Pyhton学习记录(二) 利用鸢尾花进行简单数据分析
1 导入本文所有需要的库from sklearn.datasets import load_iris# 导入鸢尾花数据集import pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.linear_model import LogisticRegression# 使用逻辑回归算法from skl
1 导入本文所有需要的库
from sklearn.datasets import load_iris # 导入鸢尾花数据集
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LogisticRegression # 使用逻辑回归算法
from sklearn.model_selection import train_test_split # 将数据集划分为训练集和测试集
from sklearn.neighbors import KNeighborsClassifier # for nearest neighbours
from sklearn import svm # 使用支持向量机算法
from sklearn import metrics # 用于检查模型准确率
from sklearn.tree import DecisionTreeClassifier # 使用决策树算法
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# plt显示不出中文,解决方式,上面两个命令
IRIS数据集由Fisher在1936年整理,包含4个特征(Sepal Length(花萼长度)、Sepal Width(花萼宽度)、Petal Length(花瓣长度)、Petal Width(花瓣宽度)),特征值都为正浮点数,单位为厘米。目标值为鸢尾花的分类(Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),Iris Virginica(维吉尼亚鸢尾))
2 数据预处理
- 导入数据并将其转化为panda类型
iris = load_iris() #加载鸢尾花数据集
df = pd.DataFrame(data=iris.data, columns=iris.feature_names) # 将数据集转化为panda
- 将标签值也加入df中
# 在数据集中加入一列,直接在df中给这一列赋值
df['species'] = iris.target
# 目标向量
target = df['species']
# 特征矩阵
data = df.drop('species', axis=1)
- 一般当如数据之后,需要查看数据集是否有缺失值,如果有,输出所在列
# 将数据的列名转化为列表
colnames = data.columns.tolist()
# isnull是判断是否为空,如果为空就等于0,不为空就为1,
# sum 是对于每一列求和,这样不为0的值就有空值
s = data.isnull().sum()
for i in range(len(s)):
if s[i] != 0:
print(colnames[i]) # 若有空值则输出所在列
本数据集是没有空值的,则不做多余的处理,若有空值,还需要进行空值填充
3 数据可视化
小提琴图就是外形像小提琴的一种图。这种图用来显示数据的分布和概率密度,可以看成是箱线图和密度图的结合。小提琴图的中间部分反映箱线图的信息,图的两侧反映出密度图的信息。小提琴图常用于建模前的EDA数据探索性分析环节。小提琴图的含义:
1 分布信息
小提琴图中间的黑色粗条用来显示四分位数。黑色粗条中间的白点表示中位数,粗条的顶边和底边分别表示上四分位数和下四分位数,通过边的位置所对应的y轴的数值就可以看到四分位数的值。
由黑色粗条延伸出的黑细线表示95%的置信区间。
2 概率密度信息
从小提琴图的外形可以看到任意位置的数据密度,实际上就是旋转了90度的密度图;小提琴图越宽,表示密度越大;可以展示出数据的多个峰值。
- 画出四个特征与鸢尾花种类的小提琴图
f, axes = plt.subplots(2, 2, figsize=(8, 8), sharex=True)
sns.despine(left=True)
sns.violinplot(x='species', y='sepal length (cm)', data=df, split=True, ax=axes[0, 0])
axes[0, 0].set_title('sepal length (cm) and species', fontsize=13)
sns.violinplot(x='species', y='sepal width (cm)', data=df, ax=axes[0, 1])
axes[0, 1].set_title('sepal width (cm) and species', fontsize=13)
sns.violinplot(x='species', y='petal length (cm)', data=df, ax=axes[1, 0])
axes[1, 0].set_title('petal length (cm) and species', fontsize=13)
sns.violinplot(x='species', y='petal width (cm)', data=df, ax=axes[1, 1])
axes[1, 1].set_title('petal width (cm) and species', fontsize=13)
plt.show()
结果如图所示
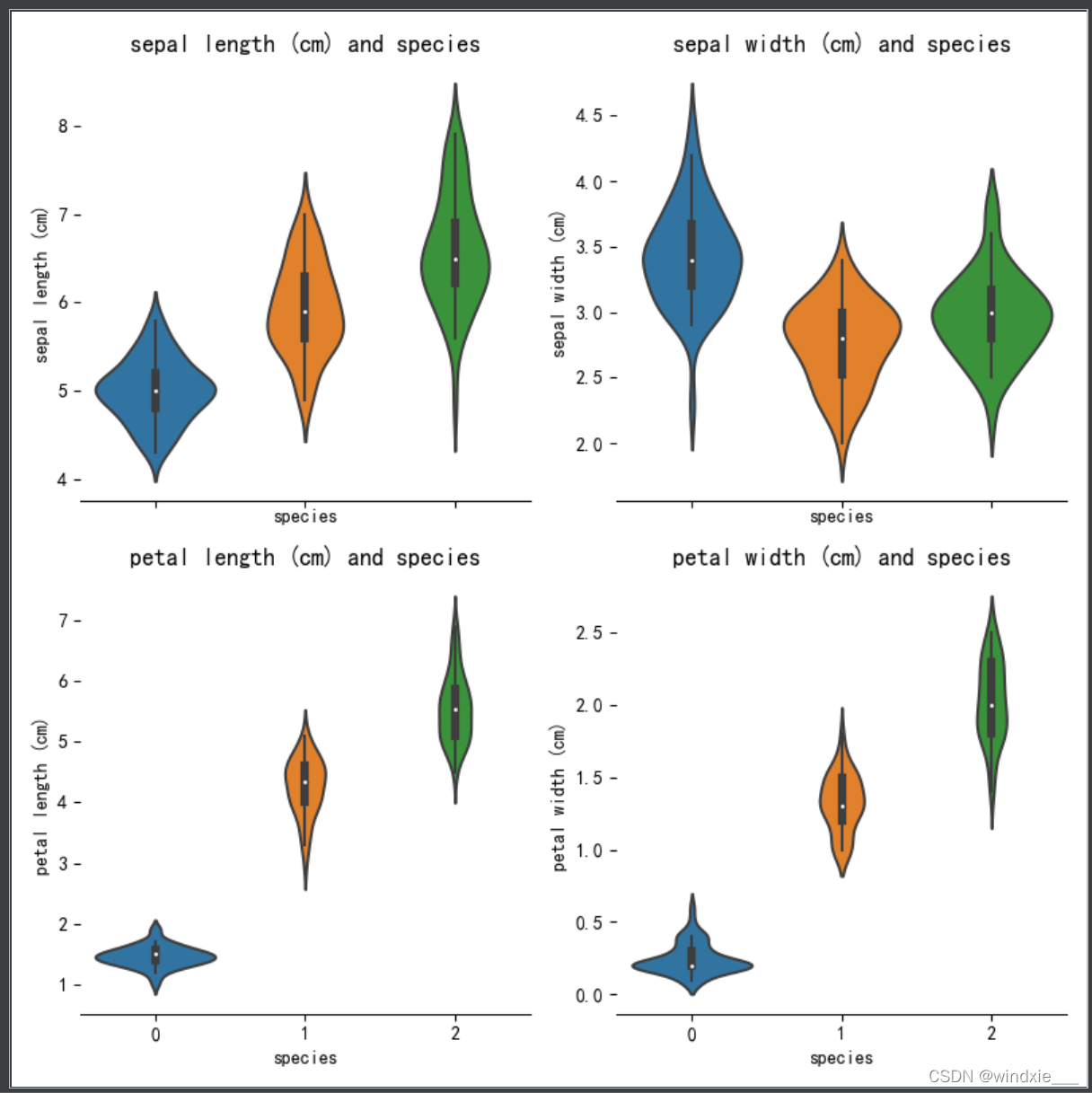
从中可以看出花萼长度和花萼宽度有很大一部分的重叠,不好区别三种类型的花,而花瓣长度和花瓣宽度重叠较小,能很好的区分三种类型,初步可以判定通过花瓣长度和花瓣宽度可以辨别花朵种类
- 计算四个特征的相关系数
# 计算四个特征的相关相关系数,就这么一句就计算出各个特征之间相关性了,,,,离谱,以前以为多高大上,结果一个corr()就没了
data_corr = data.corr()
# print(data_coor)
fig, ax = plt.subplots(figsize=(6, 6), facecolor='w')
sns.heatmap(data_corr, annot=True, vmax=1, square=True, cmap="Reds", fmt='.2g')
plt.title('相关性热力图')
plt.show()
结果如图所示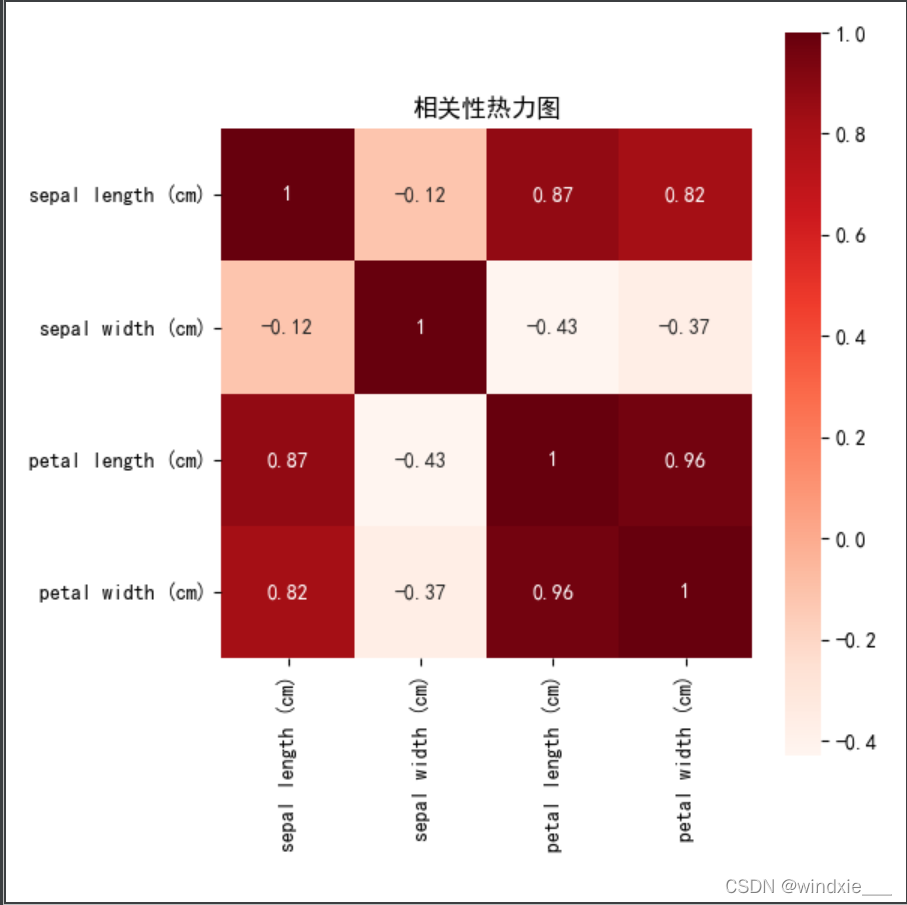
- 接下来进行数据划分
# 采用简单交叉验证将数据划分为训练集(70%)和测试集(30%)
train, test = train_test_split(df, test_size=0.3) # 给random_state参数赋值可以使得每次运行划分出来的数据集与上一次划分一样,随便赋什么值都行
# 将数据的种类和特征划分开
train_x = train[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']]
train_y = train.species
test_x = test[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']]
test_y = test.species
4 模型训练与测试
接下来使用了SVM支持向量机、逻辑回归、决策树、K折临近算法进行模型训练与验证,并计算预测准确率
# svm支持向量机
model = svm.SVC() # 调用SVM模型
model.fit(train_x, train_y) # 通过训练集来训练模型
prediction = model.predict(test_x) # 用测试集来预测模型
accuracy = metrics.accuracy_score(prediction, test_y)
print('The accuracy of the SVM is:', accuracy)
# 逻辑回归
model = LogisticRegression()
model.fit(train_x, train_y)
prediction = model.predict(test_x)
accuracy = metrics.accuracy_score(prediction, test_y)
print('The accuracy of the Logistic Regression is:', accuracy)
# 决策树
model = DecisionTreeClassifier()
model.fit(train_x, train_y)
prediction = model.predict(test_x)
accuracy = metrics.accuracy_score(prediction, test_y)
print('The accuracy of the Decision Tree is:', accuracy)
# K折临近算法
model = KNeighborsClassifier(n_neighbors=3)
model.fit(train_x, train_y)
prediction = model.predict(test_x)
accuracy = metrics.accuracy_score(prediction, test_y)
print('The accuracy of the KNN is:', accuracy)
结果如图所示
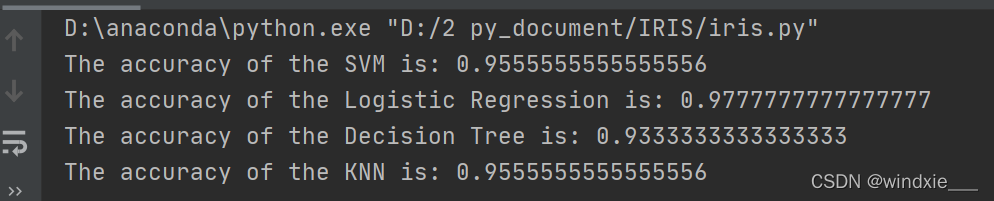
当然不同每次运行的数据集不一样,所得准确率也不一样,并且它们区分度也不是很大,后续还可以用别的模型继续优化
此博文结合了很多大佬的博客指导,初步入门,在此多谢各位大佬们

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)