python爬虫简单入门(爬网页文本信息)
环境python 3.8.2 Shell也可以使用PyCharm一、爬网页文本基本步骤1、请求目标网页,用requests请求,如果还没有安装,打开cmd,输入下面命令进行安装pip install requests通过requests.get(url)请求网页信息,.text可以获得网页文本内容,但还有标签。2、用BeautifulSoup解析请求到的网页内容,如果还没有安装,打开cmd,输入下
·
环境
python 3.8.2 Shell
也可以使用PyCharm
一、爬网页文本基本步骤
1、请求目标网页,用requests请求,如果还没有安装,打开cmd,输入下面命令进行安装
pip install requests
通过requests.get(url)请求网页信息,.text可以获得网页文本内容,但还有标签。
2、用BeautifulSoup解析请求到的网页内容,如果还没有安装,打开cmd,输入下面命令进行安装
pip install BeautifulSoup4
通过BeautifulSoup(texts,‘lxml’)可以对请求到的网页文本进行解析。
注意:texts是文本信息,lxml是一个解析器(安装参考),也可以使用html.parser解析器。
二、python代码
from bs4 import BeautifulSoup#解析requests请求到的HTML页面
#from w3lib.html import remove_tags_with_content
import requests#请求目标网页
url = 'https://www.bequgexs.com/8/8154/303304.html'
con = requests.get(url)
con.encoding = 'utf-8'
texts = con.text
print(con)
print(texts)
result = BeautifulSoup(texts,'lxml')#html.parser
#print(result)
div1 = result.find('div',attrs={'class':'bookname'})
div_zj = div1.find('h1')
print(div_zj.text)
div2 = result.find('div',attrs={'id':'content'})
#print(div2)
div_nr = div2.text.replace('\xa0'*4,'\n\n\xa0\xa0')
div_nr = div_nr.replace('(《》)','')
f = open("赘婿第一章.doc",mode="a",encoding="utf-8")
#a:把之前爬取的数据保存下来
#在windows下面,新文件的默认编码是gbk,而前面我们设置了utf-8
f.write(div_nr)
#div_nr = div_nr.replace('天才一秒记住本站地址:[笔趣阁]','')
#div_nr = div_nr.replace('https://www.bequgexs.com/最快更新!无广告!','')
print(div_nr)
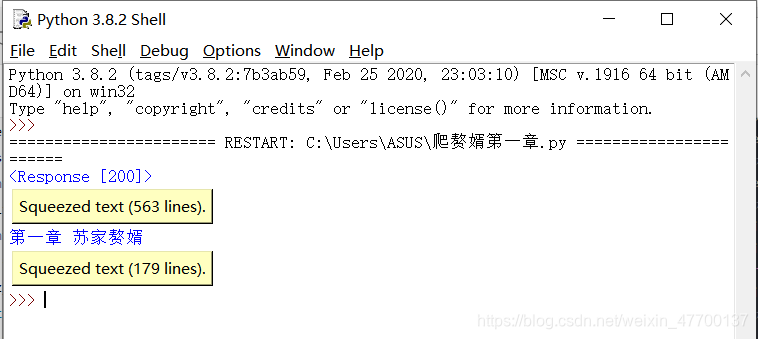
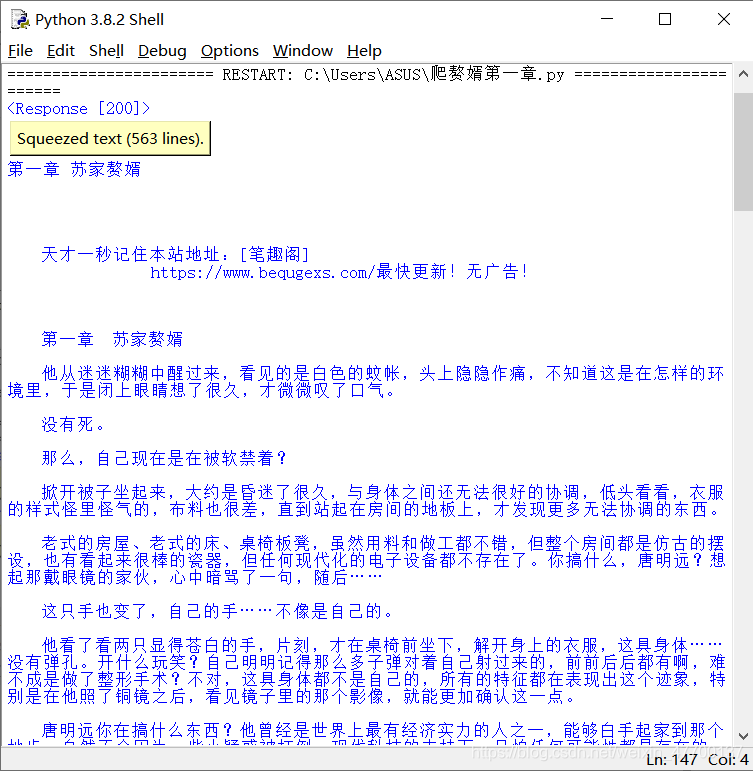
结果

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)