pandas存储excel方法
pandas存储excel方法举例说明注意一定要用双"\\"或者单向逆斜杠"/"演示结果
·
a_data=pd.DataFrame()#你的数据集
a_data.to_excel(excel_writer= r"#你想要存储的路径\\你想要存储的文件名.xlsx")举个例子
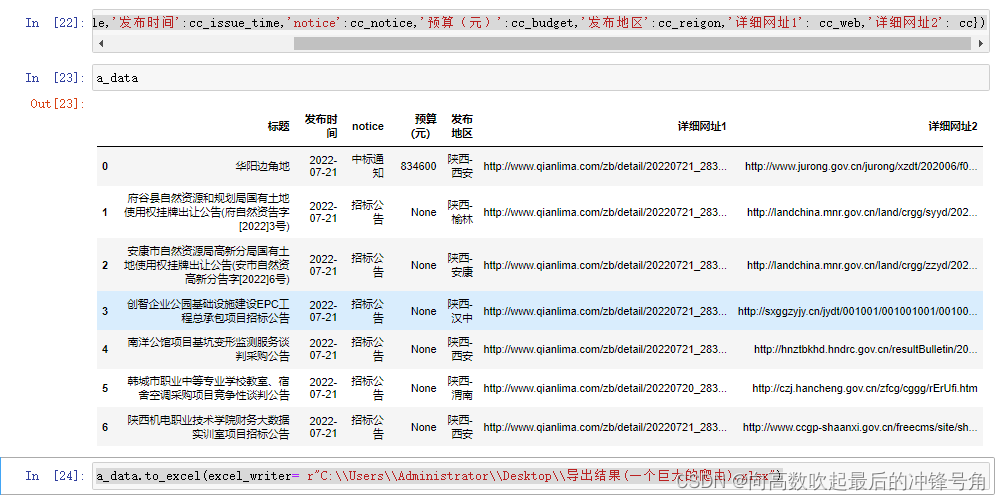
a_data=pd.DataFrame({'标题':cc_title,'发布时间':cc_issue_time,'notice':cc_notice,'预算(元)':cc_budget,'发布地区':cc_reigon,'详细网址1': cc_web,'详细网址2': cc})
a_data.to_excel(excel_writer= r"C:\\Users\\Administrator\\Desktop\\导出结果(一个巨大的爬虫).xlsx")注意一定要用双"\\"或者单向逆斜杠"/"
举例说明
#可以这样写
C:\\Users\\Administrator\\Desktop\\导出结果(一个巨大的爬虫).xlsx
#或者这样写
C:/Users/Administrator/Desktop/导出结果(一个巨大的爬虫).xlsx演示结果

其实除了pandas库可以处理excel存储的问题外
还有很多别的库
比如 xlwt 库
import xlwt
workbook=xlwt.Workbook(encoding='utf-8')
booksheet=workbook.add_sheet('Sheet 1', cell_overwrite_ok=True)
DATA=((数据标签的位置),
(第一行数据),
(第二行数据),
#以此类推
)
for i,row in enumerate(DATA):
for j,col in enumerate(row):
booksheet.write(i,j,col)
workbook.save('你想存储的文件名.xls')
#默认存储在Desktop中但不建议使用
理由:
pandas除了excel储存与读取
其实还有很多数据处理的函数
例如 pd.DataFrame() pd.read_csv()等。
#举例说明
pd.DataFrame() # 自己创建数据框,用于练习
pd.read_csv() # 从CSV⽂件导⼊数据
pd.read_table() # 从限定分隔符的⽂本⽂件导⼊数据
pd.read_excel() # 从Excel⽂件导⼊数据
pd.read_sql() # 从SQL表/库导⼊数据
pd.read_json() # 从JSON格式的字符串导⼊数据
pd.read_html() # 解析URL、字符串或者HTML⽂件,抽取其中的tables表格
以上几个例子基本包含了日常进行数据导入的常用形式。
对于常用的数据分析pandas基本拟合的
真的非常适合在数据分析前做处理工作
如果不使用pandas的话经常会陷入后期东拼西凑库的窘境
数据处理的工作会变得很麻烦。
建议新手多研究一下pandas库

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)