python:pandas全DataFrame查询定位赋值数值所在行列
pandas行列操作:https://www.cnblogs.com/mrwuzs/p/11325205.html全表查询数值demo_df = pd.DataFrame({'Integer Feature': [0, 1, 2, 1], 'Categorical Feature': ['socks', 'fox', 'socks', 'box']})demo_df用for循环遍历for inde
·
pandas行列操作:
https://www.cnblogs.com/mrwuzs/p/11325205.html
pandas读取行列数据:
https://www.cnblogs.com/wynlfd/p/14024947.html
取出DataFrame里面指定的四列数据构成新DF
dfS = data[['A','B','C','D']]
print(dfS)
全DataFrame查询数值
demo_df = pd.DataFrame({'Integer Feature': [0, 1, 2, 1], 'Categorical Feature': ['socks', 'fox', 'socks', 'box']})
demo_df
用for循环遍历
for indexs in df.index:
for i in range(len(df.loc[indexs].values)):
if(df.loc[indexs].values[i] =='fox'):
print(indexs,i)
print(df.loc[indexs].values[i])
添加新的一列,该列数值为空值
用pandas直接是None
dfS["new"] =None
将空值全部改为0
dfS = df.fillna(0)
用numpy是nan
import pandas as pd
import numpy as np
df = pd.DataFrame({'A': ['K0', 'K0', 'K1', 'K2'],
'B': ['K0', 'K1', 'K0', 'K1'],
'C': ['A0', 'A1', 'A2', 'A3'],
'D': ['B0', 'B1', 'B2', 'B3']})
df['ZZ'] = np.nan
将指定值改为空值,比如将所有1改为空值
import numpy as np
//**********首先在这里遍历全部数据*************//
// 把指定值换成9,然后把9换成空值
df.replace("9", np.NaN, inplace=True)
检索全部DataFrame,将符合条件的值的列所在的索引输出到新的一列
# 新添加一列
dfS["ZZ"]=0
# 遍历全DF
for indexs in dfS.index:
for i in range(len(dfS.loc[indexs].values)):
if(dfS.loc[indexs].values[i] =='bbb'):
print(indexs,i)
# 查询到bbb就在ZZ里面赋值1
dfS.iloc[indexs,17] = i
print(dfS.head())
pandas.DataFrame中某数值在某行中第一次出现的索引号
dfS["ZZ"] = None
# 将每一行第一次出现的字符串的索引保存在ZZ列里面
ZuiHouyilie = 26
for indexs in dfS.index:
for i in range(len(dfS.loc[indexs].values)):
if(dfS.loc[indexs].values[i] ==1):
print(indexs,i)
dfS.iloc[indexs,ZuiHouyilie] = i
break
print(dfS.head())
pandas.DataFrame中某数值在某行中最后一次出现的索引号
dfS["ZZ"] = None
ZuiHouyilie = 26
for indexs in dfS.index:
for i in range(len(dfS.loc[indexs].values)):
if(dfS.loc[indexs].values[i] ==1):
print(indexs,i)
dfS.iloc[indexs,ZuiHouyilie] = i
print(dfS.head())
pandas.DataFrame中每一行某个数值出现的次数
# 将符合条件的数值修改为1,不符合的修改为0
ChaXunStr = 13311
for col in dfS.columns:
dfS.loc[dfS[col] != ChaXunStr,col] = 0
dfS.loc[dfS[col] == ChaXunStr,col] = 1
dfS
# 求和
# 增加新的一列数据,保存的是查询的那个数值的索引位置
# 第一次出现还是最后一次出现?最后一次!
dfS["ZZ"] = None
# 将查出来的索引位置存在ZZ所在的列
# 存的是最后一次出现的索引位置
ZuiHouyilie = 26
for indexs in dfS.index:
for i in range(len(dfS.loc[indexs].values)):
if(dfS.loc[indexs].values[i] ==1):
print(indexs,i)
dfS.iloc[indexs,ZuiHouyilie] = i
print(dfS.head())
# 只取求和结果那一列输出结果!
dfS['Times'] =dfS.apply(lambda x:x.sum(),axis =1) #对每一行求和,添加新的一行
dfS = dfS[['Times']]#只提取index和Times
dfS
dfS.to_csv("FSP22131chuxiancishu.csv")
pandas.dataframe根据ID列关联两个DataFrame
相当于excel中VLOOKUP 功能
# dfA列的长度比dfB的长度大!大的在前,小的在后
# outer表示并集,inner表示交集
dfS = dfA.merge(dfB,how='outer',on=['ID '])
dfS
统计全DATa Frame各个数值出现的次数
pieces = []
for col in dfS.columns:
tmp_series = df[col].value_counts()
tmp_series.name = col
pieces.append(tmp_series)
df_value_counts = pd.concat(pieces, axis=1)
FSP_3 = df_value_counts.fillna(0)
FSP_3["Total"] =FSP_3.apply(lambda x:x.sum(),axis =1)
print(FSP_3.head())
# 只打印Total列
FSP_3 = FSP_3[['Total']]
FSP_3.head()
使用pandas的read_csv时会将长度超过15位的字符串转换位科学计数法显示造成数据丢失。将数据转为str类型即可。
df['A'] = df['A'].astype(str)
去除DF中的英文或者符号
输入
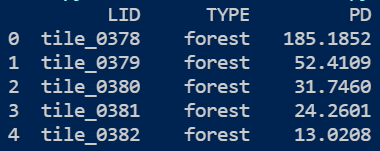
➡ 输出
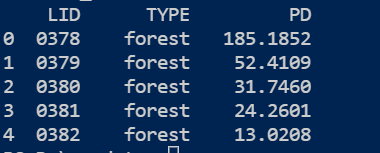
import pandas as pd
import string
string.punctuation
file_path = "1995_500.csv"
dfS = pd.read_csv(file_path)
print(dfS.head())
punctuation_string = string.punctuation
dfS['LID '].replace('tile_','',regex=True,inplace=True)
print(dfS.head())
# dfS.to_csv("1995_500_new.csv",mode='a')
将DF中所有小数点后位数保留3位
DF =DF.round(3)
# 分别对不同列保留小数位
#方法1
df.round({'A1': 1, 'A2': 2})
# 方法2
pd.Series([1, 0, 2], index=['A1', 'A2', 'A3'])
# 通过自定义函数设置小数位数,返回类型为object,以设置为二位小数为例
df.applymap(lambda x: '%.2f'%x)
对某列排序
dfS['LID '].sort(reverse=True)
Python的左闭右开原则
判断一个列表中是否有重复元素
ls = [1, 1, 2, 3]
if len(ls) == len(set(ls)):
print("无重复元素!")
else:
print("有重复!")

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)