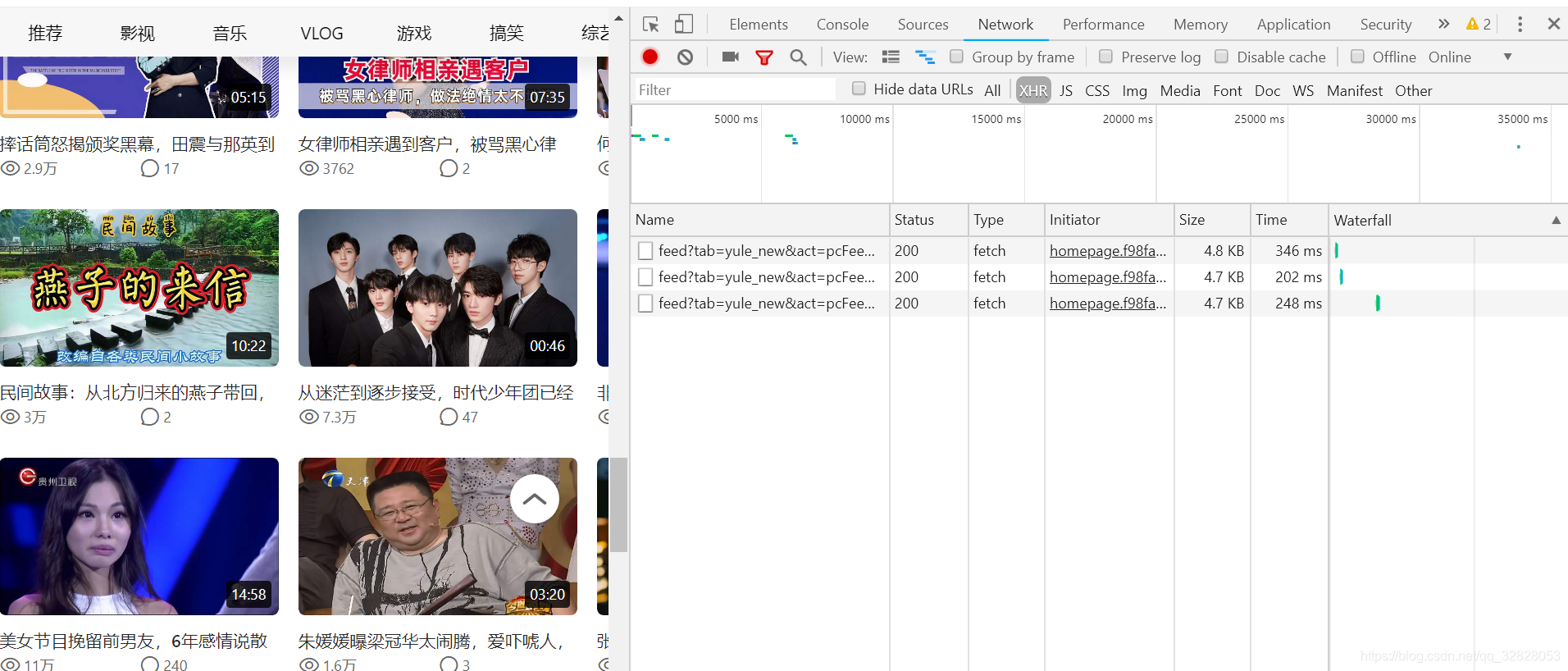
同样打开F12你下滑一下就会发现页面多了一些视频同时多了一个接口请求,这是请求就是用来获取视频的列表的,让我们看一下请求里面返回的什么吧

是不是眼熟,这不就是我们看的视频标题吗,很好在向下看,
**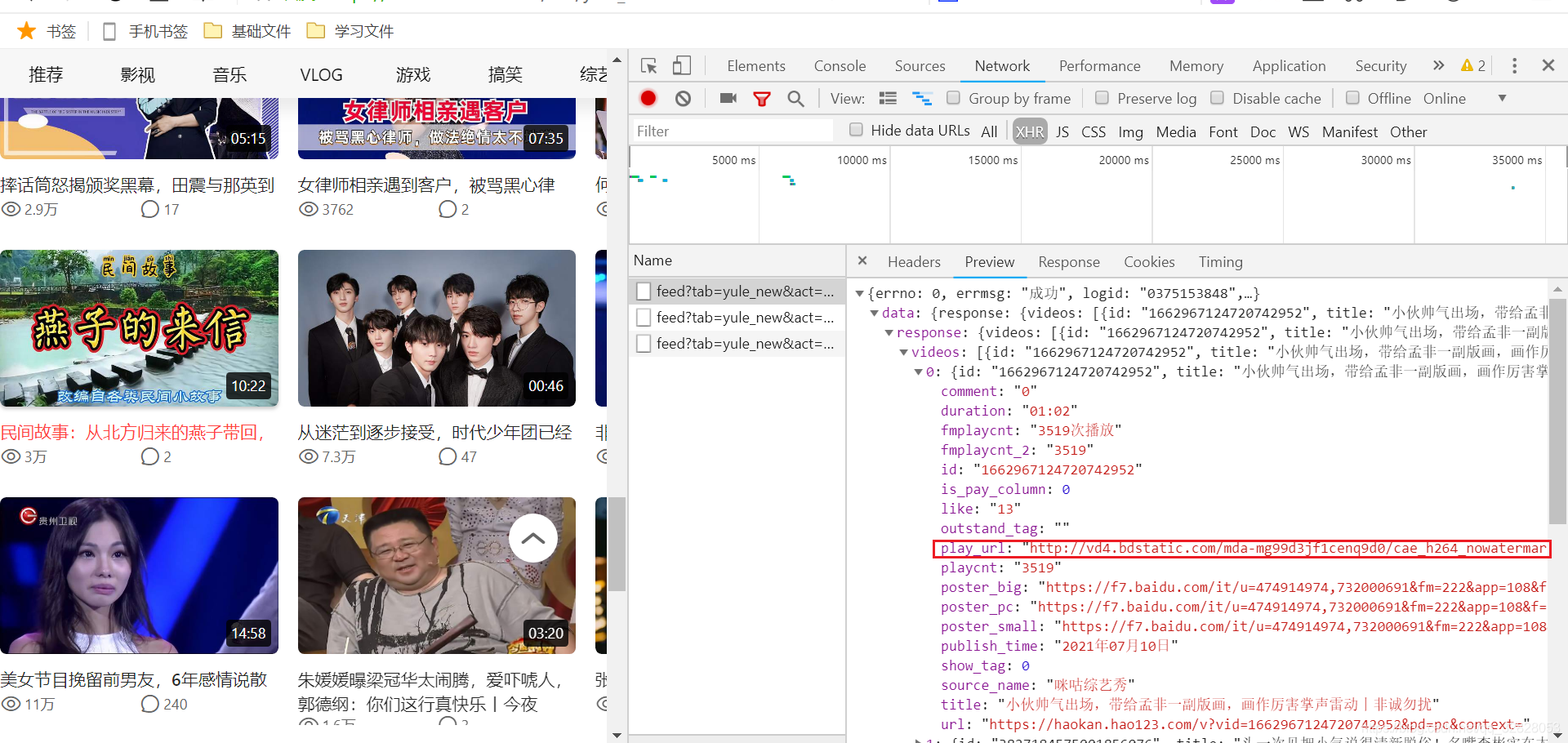
**
看我们发现了啥play_url,播放的url,看着挺像的,话不多说复制链接打开看一下
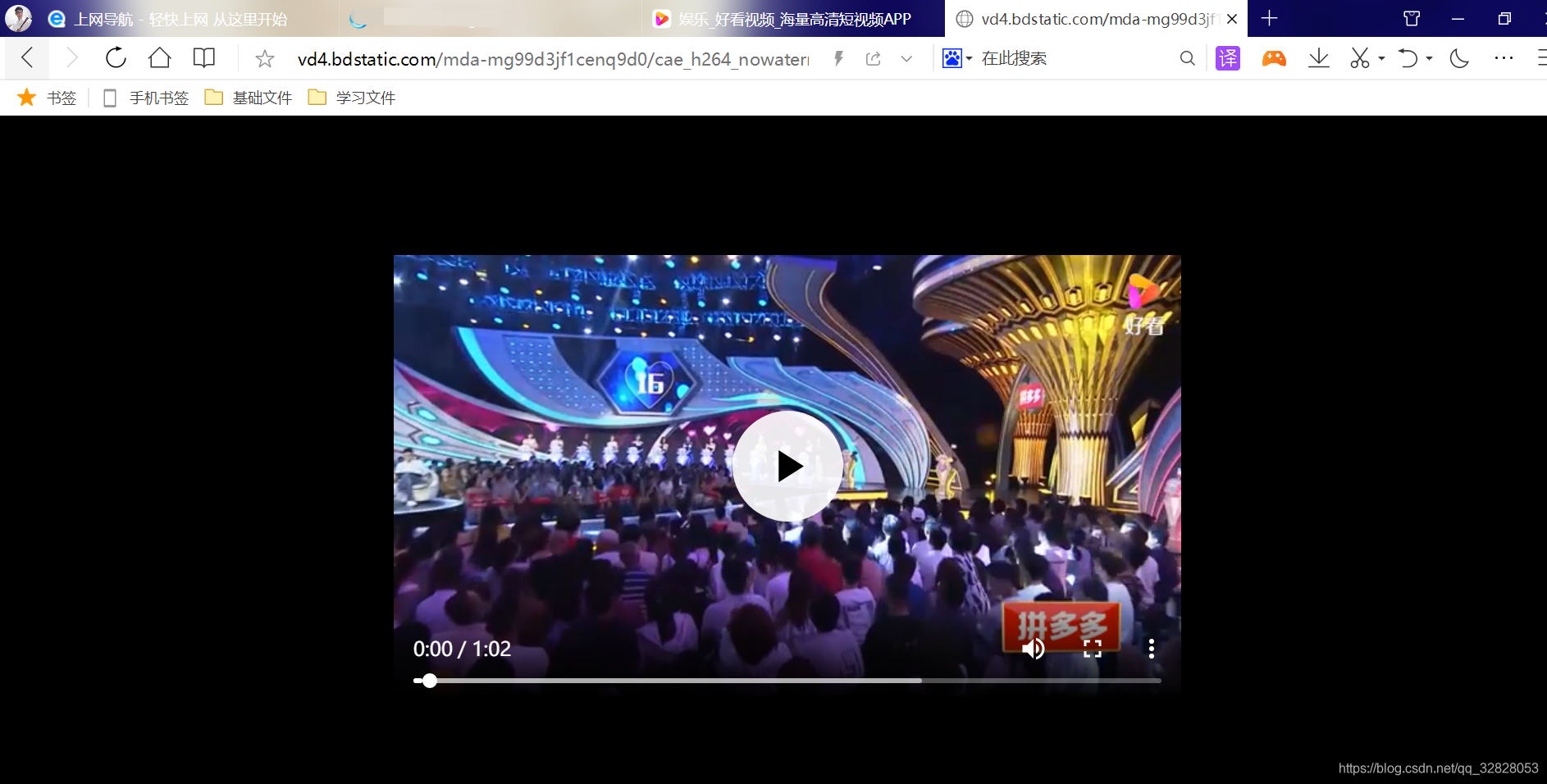
芜湖!!!这不就是我们需要的吗,极其的顺利,也就是说我们只需要请求列表的url就可以获取视频的相关信息并进行下载操作,看到这里就非常开心啦;让我们把代码撸起来;
import requests
#下载的视频是整个视频,不是需要拼接的那一种
# 传入下载的列表URL和文件的保存文件夹path 下载视频
def get_vi(url,path):
# 获取网页的返回信息
respons = requests.get(url).json()
# 在响应里面获取需要的数据保存到列表
vi_url = respons['data']['response']['videos']
# 通过for循环把列表中的数据取出来并下载视频到本地
for vi in vi_url:
# 设置本地的文件保存
path1 = path + vi['title'] + '.mp4'
# 获取视频的下载链接
vi = vi['play_url']
# 访问链接
vi = requests.get(vi).content
# 把视频资源写入到指定的文件夹
print(path1 + '下载中--------')
with open(path1, 'wb') as mp4:
mp4.write(vi)
print(path1 + '下载完成')
# 需要下载视频的url列表
url = 'https://haokan.baidu.com/web/video/feed?tab=gaoxiao_new&act=pcFeed&pd=pc&num=20&shuaxin_id=1626081142774'
# 下载的视频保存位置
path = 'D:\\test1' + '\\'
# 调用下载视频的函数get_vi
a = get_vi(url,path)
下面是执行结果

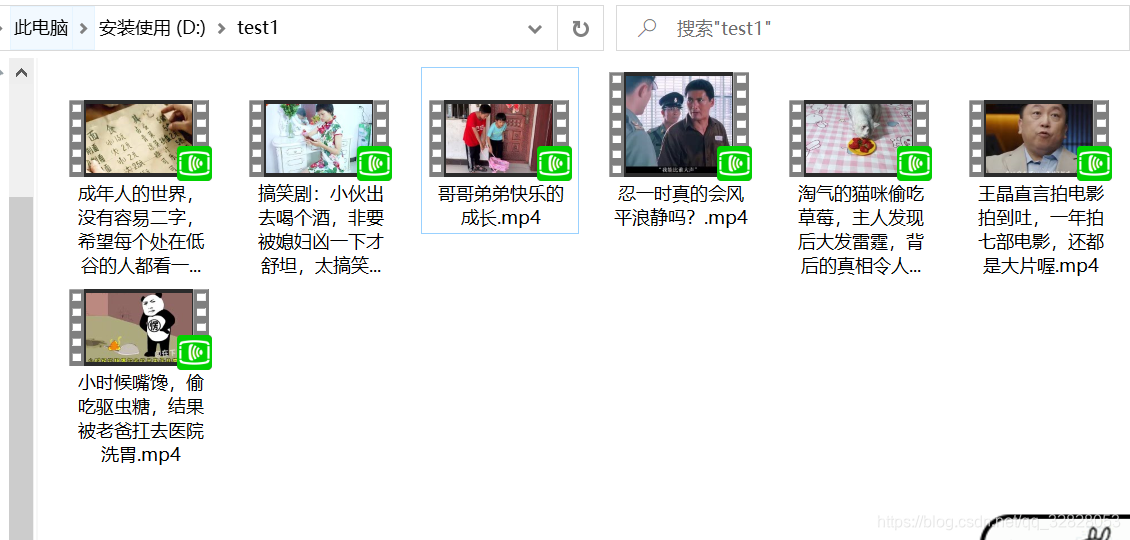
四、拓展
一个列表的数据下载完成了,这个时候我们就会想啦,我要爬取多个列表的数据呢,那这么操作;
一样的道理,让我们对比一下列表的请求参数看看有哪些是代表列表的页数的
第一个列表:https://haokan.baidu.com/web/video/feed?tab=youxi_new&act=pcFeed&pd=pc&num=20&shuaxin_id=1626341555015
第二个列表:https://haokan.baidu.com/web/video/feed?tab=youxi_new&act=pcFeed&pd=pc&num=20&shuaxin_id=1626341555015
嗯?嗯?怎么是一样的传参,那让我们来看看他们的响应
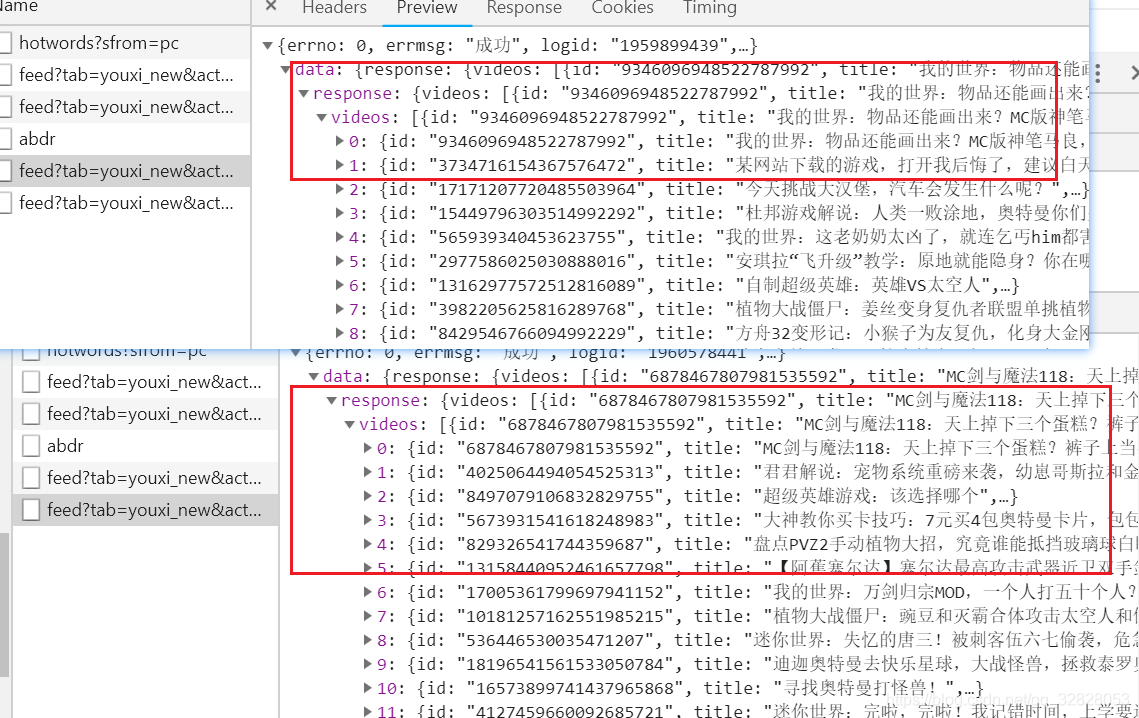
唉~ 有意思啦,响应竟然不一致,芜湖,这不就超纲了,让人头大呀,没有参数来进行判断那他是怎么实现翻页的呢,
这里我是个代码的小萌新,特意请求了一下开发的大佬,大佬就一句话他的响应是随机的。
啥?随机返回?随机?我屮艸芔茻还有这种操作?刷新了我的认知,
后来发现我是掉进去了,受接口影响太深,做了几次实验发现确实是随机返回,
那就更省劲了,它既然是随机返回的也就是说url是固定的,我们训话请求就行啦
如果需要更换获取的内容可以更改一下列表url传参就可以
分析一下传参
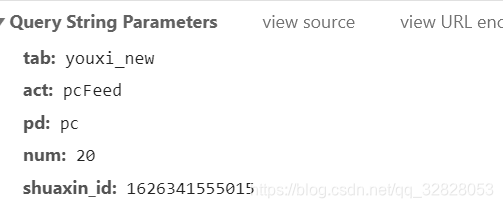
四个参数,根据名字我们就可以猜测出:
tab:youxi_new youxi? 我们大胆猜测一下,当前访问游戏频道所以是游戏的拼音,那我们需要爬哪个的时候不就更换成指定的比如说娱乐:yule_new
act:pcFeed 不知道啥意思,应该带代表电脑端请求的
pd:pc 也不知道啥意思,不过不应该,猜测和上面一直,咱们也不用管他
num:20 num?数量?返回的视频数量?对比一下还真是
shuaxin_id:1626341555015 这一串看着熟悉,时间戳?试了一下发现位数多了三个,猜测是随机数,尝试了一下果然很随机
我们只需要改一下tab就可以;
代码写的有点糙,没做异常的处理和视频下载进度时间显示等。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)