python机器学习之SVM(支持向量机)实例
其实在很早以前写过一期SVM,只不过当时对SVM只是初步的了解,现在重新来看,其实SVM还是有很多值得学习的地方。1.SVM介绍SVM可以理解为:使用了支持向量的算法,支持向量机是一种基于分类边界分界的方法。以二维数据为例,如果训练数据分布在二维平面上的点,它们按照其分类聚焦在不同的区域。基于分类边界的分类算法的目标:通过训练,找到这些分类之间的边界(如果是直线的,称为线性划分,如果是曲线的,称为
其实在很早以前写过一期SVM,只不过当时对SVM只是初步的了解,现在重新来看,其实SVM还是有很多值得学习的地方。
1.SVM介绍
SVM可以理解为:使用了支持向量的算法,支持向量机是一种基于分类边界分界的方法。以二维数据为例,如果训练数据分布在二维平面上的点,它们按照其分类聚焦在不同的区域。基于分类边界的分类算法的目标:通过训练,找到这些分类之间的边界(如果是直线的,称为线性划分,如果是曲线的,称为非线性划分)。
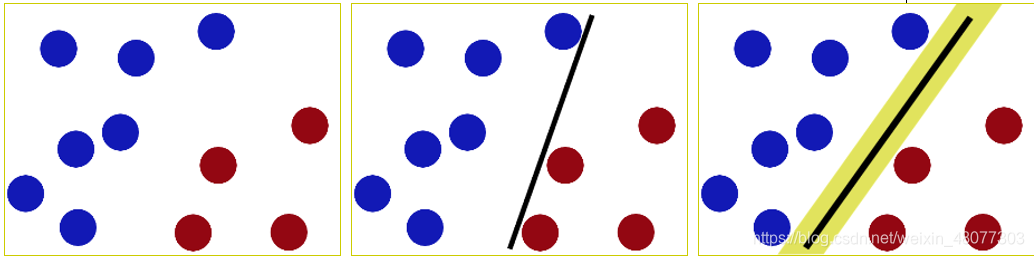
过程如上述三个图,SVM就是试图把棍放在最佳的位置上,最好让棍两边有尽可能大的间隙,这个间隙就是球到棍的距离。这样的好处就是使两个种类有明确的的边界,使其在测试集上的效果不至于太差。
自己的看法:在集成算法还未成熟,尤其是xgboost还未出现之前,SVM 是最好的分类算法,尤其是在非线性可分的情况下,SVM所达到的准确度是其他机器学习分类算法所达不到的。虽然SVM建模过程较复杂,但任然是非常值得学习的一种算法。
2.SVM原理
2.1 SVM的主要特点:
- SVM主要思想是针对两类分类问题,在高维空间中寻找一个超平面作为两类的分割,以保证最小的分类错误率。
- SVM考虑寻找一个满足分类要求的超平面,并且使训练集中的点距离分类面尽可能的远,即寻找一个分类面使它两侧的空白区域(margin)最大。
- 过两类样本中离分类面最近的点且平行于最优分类面的超平面上的训练样本就叫做支持向量。
- 最优分类面就是要求分类线不但能将两类正确分开(训练错误率为0),且使分类间隔最大。
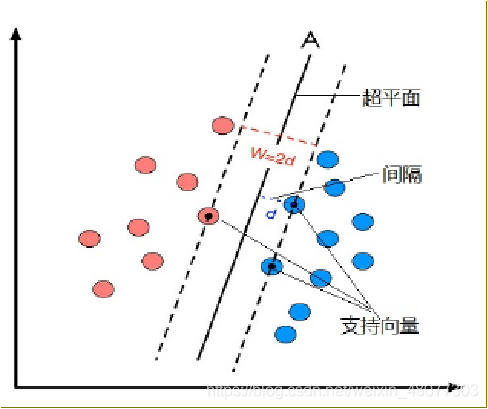
2.2 SVM的原理过程
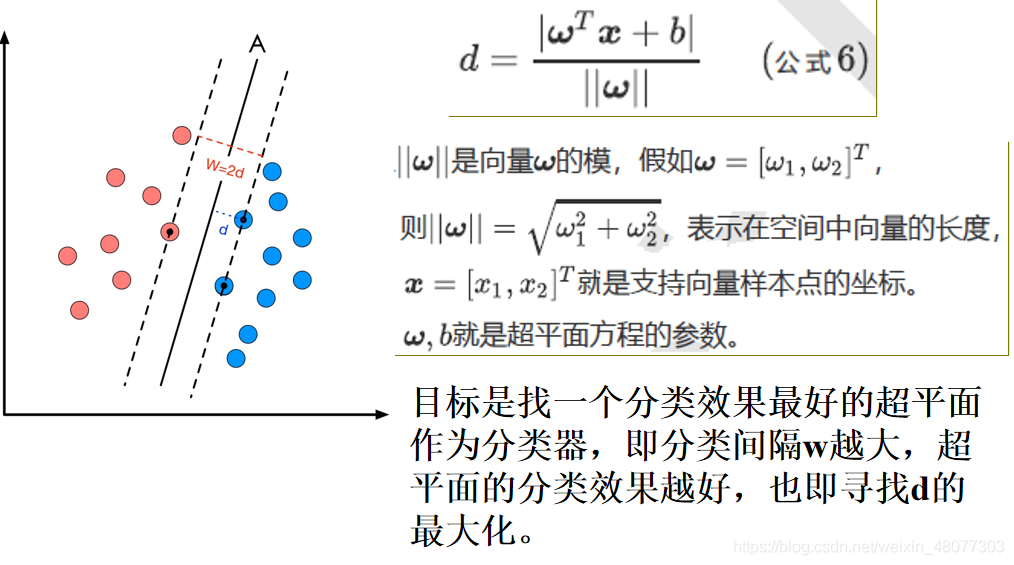
目标函数显然就是那个“分类间隔”,而优化对象则是分类超平面。
1.超平面方程
在线性可分的二类分类问题中,超平面就是一条直线,在三维中,超平面就是一个平面。
- 这里讲述了如何将一个直线方程转化为向量形式的方程。并且可将该规律推广到更高的维度。

2.点到直线的距离 - 点到直线的距离采用向量的表示方法如下:
这里解释一下为什么要使分类距离最大,其实这些点到直线的距离可以理解为样本分类的确信度,也就是说,如果点到分类直线的聚类越远,对分类样本分类的确信度就越大。要找到使两类分类的确信度都最大,就各自取一半一半,即中间的直线。
3.约束条件 - 并不是所有的方向都存在能够实现100%正确分类的分类超平面,如何判断一条直线是否能够将所有的样本点都正确分类?
- 即便找到了正确的超平面方向,还要注意分类超平面的位置应该在间隔区域的中轴线上,所以用来确定分类超平面位置的截距b也不能随意的取值,而是受到分类超平面方向和样本点分布的约束。
- 即便取到了合适的方向和截距,该如何找到对应的支持向量来计算距离d?
以二维分类为例:平面上有2种颜色的点,红色和蓝色,我们对它们进行标记,红色圆点标记为1,为正样本;蓝色五角星标记为-1,为负样本。则该模型可以表示为:
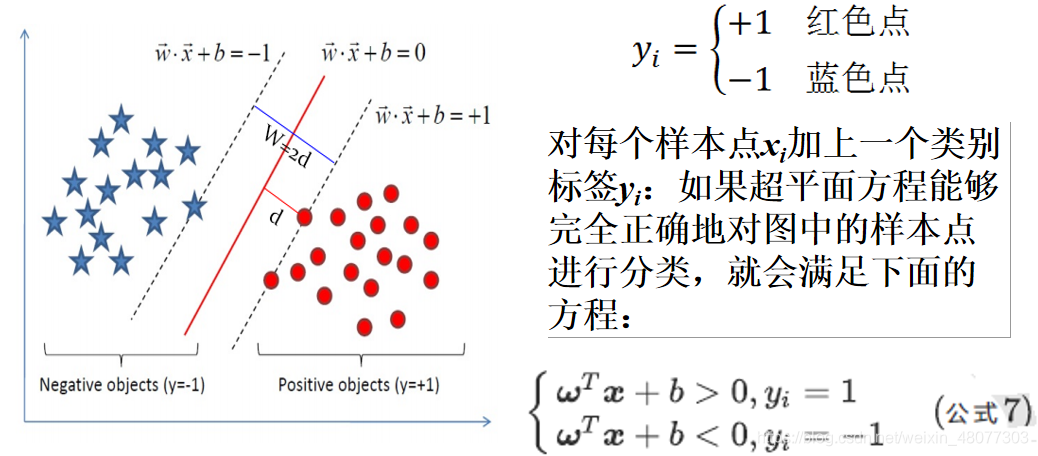
我们假设我们所绘制的直线正好处于分类间隔的中轴线上,且对应的支持向量对应的样本点到直线的距离为d则公式可表示为:

接着我们就可以对表达式进行化简。

4.线性SVM约束问题的基本描述


关于svm原理部分,我就先讲到这里,后面的部分就是关于函数的求解过程,比较繁琐,大家有兴趣可以查看李航的《统计学习方法》
5.SVM的核函数 - 核函数的作用:接受两个低维空间里的向量,能够计算出经过某个变换后在高维空间里的向量内积值。
- 在核函数给定的条件下,可以利用解线性分类的方法求解非线性分类问题的SVM。学习是隐式地在特征空间中进行的,不需要显式地定义特征空间和映射函数。

一般情况下,首先选RBF函数最为核函数。
3.SVM的案例
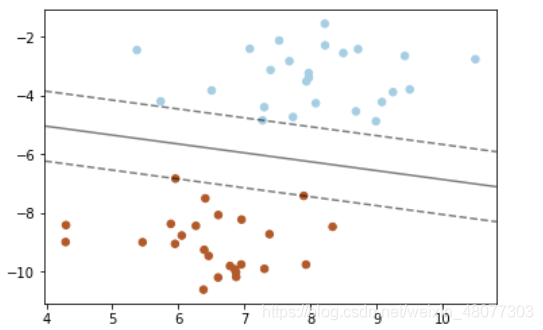
3.1svm分类问题(随机生成的分类点)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs
#这里我们创建了50个数据点,并将它们分为了2类
x,y=make_blobs(n_samples=50,centers=2,random_state=6)
print(y)
#构建一个内核为线性的支持向量机模型
clf=svm.SVC(kernel="linear",C=1000)
clf.fit(x,y)
plt.scatter(x[:,0],x[:,1],c=y,s=30,cmap=plt.cm.Paired)
#建立图形坐标
ax=plt.gca()
xlim=ax.get_xlim()#获取数据点x坐标的最大值和最小值
ylim=ax.get_ylim()#获取数据点y坐标的最大值和最小值
#根据坐标轴生成等差数列(这里是对参数进行网格搜索)
xx=np.linspace(xlim[0],xlim[1],30)
yy=np.linspace(ylim[0],ylim[1],30)
YY,XX=np.meshgrid(yy,xx)
xy=np.vstack([XX.ravel(),YY.ravel()]).T
Z=clf.decision_function(xy).reshape(XX.shape)
#画出分类的边界
ax.contour(XX,YY,Z,colors='K',levels=[-1,0,1],alpha=0.5,linestyles=["--","-","--"])
ax.scatter(clf.support_vectors_[:,0],clf.support_vectors_[:,1],s=100,linewidths=1,facecolors="none")
plt.show()
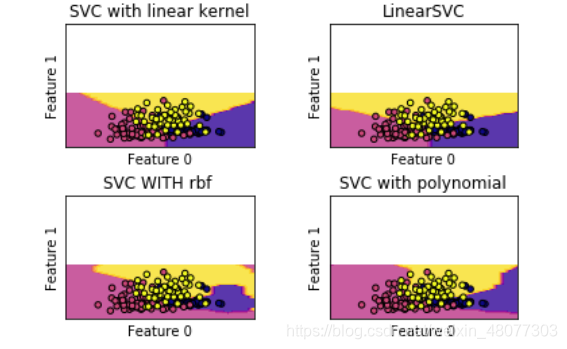
3.2 svm红酒分类问题
#定义一个画图的函数
def make_meshgrid(x,y,h=0.2):
x_min,x_max=x.min()-1,x.max()+1
y_min,y_max=y.min()-1,y.max()+1
xx,yy=np.meshgrid(np.arange(x_min,x_max,h),np.arange(y_min,y_max,h))
return xx,yy
#定义一个绘制等高线的函数
def plot_contours(ax,clf,xx,yy,**param):
Z=clf.predict(np.c_[xx.ravel(),yy.ravel()])
Z=Z.reshape(xx.shape)
out=ax.contourf(xx,yy,Z,**param)
return out
wine=load_wine()
X=wine.data[:,:2]
y=wine.target
C=1.0#SVM的正则化参数
models=(svm.SVC(kernel="linear",C=C),#L1正则化
svm.LinearSVC(C=C),#L2正则化
svm.SVC(kernel="rbf",gamma=0.7),#径向基 gamma为内核宽度
svm.SVC(kernel="poly",degree=3,C=C)#特征多项式)
models=(clf.fit(X,y) for clf in models)
#设定图例
titles=('SVC with linear kernel',"LinearSVC","SVC WITH rbf ","SVC with polynomial")
#s设定一个子图形的个数和排列方式
fig,sub=plt.subplots(2,2)
plt.subplots_adjust(wspace=0.4,hspace=0.4)
#使用前面定义的函数进行画图
X0,X1=X[:,0],X[:,1]
xx,yy=make_meshgrid(X0,X1)
for clf,title,ax in zip(models,titles,sub.flatten()):
plot_contours(ax,clf,xx,yy,cmap=plt.cm.plasma,alpha=0.8)
ax.scatter(X0,X1,c=y,cmap=plt.cm.plasma,s=20,edgecolors='k')
ax.set_xlim(xx.min(),xx.max())
ax.set_ylim(yy.min(),xx.max())
ax.set_xlabel("Feature 0")
ax.set_ylabel("Feature 1")
ax.set_xticks(())
ax.set_yticks(())
ax.set_title(title)
plt.show()
3.2 svm回归的案例
svm也可以用于回归。
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
boston=load_boston()#boston数据中含有13个特征信息
#划分数据集
X,y=boston.data,boston.target
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=8)#random_state是设置随机种子数
st=StandardScaler()
st.fit(X_train)
X_train=st.transform(X_train)
X_test=st.transform(X_test)
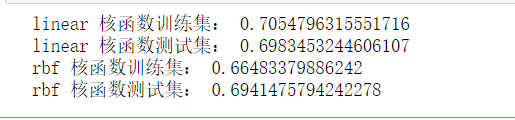
for kernel in ['linear','rbf']:
svr=SVR(kernel=kernel)
svr.fit(X_train,y_train)
print(kernel,"核函数训练集:",svr.score(X_train,y_train))
print(kernel,"核函数测试集:",svr.score(X_test,y_test))
回归的准确率并不是很高。
4.总结
- SVM在机器学习领域算是一种非常强大的算法,尤其对于少量的数据(1万以内),SVM都能驾驭得了。
- SVM对参数的要求特别高,我一般情况下还是选择集成算法。
- SVM处理特征样本数据不平衡的数据效果不太好。
- 无论怎样,SVM还是很有价值的。
参考资料
书籍:《深入浅出python机器学习》
课程:覃老师的《数据挖掘与机器学习》

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 33
33 1
1- 0



 已为社区贡献20条内容
已为社区贡献20条内容
 免费领云主机
免费领云主机




 华为云 x DeepSeek:AI驱动云上应用创新
华为云 x DeepSeek:AI驱动云上应用创新

 DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
 华为云数字人,助力行业数字化业务创新
华为云数字人,助力行业数字化业务创新
 企业数据治理一站式解决方案及应用实践
企业数据治理一站式解决方案及应用实践
 轻松构建AIoT智能场景应用
轻松构建AIoT智能场景应用


所有评论(0)