超级简单,四步带你入门爬虫,爬取图片
四步带你入门爬虫,爬取图片本人还是学生,python小白。其实很多基础还不牢固,但是对爬虫比较有兴趣,在这里也希望能帮助大家入门爬虫,毕竟还是比较有趣。需要一些html基础,不过这个html也很简单。完整代码块import requestsfrom lxml import etreeimport osif __name__ == '__main__':url = 'https://pic.netb
四步带你入门爬虫,爬取图片
本人还是学生,python小白。其实很多基础还不牢固,但是对爬虫比较有兴趣,在这里也希望能帮助大家入门爬虫,毕竟还是比较有趣。需要一些html基础,不过这个html也很简单。
完整代码块
import requests
from lxml import etree
import os
if __name__ == '__main__':
url = 'https://pic.netbian.com/4kdongman/'
#爬取到页面源码数据
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36 Edg/90.0.818.49'
}
response = requests.get(url=url,headers=headers)
#手动设定编码
# response.encoding = 'utf-8'
# print(response)
page_text = response.text
# print(page_text)
#数据解析:src属性值 alt属性值
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="slist"]/ul/li')
# #创建一个文件夹
if not os.path.exists('./picLibs'):
os.mkdir('./picLibs')
for li in li_list:
img_src = 'https://pic.netbian.com'+li.xpath('./a/img/@src')[0]
img_name = li.xpath('./a/img/@alt')[0]+'.jpg'
#通用处理中文乱码解决方案
img_name = img_name.encode('iso-8859-1').decode('gbk')
# print(img_name,img_src)
#请求图片,进行持久化存储
img_data = requests.get(url=img_src,headers=headers).content
img_path = 'picLibs/'+img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功!!')
import requests
from lxml import etree
import os
下面是分析,只需四步。
这里是引入包,记得需要提前导入这些模块,不懂的可以评论区问问。
第一步
request 的作用是模拟客户端浏览强向服务器发出请求获得数据。
lxml etree是用于解析requests获得返回的网页数据,提取需要的信息。这里还有其余方法,与兴趣大家可以自己去了解。如正则表达式等等。
os用于后面创建一个存储图片的文件夹
url = 'https://pic.netbian.com/4kdongman/'
#爬取到页面源码数据
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36 Edg/90.0.818.49'
}
ulr里是我们需要需要访问的网站链接
headers是用于python伪装自己,模仿是一个浏览器发出的请求。
下面教你们怎么获取headers
以百度为例:
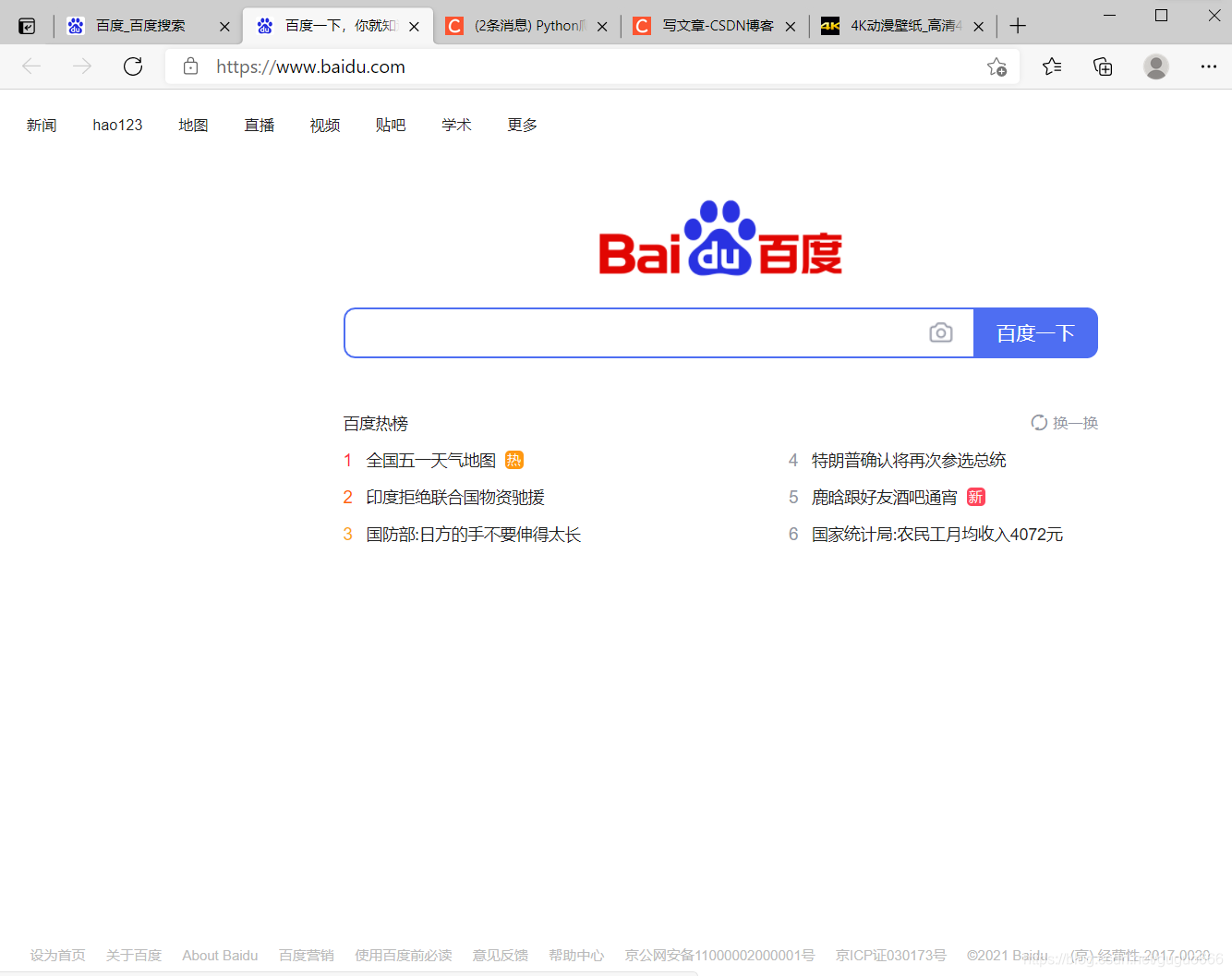
点击F12,找到Networ
的第一个响应,向下滑获取到 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36 Edg/90.0.818.49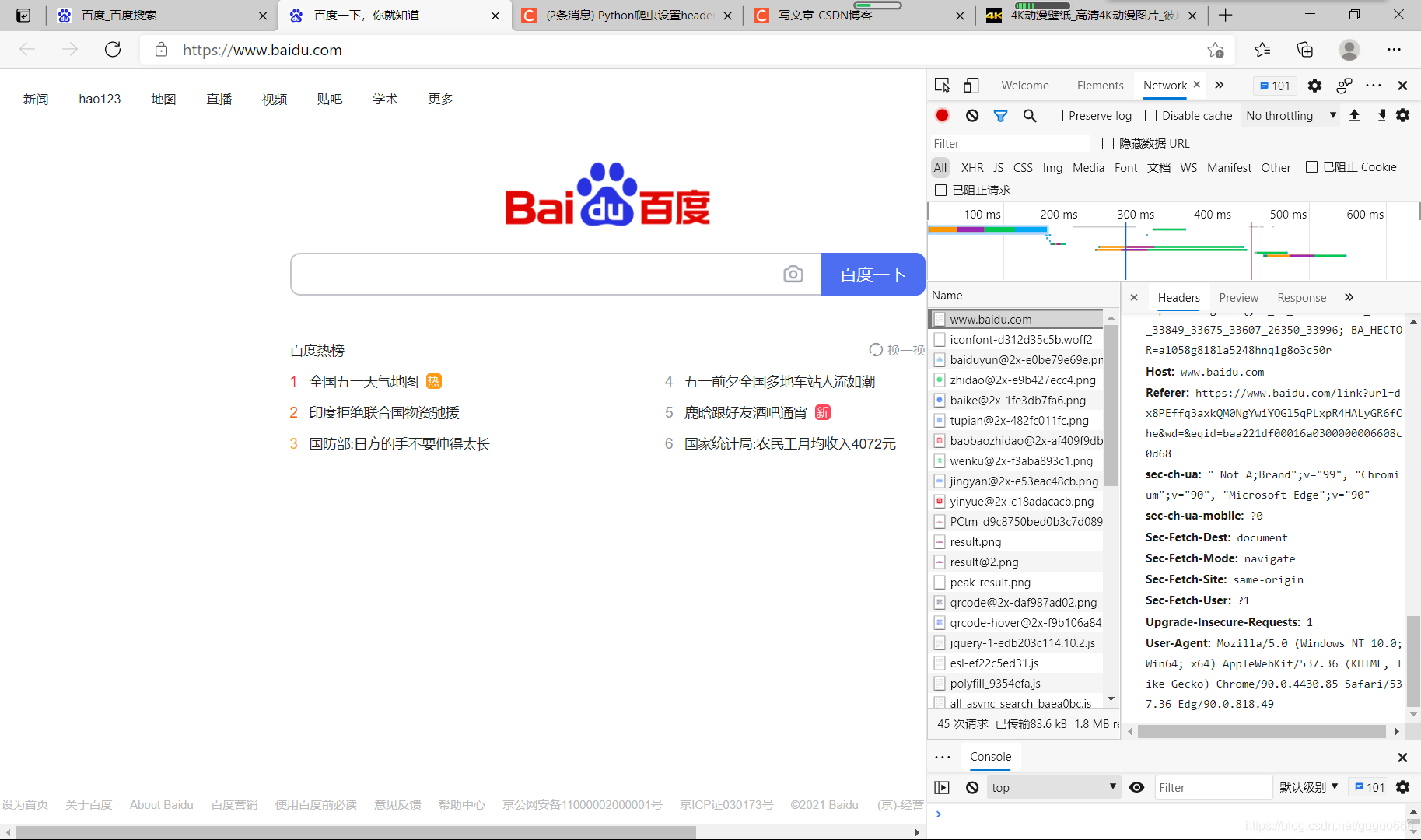
第二步
response = requests.get(url=url,headers=headers)
response这里是获取了requests利用get获取的指定网站的返回值
page_text = response.text
text将返回的值变为网页中代码形势,page_text获取text后的返回值
#数据解析:src属性值 alt属性值
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="slist"]/ul/li')
第三步
数据解析部分,为最重要
html解析
etree.HTML方法把html的文本内容解析成html对象,并对HTML文本进行自动修正。
.xpath是一种数据解析方法。
例如需要下列第一张图片,我们点击进去后发现第一张图片的链接(链接在第二张图上)是由该网站链接加上第一张图中该图a中href值拼接而成。因此我们想要获取某一张图片链接,直接将两者加起来就行。而该网站链接我们已经知道,因此难点就是获取每一张图对应a中的href值。
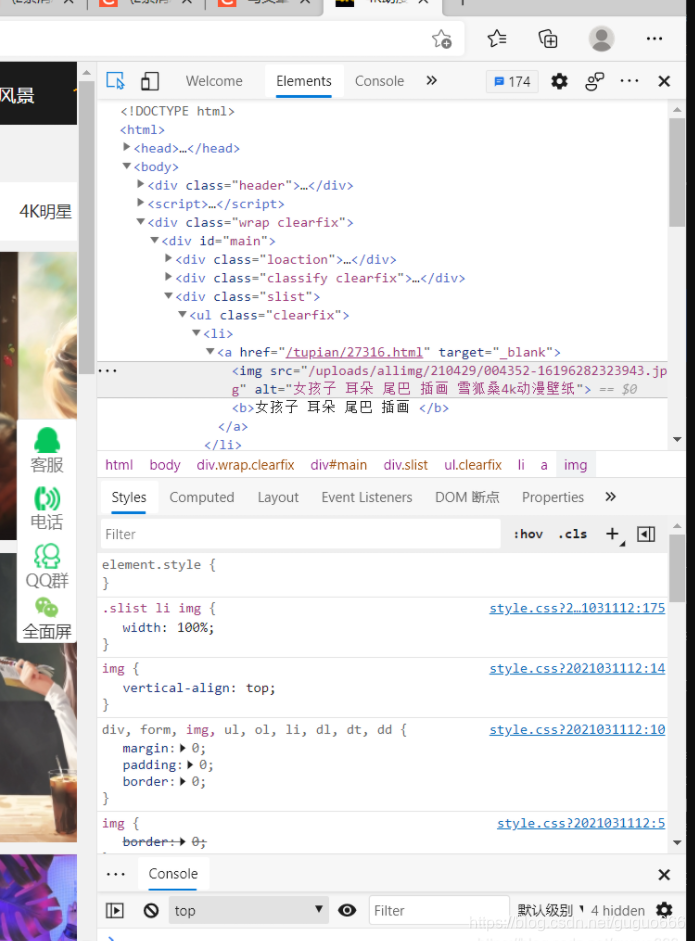
xpath就是实现此功能
li_list = tree.xpath(’//div[@class=“slist”]/ul/li’)
了解括号中含义:(/表示一个层级)
1.分析网站页面html后发现,a在li标签中,li在ul标签中,ul在属性值为slist的div标签中,而属性值为slist的div标签在html的下下个层级中。
2.因此括号里信息的含义是,从html开始的下下个层级中找到一个属性值为slist的div,再在里面找到ul标签,再在ul中找到li标签。
3.因此这里接收的是这一页的包含图片信息的所有li标签,至于为什么不直接获得a标签,是因为后面还可以利用li获取图片名字。
# #创建一个文件夹用于保存图片
if not os.path.exists('./picLibs'):
os.mkdir('./picLibs')
for li in li_list:
img_src = 'https://pic.netbian.com'+li.xpath('./a/img/@src')[0]
img_name = li.xpath('./a/img/@alt')[0]+'.jpg'
#通用处理中文乱码解决方案
img_name = img_name.encode('iso-8859-1').decode('gbk')
# print(img_name,img_src)
#请求图片,进行持久化存储
img_data = requests.get(url=img_src,headers=headers).content
img_path = 'picLibs/'+img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功!!')
for循环,每次获取一张图片。
img_src = ‘https://pic.netbian.com’+li.xpath(’./a/img/@src’)[0]
li.xpath(’./a/img/@src’)[0] 同理上面,获得每个li标签里a中的img中的src值
用@src获得,至于加[0]是因为返回的是一个标签,即取里面第一个值。加上原网页,就是每一张图片的的链接
img_name = li.xpath(’./a/img/@alt’)[0]+’.jpg’
获取每张图片的名字
img_name = img_name.encode(‘iso-8859-1’).decode(‘gbk’)
防止图片名字出现乱码,一般有两种预防方式,后面讲另一种,这里用的是.encode(‘iso-8859-1’).decode(‘gbk’)。
img_data = requests.get(url=img_src,headers=headers).content
访问拼接后的每一张图片呢网页地址,.content是将图片以二进制方式储存起来。
img_path = ‘picLibs/’+img_name
图片需要存储额文件地址
第四步
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功!!')
打开该文件地址,将获取的图片数据存进去,爬取完成。
这种方法只能获取一页的数据,大家可以想一下怎么获取多页的数据。
整个爬取就完成了,大家有什么疑问可以在评论区提出,欢迎交流。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)