图像恢复(加噪与去噪)
2.1实验介绍2.1.1实验背景机器学习:机器学习是一类算法的总称,这些算法企图从大量历史数据中挖掘出其中隐含的规律,并用于预测或者分类,更具体的说,机器学习可以看作是寻找一个函数,输入是样本数据,输出是期望的结果,只是这个函数过于复杂,以至于不太方便形式化表达。需要注意的是,机器学习的目标是使学到的函数很好地适用于“新样本”,而不仅仅是在训练样本上表现很好。学到的函数适用于新样本的能力,称为泛化
人工智能导论实验导航
实验一:斑马问题 https://blog.csdn.net/weixin_46291251/article/details/122246347
实验二:图像恢复 https://blog.csdn.net/weixin_46291251/article/details/122561220
实验三:花卉识别 https://blog.csdn.net/weixin_46291251/article/details/122561505
实验四:手写体生成 https://blog.csdn.net/weixin_46291251/article/details/122576478
实验源码: xxx
2.1实验介绍
2.1.1实验背景
机器学习:
机器学习是一类算法的总称,这些算法企图从大量历史数据中挖掘出其中隐含的规律,并用于预测或者分类,更具体的说,机器学习可以看作是寻找一个函数,输入是样本数据,输出是期望的结果,只是这个函数过于复杂,以至于不太方便形式化表达。需要注意的是,机器学习的目标是使学到的函数很好地适用于“新样本”,而不仅仅是在训练样本上表现很好。学到的函数适用于新样本的能力,称为泛化(Generalization)能力。
机器学习作为人工智能核心技术,本章主要围绕机器学习涉及的决策树、主成分分析和集成算法而设计的实验。本章实验难度分均为初级。
图像恢复:
图象是一种非常常见的信息载体,但是在图像的获取、传输、存储过程中可能由于各种原因使得图像受到噪声的影响。如何去除噪声的影响,恢复图像原本的信息是计算机视觉中的重要研究问题。
常见的图像恢复算法有基于空间域的中值滤波、基于小波域的小波去噪、基于偏微分方程的非线性扩散滤波等。本次实验对图像添加噪声,并对添加噪声的图像进行基于线性回归模型的去噪。
2.1.2实验目的
本章实验的主要目的是掌握机器学习相关基础知识点,了解机器学习相关基础知识,经典降维方法、决策树算法和集成算法。熟悉机器学习的一般流程,具备使用python语言和机器学习算法解决实际问题的能力。
学习Python的Opencv库进行图像相关处理
学习Python的Numpy库进行相关数值计算
学习线性回归模型的应用
2.1.3实验简介
A. 生成受损图像。
受损图像(X)是由原始图像(I∈RH∗W∗CI∈RH∗W∗C)添加了不同噪声遮罩(noise masks)(M∈RH∗W∗CM∈RH∗W∗C)得到的(X=I⨀MX=I⨀M),其中⨀⨀是逐元素相乘。
噪声遮罩仅包含 {0,1} 值。对原图的噪声遮罩的可以每行分别用 0.8/0.4/0.6 的噪声比率产生的,即噪声遮罩每个通道每行 80%/40%/60% 的像素值为 0,其他为 1。
B. 使用你最擅长的算法模型,进行图像恢复。
C. 评估误差为所有恢复图像(R)与原始图像(I)的 2-范数之和,此误差越小越好。
error=∑3i=1norm(Ri(:)−Ii(😃,2)error=∑i=13norm(Ri(:)−Ii(😃,2),其中(:)是向量化操作,其他评估方式包括 Cosine 相似度以及 SSIM 相似度。
2.2概要设计
程序分为以下几步:
首先进行图片的读取,这里要注意matplotlib和opencv读取图片格式的不同,需要进行转换。然后将数据线性归一化,然后在原图上生成噪声比率为0.6的噪声,得到含噪的图片,这里添加的噪声类型为椒盐噪声。然后用中值滤波器对图像滤波以实现图像恢复。
实验的关键是加噪和去噪
加噪用的是椒盐噪声,椒盐噪声(salt-and-pepper noise)即一种是盐噪声(salt noise),另一种是胡椒噪声(pepper noise)。盐=白色(0),椒=黑色(255)。前者是高灰度噪声,后者属于低灰度噪声。这里两种噪声同时出现,呈现在图像上就是黑白杂点
去噪用的是中值滤波法:使用滤波器窗口包含区域的像素值的中值来得到窗口中心的像素值。是一种非线性平滑滤波器。在去噪同时,较好的保持边缘轮廓细节,适合处理椒盐噪声,但对高斯噪声效果不好。
2.3详细设计
2.3.1 导入工具包
matplotlib数据库下的pyplot模块是一个常用于图像展示的模块;
Numpy数据库用于相关的数值计算;
cv2,即opencv库,计算机视觉库,常用于图像的处理;
从sklearn.linear_model模块下导入线性回归(LinearRegression),岭回归(Ridge),Lasso回归。
岭回归(Ridge):在线性回归的基础上加了L2正则化项(L2范数),增加线性回归的泛化性能,它和一般线性回归的区别是在损失函数上增加了一个L2正则化的项,和一个调节线性回归项和正则化项权重的系数α。损失函数表达式如下:
J(θ)=(1/2)(Xθ−Y)T(Xθ−Y) + (1/2)α||θ||2
其中α为常数系数,需要进行调优。 ||θ||2 为L2范数。Ridge回归的解法和一般线性回归大同小异。
Lasso回归:有时也叫做线性回归的L1正则化,和Ridge回归的主要区别就是在正则化项,Ridge回归用的是L2正则化,而Lasso回归用的是L1正则化。Lasso回归的损失函数表达式如下:
J(θ)=(1/2)(Xθ−Y)T(Xθ−Y)+α||θ||1
其中α为常数系数,需要进行调优。 ||θ||1 为L1范数。
from matplotlib import pyplot as plt # 展示图片
import numpy as np # 数值处理
import cv2 # opencv库
from sklearn.linear_model import LinearRegression, Ridge, Lasso # 回归分析
2.3.2 读取图片:
读取图片我们采用 cv2.imread(filename[, flags]) 函数:
filename:文件路径
flags:指定加载图像颜色类型的标志
cv2.IMREAD_COLOR:读入一副彩色图像。图像的透明度会被忽略,这是默认参数,此时 flags=1。
cv2.IMREAD_GRAYSCALE:以灰度模式读入图像,此时 flags=0。
cv2.IMREAD_UNCHANGED:读入一幅图像,并且包括图像的 alpha 通道,此时 flags=-1。
彩色图像使用 OpenCV 加载时是 BGR 模式,但是 Matplotlib 是 RGB 模式。所以彩色图像如果已经被 OpenCV 读取,那它将不会被 Matplotlib 正确显示。因此我们将 BGR模式转换为 RGB 模式即可。
def read_image(img_path):
# 读取图片
img = cv2.imread(img_path)
# 如果图片是三通道,采用 matplotlib 展示图像时需要先转换通道
if len(img.shape) == 3:
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
return img
img_path = 'A.png'# 加载图片的路径和名称
img = read_image(img_path) # 读取图片
print(type(img))# 读取图片后图片的类型
plt.imshow(img) # 展示图片
plt.axis('off') # 关闭坐标
2.3.3 保存图片
OpenCV 保存一个图片使用函数 cv2.imwrite(filename, img[, params]):
filename:保存文件路径及文件名,文件名要加格式
img:需要保存的图片
def save_image(filename, image):
# np.copy() 函数创建一个副本。
# 对副本数据进行修改,不会影响到原始数据,它们物理内存不在同一位置。
img = np.copy(image)
img = img.squeeze()# 从给定数组的形状中删除一维的条目
if img.dtype == np.double: # 将图片数据存储类型改为 np.uint8
# 若img数据存储类型是 np.double ,则转化为 np.uint8 形式
img = img * np.iinfo(np.uint8).max
img = img.astype(np.uint8) # 转换图片数组数据类型
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)# 将 RGB 方式转换为 BGR 方式
cv2.imwrite(filename, img)# 生成图片
2.3.4 归一化
机器学习过程中,数据归一化非常重要,归一化的目标主要有:
把数变为(0,1)或者(-1,1)之间的小数
把有量纲表达式变为无量纲表达式
常见的归一化方法有:
线性比例变换法 xi=xi / max(x)
min-max标准化 xi=[xi−min(x)] /[ max(x)−min(x)]
z-score 标准化 xi=[xi−mean(x) ]/ σ
下面我们来实现线性比例变化法:
def normalization(image):
info = np.iinfo(image.dtype) # 获取图片数据类型对象的最大值和最小值
return image.astype(np.double) / info.max # 图像数组数据放缩在 0-1 之间
img_path = 'A.png'# 图片的路径和名称
img = read_image(img_path)# 读取图片
print("没有归一化的数据:\n", img[0, 0, :])# 展示部分没有归一化的数据:
img = normalization(img)# 图片数据归一化
print("归一化后的数据:\n", img[0, 0, :])# 展示部分 归一化后的数据
2.3.5 图片加噪
生成受损图像的实验要求:
受损图像(X)是由原始图像( I∈RH∗W∗C )添加了不同噪声遮罩(noise masks)( M∈RH∗W∗C )得到的( X=I⨀M ),其中 ⨀ 是逐元素相乘。
噪声遮罩仅包含 {0,1} 值。对原图的噪声遮罩的可以每行分别用 0.8/0.4/0.6 的噪声比率产生的,即噪声遮罩每个通道每行 80%/40%/60% 的像素值为0,其他为1。
椒盐噪声(salt-and-pepper noise)是指两种噪声,一种是盐噪声(salt noise),另一种是胡椒噪声(pepper noise)。盐=白色(0),椒=黑色(255)。前者是高灰度噪声,后者属于低灰度噪声。一般两种噪声同时出现,呈现在图像上就是黑白杂点

以下使用的是一个阈值(prob、thres)进行的噪声分布:
def noise_mask_image(img, noise_ratio):
"""
根据题目要求生成受损图片
:param img: 图像矩阵,一般为 np.ndarray
:param noise_ratio: 噪声比率,可能值是0.4/0.6/0.8
:return: noise_img 受损图片, 图像矩阵值 0-1 之间,数据类型为 np.array,
数据类型对象 (dtype): np.double, 图像形状:(height,width,channel),通道(channel) 顺序为RGB
"""
# 受损图片初始化
noise_img = np.zeros(img.shape, np.double)
for i in range(img.shape[0]):
for j in range(img.shape[1]):
if random.random() < noise_ratio: # 如果生成的随机数小于噪声比例则将该像素点添加黑点
noise_img[i][j] = 0 # 1 / 0
elif random.random() > 1-noise_ratio:
noise_img[i][j] = 1 # 1 / 0
else:
noise_img[i][j] = img[i][j]
return noise_img
2.3.6 误差评估
评估误差为所有恢复图像(R)与原始图像(I)的2-范数之和,此误差越小越好。 error=∑3i=1norm(Ri(:)−Ii(😃,2) ,其中(:)是向量化操作
def compute_error(res_img, img):
error = 0.0 # 初始化
res_img = np.array(res_img) # 将图像矩阵转换成为np.narray
img = np.array(img)
if res_img.shape != img.shape: # 如果2个图像的形状不一致,则打印出错误结果,返回值为 None
print("shape error res_img.shape and img.shape %s != %s" % (res_img.shape, img.shape))
return None
error = np.sqrt(np.sum(np.power(res_img - img, 2))) # 计算图像矩阵之间的评估误差
return round(error,3)
#计算平面二维向量的 2-范数值
img0 = [1, 0]
img1 = [0, 1]
print("平面向量的评估误差:", compute_error(img0, img1))
2.3.7 图像恢复
中值滤波器,使用滤波器窗口包含区域的像素值的中值来得到窗口中心的像素值。是一种非线性平滑滤波器。在去噪同时,较好的保持边缘轮廓细节,适合处理椒盐噪声,但对高斯噪声效果不好。
中值滤波原理:
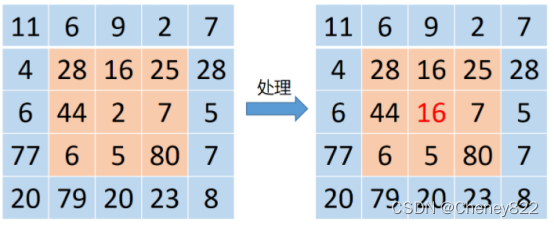
选一个含有奇数点的窗口W,将这个窗口在图像上扫描,把窗口中所含的像素点按灰度级的升或降序排列,取位于中间的灰度值来代替该点的灰度值。 例如选择滤波的窗口如下图,是一个一维的窗口,待处理像素的灰度取这个模板中灰度的中值.
换成图像模板来理解就是将临近像素按照大小排列,取排序像素中位于中间位置的值作为中值滤波的像素值
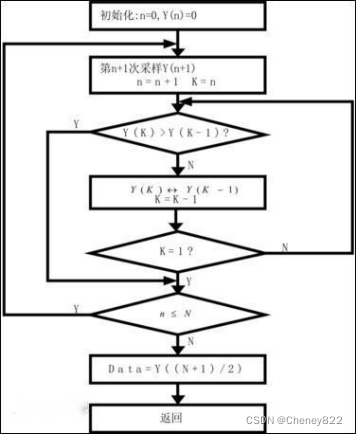
中值滤波流程图:
def restore_image(noise_img, size=4):
img = noise_img
size = 5 # 核尺寸
num = int((size - 1) / 2) # 输入图像需要填充的尺寸
img = cv2.copyMakeBorder(img, num, num, num, num, cv2.BORDER_REPLICATE)
h, w = img.shape[0:2] # 获取输入图像的长宽和高
h-=4;w-=4
img1 = np.zeros((h, w, 3), dtype="uint8") # 定义空白图像,用于输出中值滤波后的结果
for i in range(num, h - num): # 遍历出原图像
for j in range(num, w - num):
sum = []; sum1 = []
for k in range(i - num, i + num + 1): # 求中心像素周围size*size区域内的像素的平均值
for l in range(j - num, j + num + 1):
sum = sum + [int(img[k, l][0]) + int(img[k, l][1]) + int(img[k, l][2])] # 每个像素的3通道像素值相加,然后求中间数
sum1 = sum1 + [(img[k, l][0], img[k, l][1], img[k, l][2])] # 将对于的三通道像素值存在数组sum1中
id = np.argsort(sum) # 将像素值周围的点的数组进行排序,然后返回排序之前的像素值对应在数组中的序号
id = id[int((size ** 2) / 2) + 1] # 取返回序号的中间序号
img1[i, j] = sum1[id] # 通过中间序号找到在像素值数组中的3通道信号
return img1
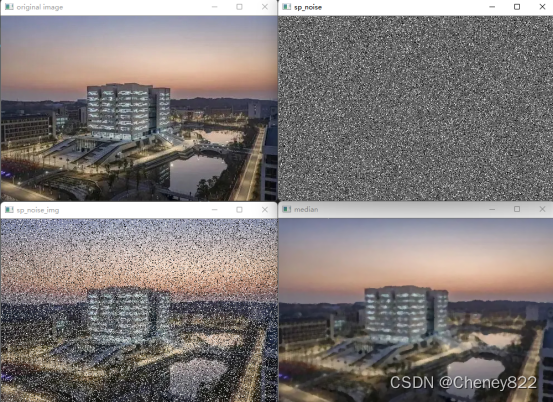
2.4运行测试
原图:

噪声

加噪后的图片:

去噪后的图片:

总体对比图:
程序计算出的误差与相似度:

即:
恢复图片与原始图片的评估误差:5140.961
恢复图片与原始图片的SSIM 相似度:0. 12262643111991207
恢复图片与原始图片的Cosine 相似度:0.8794560914526841
通过上述误差的分析和人眼对修复后的图片的观察可知程序在一定程度上修复了含有噪声的图片,但修复效果仍有一定的提升空间。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)