8个常用的Python数据分析库(附案例+源码)
大家好,我是辰哥~点击下方名片关注和星标『Python研究者』!????点击关注|设为星标|干货速递????今天给大家分析8个Python中常用的数据分析工具,Python强大之处在于其第三方扩展库较...
大家好,我是辰哥~
点击下方名片关注和星标『Python研究者』!
👆点击关注|设为星标|干货速递👆
今天给大家分析8个Python中常用的数据分析工具,Python强大之处在于其第三方扩展库较多。
本文介绍数据分析方面的扩展库分别为:NumPy、SciPy、Matplotlib、Pandas、StatsModels、Scikit-learn、Keras、Gensim,下面对这八个扩展库进行简单介绍,以及相关的代码案例
01
NumPy
NumPy 提供了真正的数组功能以及对数据进行快速处理的函数,是Python中相当成熟和常用的库,更多的使用可以参考官方文档如下所示👇🏻:
参考链接:http://www.numpy.org
# 安装
pip install numpyNumPy操作数组案例
# _*_ coding: utf-8 -*
# 作用:代码中可以出现中文
# Numpy
import numpy as np
# 创建数组
na = np.array([20,21,12,1,2])
# 输出数组
print(na) # [20 21 12 1 2]
# 切片(取出前三个数字)
print(na[:3]) # [20 21 12]
# 输出na中的最小值
print(na.min()) # 1
# 从小到大排序
na.sort()
print(na) # [ 1 2 12 20 21]
# 创建二维数组
na2 = np.array([[1,2,3],[4,5,6]])
# 二维数组平方
na3 = na2 * na2
print(na3)
"""
[[ 1 4 9]
[16 25 36]]
"""02
SciPy
SciPy依赖于NumPy,因此安装前需先安装NumPy。SciPy包含的功能有最优化、线性代数、积分、插值、拟合、特殊函数、快速傅里叶变换、信号处理和图像处理、常微积分求解等其他科学与过程中常用的计算。
更多的使用可以参考官方文档如下所示👇🏻:
参考链接:http://www.scipy.org
# 安装
pip install scipySciPy求解非线性方程
from scipy.optimize import fsolve
# 例子:求解非线性方程组 2x1 - x2^2 = 1 , x1^2 - x2 = 2
# 定义求解的方程组
def f(x):
x1 = x[0]
x2 = x[1]
return [2*x1-x2**2-1,x1**2-x2-2]
# 初始值,并求解
print(fsolve(f,[1,1]))
# 输出
[1.91963957 1.68501606]SciPy操作数值积分
# 数值积分
from scipy import integrate
def g(x):
return (1-x**2)**0.5
pi_2, err = integrate.quad(g,-1,1)
# 积分结果 和 误差
print(pi_2*2,err) # 积分结果为π的一半
# 输出
3.1415926535897967
1.0002354500215915e-0903
Matplotlib
Matplotlib是最著名的绘图库,主要用于二维绘图,以及简单的三维绘图。它提供了一整套丰富的命令,让我们可以非常快捷地用Python可视化数据,而且允许输出达到出版质量的多种图像格式。
更多的使用可以参考官方文档如下所示👇🏻:
参考链接:http://matplotlib.org
# 安装
pip install matplotlibMatplotlib雷达图案例
# 在jupyter notebook运行需要加上下面这句
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
# 创建figure
fig = plt.figure(dpi=120)
# 准备好极坐标系的数据
# 半径为[0,1]
r = np.arange(0, 1, 0.001)
theta = 2 * 2*np.pi * r
# 极坐标下绘制
line, = plt.polar(theta, r, color='#ee8d18', lw=3)
plt.show()运行结果
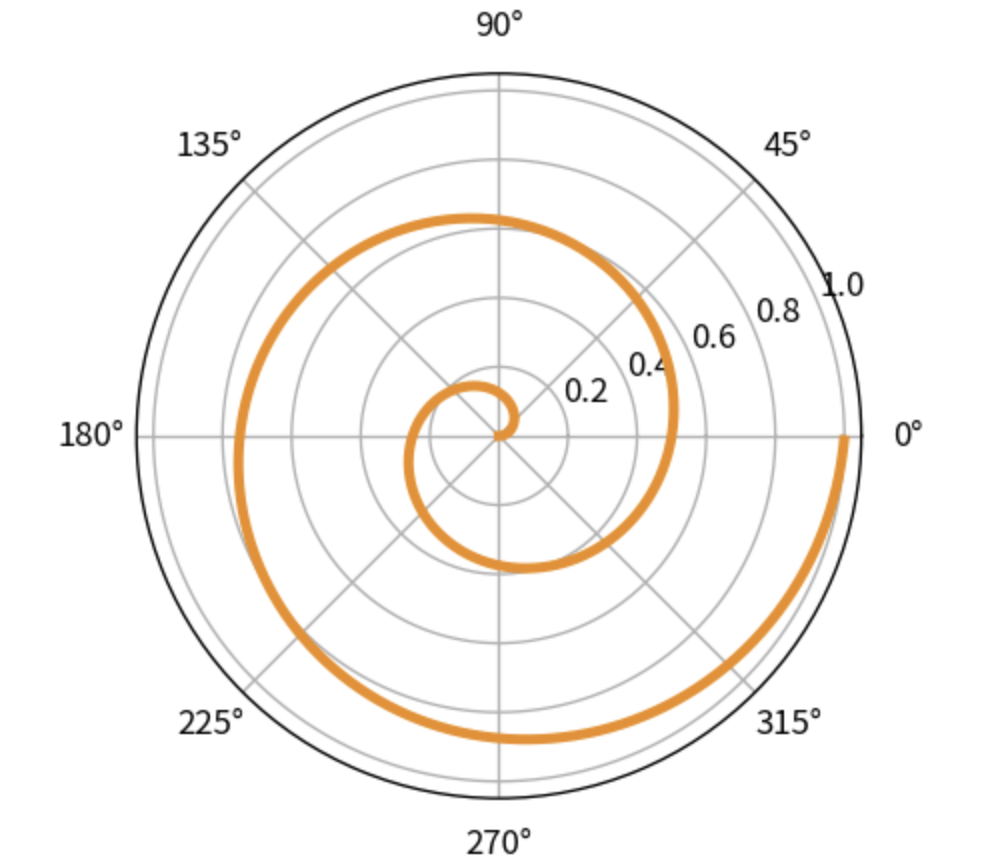
值得注意的是:中文乱码问题,如果图表中有中文,请在开头加入下面代码
#window版 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
#mac版 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False04
Pandas
Pandas 是Python下最强大的数据分析和探索工具,包含高级的数据结构和精巧的工具,支持类似SQL的数据增、删、查、改,并有丰富的数据处理函数;支持时间序列分析功能;灵活处理缺失数据等。
更多的使用可以参考官方文档如下所示👇🏻:
参考链接:https://pandas.pydata.org/pandas-docs/stable/
# 安装
pip install pandasPandas操作案例
import numpy as np
import pandas as pd
#使用 Series 生产序列,Pandas默认生成整数索引
res = pd.Series([1,3,4, np.nan, 6,8])
print(res)运行结果:

# 使用含日期时间索引和标签的Numpy数组生成DateFrame
dates = pd.date_range('20200703', periods = 6)
print(dates)
df = pd.DataFrame(np.random.randn(6,5),index = dates, columns = list('ABCDE'))
print(df)运行结果:

05
StatsModels
StatsModels 注重数据的统计建模分析,使得Python有了R语言的味道。与Pandas 结合成为Python下强大的数据挖掘组合。
更多的使用可以参考官方文档如下所示👇🏻:
参考链接:https://www.statsmodels.org/stable/index.html
# 安装
pip install statsModelsStatsModels操作回归模型
import statsmodels.api as sm
import numpy as np
# 举例:回归公式
# Y=1+10⋅X
nsample = 100
# 虚构一组数据
x = np.linspace (0, 10, nsample)
# 加入一列常项 1
X = sm.add_constant (x)
beta = np.array ([1, 10])
# 生成一个长度为 k 的正态分布样本
e = np.random.normal (size=nsample)
y = np.dot (X, beta) + e
# 反应变量和回归变量上使用 OLS () 函数
model = sm.OLS (y,X)
# 拟合结果
results = model.fit ()
# 计算出的回归系数
print (results.params)
# 输出
[ 0.9661724 10.0264137]
### 和实际的回归系数非常接近(Y=1+10⋅X)06
Scikit-learn
Scikit-learn 是一个与机器学习相关的库,它提供了完善的机器学习工具箱,包括数据预处理、分类、回归、聚类、预测、模型分析等。
更多的使用可以参考官方文档如下所示👇🏻:
参考链接:https://scikit-learn.org/stable/
# 安装
pip install scikit-learnScikit-learn 线性分类SVM模型
from sklearn import datasets, svm
# 加载数据集
iris = datasets.load_iris()
# 查看数据集大小 (150, 4)
print(iris.data.shape)
# 建立线性SVM分类器
clf = svm.LinearSVC()
# 训练模型
clf.fit(iris.data, iris.target)
# 预测
print(clf.predict([[5.0, 3.6, 1.3, 0.25]]))
输出:[0]07
Keras
Keras 并非简单的神经网络库,而是一个基于Theano 的强大的深度学习库,不仅可以搭建简单普通的神经网络,还可以搭建各种深度学习模型,如自编码器、循环神经网络、递归神经网络、卷积神经网络等。
使用Keras搭建神经网络模型的过程相当简单,也相当直观,就想搭积木一样,通过几十行代码,就可以搭建起一个非常强大的神经网络模型,甚至是深度学习模型。
举例:简单搭建一个MLP(多层感知器)
更多的使用可以参考官方文档如下所示👇🏻:
参考链接:https://keras.io/
# 安装
pip install kerasKeras搭建MLP案例
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
# 生成虚拟数据
x_train = np.random.random((1000, 20))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100, 20))
y_test = np.random.randint(2, size=(100, 1))
model = Sequential() # 模型初始化
model.add(Dense(64, input_dim=20, activation='relu')) # 添加输入层(20节点)、第一隐藏层(64节点)的连接
model.add(Dropout(0.5)) # 使用Dropout防止过拟合
model.add(Dense(64, activation='relu')) #第一隐藏层用relu作为激活函数
model.add(Dropout(0.5)) # 使用Dropout防止过拟合
model.add(Dense(1, activation='sigmoid')) # 第二隐藏层用sigmoid作为激活函数
model.compile(loss='binary_crossentropy', #损失函数为二进制交叉熵
optimizer='rmsprop', #定义求解算法
metrics=['accuracy']) #编译生成模型
model.fit(x_train, y_train,
epochs=20,
batch_size=128) #训练模型
score = model.evaluate(x_test, y_test, batch_size=128) #测试模型运行结果:

重点在于讲解模型搭建,此参数并非最优
08
Gensim
Gensim 用来处理语言方面的任务,如文本相似度计算、LDA、Word2Vec等。
据说Gensim的作者对Word2Vec的代码进行了优化,所以它在Gensim下的表现据说比原生的Word2Vec还要快。
更多的使用可以参考官方文档如下所示👇🏻:
参考链接:https://radimrehurek.com/gensim/
# 安装
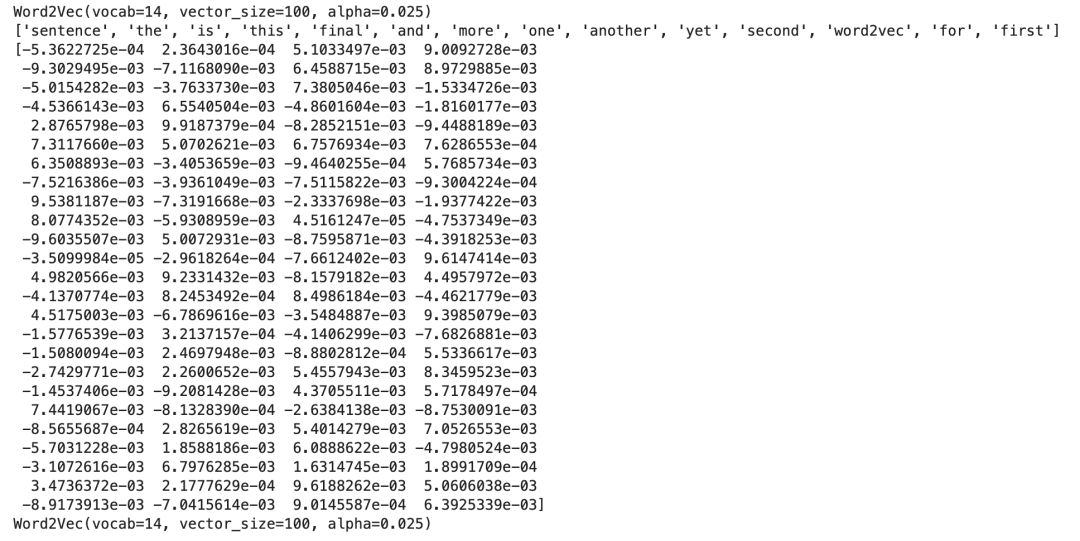
pip install gensimGensim使用Word2Vec案例
from gensim.models import Word2Vec
# 定义训练数据
sentences = [['this', 'is', 'the', 'first', 'sentence', 'for', 'word2vec'],
['this', 'is', 'the', 'second', 'sentence'],
['yet', 'another', 'sentence'],
['one', 'more', 'sentence'],
['and', 'the', 'final', 'sentence']]
# 训练模型
model = Word2Vec(sentences, min_count=1)
# 模型参数
print(model)
# 词汇
words = list(model.wv.key_to_index)
print(words)
# 一个词的访问向量
print(model.wv['sentence'])
# 保存模型
model.save('model.bin')
# 加载模型
new_model = Word2Vec.load('model.bin')
print(new_model)运行结果:

END
创作不易,路过的小伙伴右下角点赞和再看,鼓励一下
觉得不错的话,可以分享给其他小伙伴

分享

收藏

点赞

在看
最后





为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)