python数据分析-concat合并表,报错InvalidIndexError: Reindexing only valid with uniquely valued Index objects
python数据分析-merge函数详解在工作中合并表用的比较多,但是merge一直搞不特别清,找了时间仔细的试了试各种情况,在这里做个记录。下面是merge函数的参数:Signature:pd.merge(left,right,how: str = 'inner',on=None,left_on=None,right_on=None,left_index: bool = False,right_
·
问题:在用concat函数给DataFrame做合并的时候抛出错误:InvalidIndexError: Reindexing only valid with uniquely valued Index objects
查了一些原因,口径都比较统一,都是索引重复引发的报错。索引只有行索引和列索引,首先排除行索引的问题,因为行索引比较简单。。。
首先做一下测试用的数据
a = pd.DataFrame({'A':[1,2,3,4],'B':[5,6,7,8],'C':['a','a','a','a'],'D':['q','q','q','q']})
b = pd.DataFrame({'A':[1,2,3],'A':[5,6,7],'C':['a','a','a'],'D':['q','q','q']})
c = pd.concat([a,b],axis=0)
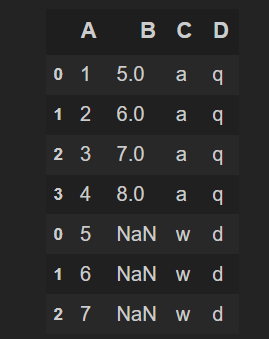
一、行索引问题的排除
可见上面的变量c的索引不是连续的,所以我们利用函数重置索引。
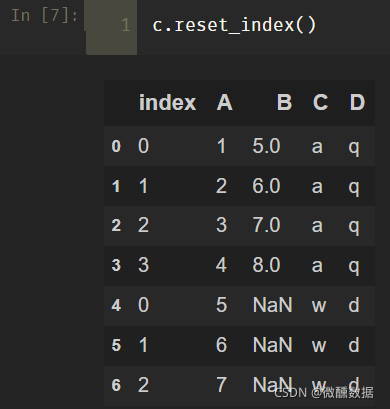
利用reset_index()函数。
drop: 重新设置索引后是否将原索引作为新的一列并入DataFrame,默认为False
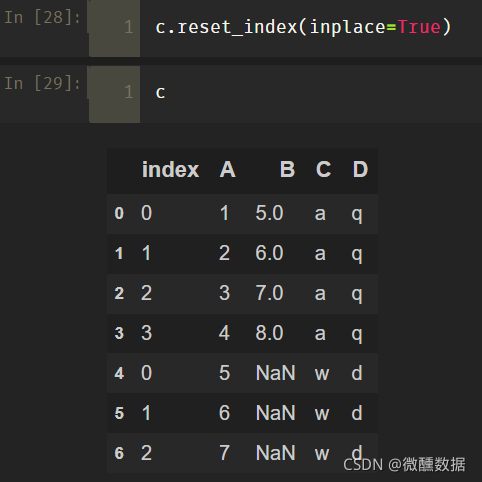
inplace: 是否在原DataFrame上改动,默认为False
level: 如果索引(index)有多个列,仅从索引中删除level指定的列,默认删除所有列
col_level: 如果列名(columns)有多个级别,决定被删除的索引将插入哪个级别,默认插入第一级
col_fill: 如果列名(columns)有多个级别,决定其他级别如何命名
(1)如果不指定drop参数,则会把之前的索引作为新的列加入到数据。
(2)inplace参数的数值结果如下,不确定对不对,很少用 -_+…
二、如果行索引没有问题的话,就是检查列索引了,列名是否重复。
#下面的方法用于查看列名中是否有重复的元素
aa = a.columns.to_list()
bb = set(aa)
if len(aa) == len(bb):
print('没有重复的元素!')
else:
print('有重复的元素!')
#查看重复的元素是哪些,及重复的次数
from collections import Counter
a = a.columns.to_list()
b = dict(Counter(a))
# 打印重复的元素
print ([key for key,value in b.items() if value > 1]) 、
#打印重复元素和重复元素的重复次数
print ({key:value for key,value in b.items() if value > 1})
#查看重复的列,决定删除或修改哪列
a.filter(like='A')
到此就找到了所有的重复的列名啦!下面是完整的代码,如果大家有更好的方法欢迎分享。
a = pd.DataFrame({'A':[1,2,3,4],'B':[5,6,7,8],'C':['a','a','a','a'],'D':['q','q','q','q']})
b = pd.DataFrame({'A':[1,2,3],'A':[5,6,7],'C':['w','w','w'],'D':['d','d','d']})
c = pd.concat([a,b],axis=0)
#下面的方法用于查看列名中是否有重复的元素
aa = a.columns.to_list()
bb = set(aa)
if len(aa) == len(bb):
print('没有重复的元素!')
else:
print('有重复的元素!')
#########################################
from collections import Counter
a = a.columns.to_list()
b = dict(Counter(a))
# 打印重复的元素
print ([key for key,value in b.items() if value > 1])
#打印重复元素和重复元素的重复次数
print ({key:value for key,value in b.items() if value > 1})
a.filter(like='A')

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)