二维码原理解析,生成一个二维码需要这些知识
/ 今日科技快讯 /近日,在英伟达取消以400亿美元收购英国芯片设计公司ARM的计划后,ARM宣布将在全球范围内裁员,大约涉及1000名员工。ARM在声明中表示:“与其他公司一样,...

/ 今日科技快讯 /
近日,在英伟达取消以400亿美元收购英国芯片设计公司ARM的计划后,ARM宣布将在全球范围内裁员,大约涉及1000名员工。ARM在声明中表示:“与其他公司一样,ARM也在不断审查商业计划,确保公司在市场机遇和成本约束之间取得合理平衡。不幸的是,这次裁员计划涉及ARM在全球范围内的所有员工。”ARM方面表示,计划将在全球范围内裁员12%到15%,共涉及大约1000名员工,其中大部分是在英国和美国工作的员工。但ARM并没有明确说明不同地域的具体裁员人数。
/ 作者简介 /
本篇文章来自红鲤鱼鲤驴与驴的投稿,文章主要分享了他对二维码原理的理解以及二维码的实战演练,相信会对大家有所帮助!同时也感谢作者贡献的精彩文章。
红鲤鱼鲤驴与驴的博客地址:
https://juejin.cn/user/2960298998247624
/ 背景 /
传统的一维码(条形码)所携带的信息量有限,如 EAN-13 码仅能容纳 13 位阿拉伯数字,更多的信息只能依赖数据库的支持,离开了预先建立的数据库,这种条形码就没有意义了,因此,在一定程度上也限制了条形码的应用范围。基于这个原因,在 20 世纪 80 年代出现了二维码。
一句话总结:一维码所携带信息量太少,基于这个原因,出现了二维码。
/ 定义 /
二维码 (2-dimensional bar code),是用某种特定的几何图形按一定规律在平面(二维方向上)分布的黑白相间的图形。—— 二进制01矩阵(黑1 白0)
/ 分类 /
堆叠式/行排式二维条码
堆叠式/行排式二维条码又称堆积式二维条码或层排式二维条码,其编码原理是建立在一维条码基础之上,按需要堆积成二行或多行。它在编码设计、校验原理、识读方式等方面继承了一维条码的一些特点,识读设备与条码印刷与一维条码技术兼容。但由于行数的增加,需要对行进行判定,其译码算法与软件也不完全相同于一维条码。有代表性的行排式二维条码有:Code 16K、Code 49、PDF417、MicroPDF417 等。
简单来说,堆叠式二维码就是有多行条形码(一维码)拼凑而成的图形。
举个🌰:

矩阵式二维码
最流行莫过于QR CODE ,我们常说的二维码就是它了。矩阵式二维条码(又称棋盘式二维条码)它是在一个矩形空间通过黑、白像素在矩阵中的不同分布进行编码。在矩阵相应元素位置上,用点(方点、圆点或其他形状)的出现表示二进制“1”,点的不出现表示二进制的“0”,点的排列组合确定了矩阵式二维条码所代表的意义。矩阵式二维条码是建立在计算机图像处理技术、组合编码原理等基础上的一种新型图形符号自动识读处理码制。具有代表性的矩阵式二维条码有:Code One、MaxiCode、QR Code、 Data Matrix、Han Xin Code、Grid Matrix 等。
这边来介绍一下生活中最常用的码——矩阵式二维码中的QRCode。
/ 认识QR-Code /
首先,QRCode总共有40个版本(Version), 每个版本一个尺寸,每一个版本之间相差4位二进制。
版本1:21 * 21,版本2 :25 * 25, ...... ,版本40:177 * 177。

计算公式
边长 d = 17 + 4 * Version
结构

定位图案
Position Detection Pattern是定位图案,用于标记二维码的矩形大小,定位整个二维码矩阵。(左上,右上,左下的三个大正方形)
exp
为什么是3个,不是4个?
3个已经能框定一个正方形,4个纯属浪费。
那不是对角线2个定位符就能框定一个正方形了,为什么还要3个?
在三个定位符的情况下,二维码的数据识别是从没有定位符的右下角进行的,因此只有3个定位符的时候才能准确定义一个二维码的识别方向(如下图);4个定位符不行,因为它4个角都长一个样;两个定位符也不行,因为另外两个角不含定位符。无法知道从哪个角读取。
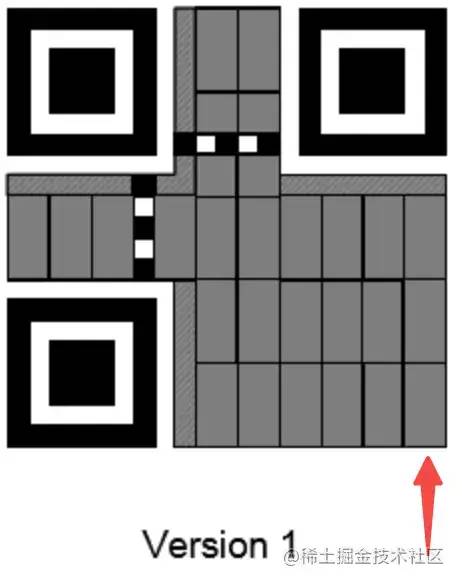
Timing Patterns也是用于定位的。原因是二维码有40种尺寸,尺寸过大了后需要有根标准线,不然扫描的时候可能会扫歪了。
Alignment Patterns 只有Version 2以上(包括Version2)的二维码需要这个,同样是为了定位用的。
功能数据
Format Information,格式信息。存在于所有尺寸中,存放格式化数据;
Version Information,版本信息。用于 Version 7 以上,需要预留两块 3×6 的区域存放部分版本信息;
数据内容
剩余部分存储数据内容。
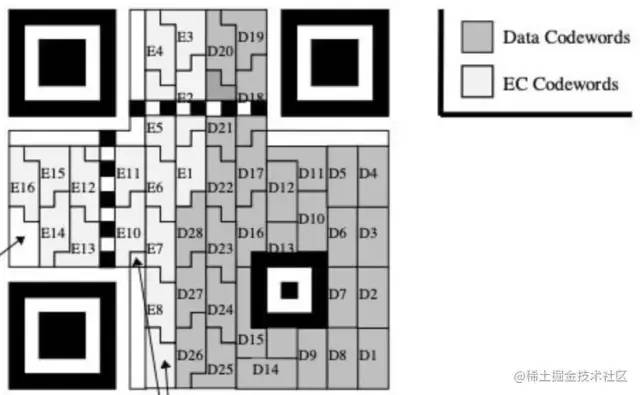
Data Code, 数据码;(偏右半区 下图灰色data区)
Error Correction Code, 纠错码;(偏左半区 下图白色Error Correct区)
编码模式(前六项)
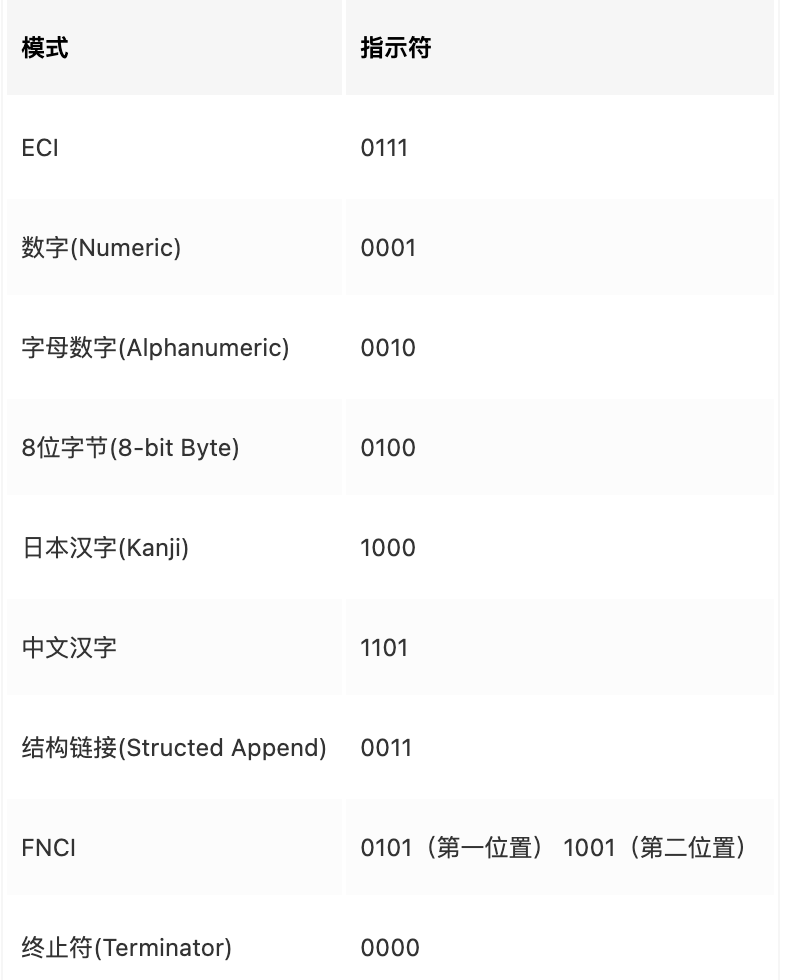
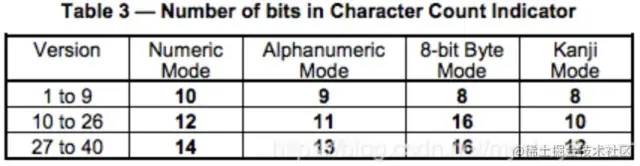
table3:对应版本和对应编码模式下,一组数据转化成的二进制位数(下面会用到,客官别急)
简单介绍其中两种常用的编码模式:
(1) Numeric mode 数字编码:0~9。数字串按每三位一拆分,如果需要编码的数字的个数不是3的倍数,那么,最后剩下的1或2位数会被转成4或7bits,则其它的每3位数字会被编成 10,12,14bits,编成多长还要看二维码的尺寸(如上表中Table 3)
举个🌰:在Version 1 尺寸的二维码,纠错级别为 H,编码:01234567
将上述数字按每3个一组拆分成3组:(012) (345) (67)
参照上述table3,Version 1 二维码的数字编码应转换为 10bits 的二进制数字,所以将上面的三组数据转化成012→0000001100,345→0101011001, 67→1000011;
将三组二进制数据串起来:0000001100 0101011001 1000011
将数字个数转化成二进制,上树字串有8个数,所以把8转化为二进制为:8→0000001000
查编码模式表,数字编码模式二进制数为0001
将步骤5和步骤4的得到的 编码模式 和 数字个数的二进制数加到步骤3的数据二进
制数之前, 得到编码结果:0000001000 0000001100 0101011001 1000011
(2) Alphanumeric mode 字符编码:包含0-9,A-Z(没小写),符号$ % * + – . / : 包括空格。映射成如下的索引表,所以每个符号最终映射成的是一个45进制的数.
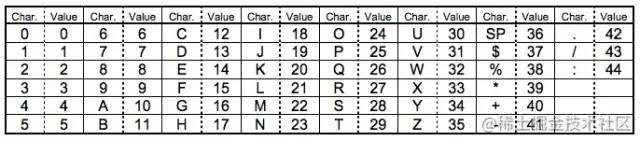
编码流程
编码的过程是把字符两两分组,然后转成对应的45进制,然后转成11bits的二进制。如果最后有一个落单的,那就转成6bits的二进制。而编码模式和字符的个数需要根据不同的Version尺寸编成9,11或13个二进制(参考上表中Table 3)。
举个🌰:在Version 1的尺寸下,编码:AE-86。
从字符索引表中找到 AE-86 这五个字条的索引 (10,14,41,8,6)
两两分组:(10,14) (41,8) (6)
把每一组的45进制转成11bits的二进制(落单的转6bits):
(10, 14) 10 * 45 + 14 = 464 转成 00111010000
(41, 8) 41 * 45 + 8 = 1853 转成 11100111101
(6) 等于 6 转成 000110
exp:这里说明下为什么是11位二进制,因为两位45进制最大是45² - 1 = 2024,而11位二进制刚好是Math.pow(2, 11) - 1 = 2047,所以11位二进制刚好能够容纳2位45进制
把这些二进制连接起来:00111010000 11100111101 000110
把字符的个数转成二进制 (Version 1-H为9 bits ):5个字符,5转成 000000101
在头上加上编码标识 0010 和上步的个数编码:0010 000000101 00111010000 11100111101 000110
结束符和补齐符
结束符
假如我们有个HELLO WORLD的字符串要编码,根据上面的示例二,我们可以得到下面的编码:

加上结束符:

然后按8bits重排,如果最后不是8的倍数要在后面补0,当前例子需要后面补2个0。
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101
01000011 010000(00)exp:为啥是8的倍数?因为下图二维码中一个小方块为1个字节,占8位,所以二进制位数也必须是8的倍数。
补齐符
最后,如果如果还没有达到我们最大的bits数的限制,我们还要加一些补齐码(Padding Bytes),Padding Bytes就是重复下面的两个bytes:11101100 00010001 (这两个二进制转成十进制是236和17,至于为啥是这俩,笔者也不清楚)关于每一个Version的每一种纠错级别的最大Bits限制,需要翻看二维码标准。
假设我们需要编码的是Version 1的Q纠错级,那么,其最大需要104个bits,而我们上面只有80个bits,所以,还需要补24个bits,也就是需要3个Padding Bytes,我们就添加三个,于是得到下面的编码:
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101
01000011 01000000 (11101100 00010001 11101100)exp:如果没有补齐符,会造成二维码中间大片面积空白,导致识别困难;所以为什么我们看到的二维码不会出现中间空了一大块的原因 就是 这个补齐符的作用
纠错码
位置:偏二维码左半区
作用:在二维码部分数据区域部分区域被覆盖的情况下,可以通过纠错区的纠错数据通过里德-所罗门算法(Reed-Solomon)对数据区域进行恢复。这就是为什么有的时候,把二维码的部分区域盖住,扫码器仍然能够识别二维码的原因,因为他能通过纠错区的数据对数据进行恢复啊
下表为二维码的四个纠错级,对应的纠错率。

纠错率计算规则:
举个🌰:在二维码版本和纠错级确定的情况下,其实它所能容纳的码字总数和纠错码字数也就确定了,比如:版本10,纠错等级时H时,总共能容纳346个码字,其中224个纠错码字。
就是说二维码区域中大约1/3的码字时冗余的。对于这224个纠错码字,它能够纠正112个替代错误(如黑白颠倒)或者224个据读错误(无法读到或者无法译码),这样纠错容量为:112/346=32.4%,也能对应上表中的纠错率。
纠错码计算规则:
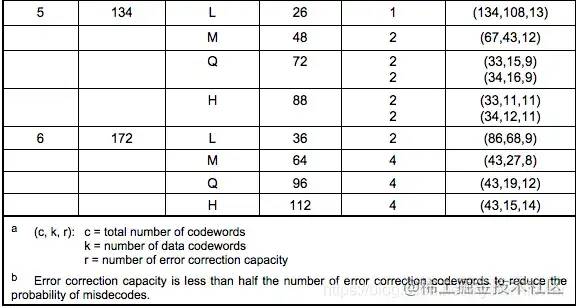
举个🌰:
如上图Version 5 + Q纠错级:需要4个Blocks(2个Blocks为一组,共两组),头一组的两个Blocks中各15个bits数据 + 各 9个bits的纠错码
注:表中的codewords就是一个8bits的byte。最后一例中的(c, k, r )的公式为:c = k + 2 * r,因为后脚注解释了,纠错码的容量小于纠错码的一半。
下图给一个Version 5-Q的示例(图中为10进制,可见每一块的纠错码有18个codewords,也就是18个8bits的二进制数)(二维码的纠错码主要是通过Reed-Solomon error correction(里德-所罗门纠错算法)来实现的,感性去可以自己去研究一下,反正我不会。)

穿插放置
接下来,我们要把数据码和纠错码的各个codewords交替放在一起。交替的规则如下:把每个块的第一个codewords拿出来按顺序排列好,然后按列来取,如此类推。
例如,上述示例中的Data Codewords如下:
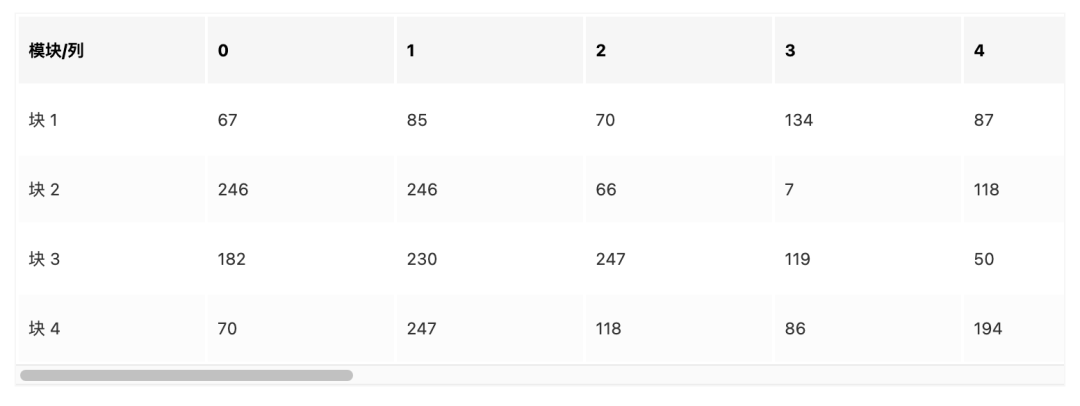
完整表格可以阅读原文进行查看
按照规则取:
67, 246, 182, 70, 85,246,230 ,247 ,70,66,247,118,……… ……… ,38,6,50,17,7,236。
对于上面示例的纠错码,也同样处理。
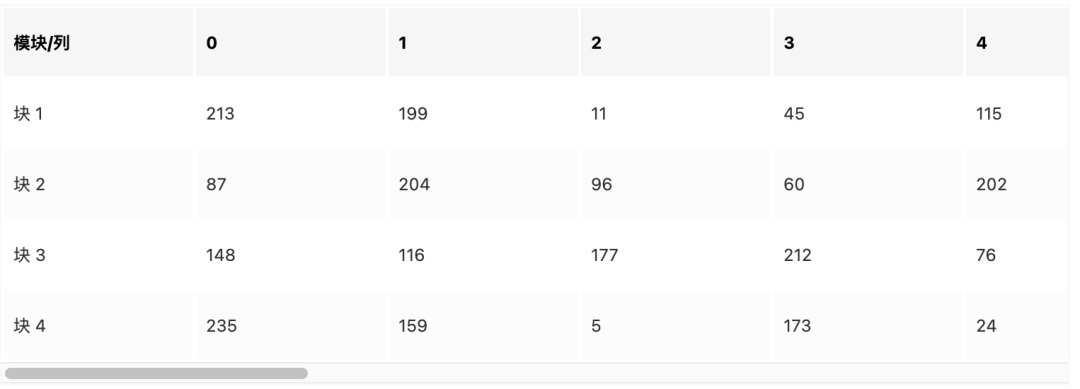
完整表格可以阅读原文进行查看
按照规则取:
213,87,148,235,199,204,116,159,…… …… 39,133,141,236
然后,把纠错码放在数据码之后组合到一起,就得到我们的数据区。
67, 246, 182, 70, 85, 246, 230, 247, 70, 66, 247, 118, 134, 7, 119, 86, 87, 118, 50, 194, 38, 134, 7, 6, 85, 242, 118, 151, 194, 7, 134, 50, 119, 38, 87, 16, 50, 86, 38, 236, 6, 22, 82, 17, 18, 198, 6, 236, 6, 199, 134, 17, 103, 146, 151, 236, 38, 6, 50, 17, 7, 236, ( 213, 87, 148, 235, 199, 204, 116, 159, 11, 96, 177, 5, 45, 60, 212, 173, 115, 202, 76, 24, 247, 182, 133, 147, 241, 124, 75, 59, 223, 157, 242, 33, 229, 200, 238, 106, 248, 134, 76, 40, 154, 27, 195, 255, 117, 129, 230, 172, 154, 209, 189, 82, 111, 17, 10, 2, 86, 163, 108, 131, 161, 163, 240, 32, 111, 120, 192, 178, 39, 133, 141, 236)
/ 画二维码 /
Position Detection Pattern 定位标记
把定位标记画在图的左上、左下、右上三个角上。不管二维码的尺寸(Version)是多大,这三个定位标记的大小和位置都是固定的。
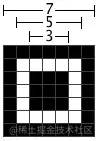
Alignment Pattern 校正标记
校正标记的大小也是固定,位置和数量参考标准里的定义。

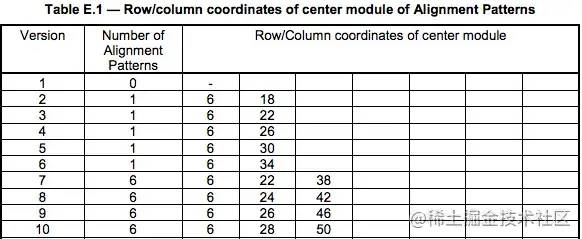
根据上面的表格中,Version8对应的位置是(6,24,42)。

exp:二维码越大,校正符号越多,因为越大的二维码越容易失真,所以需要更多的校正符去校正
Timing Pattern 定时标记
定时标记的规则比较简单,在(6,6)向左和向下按白黑的规则绘制虚线,到定位标记就停止。

Format Information 格式信息
格式信息的绘制区域在下图蓝色的部分。
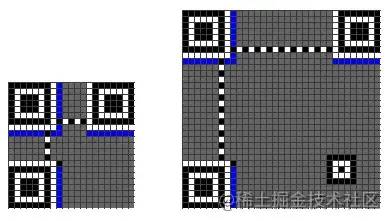
格式信息是一个15 bits的信息,每一个bit的位置如下图所示,这15个bits会在不同的位置绘制两次。

上图中的Dark Module是固定出现的。
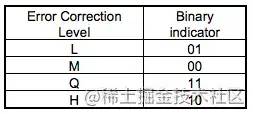
15个bits的数据中包含:
5个数据bits:
2个bits表示使用的Error Correction Level 纠错等级
-
3个bits表示使用什么样的Mask
10个纠错bits:主要通过BCH Code来计算
然后这15个bits需要和101010000010010进行XOR操作,避免纠错级别选择了00然后Mask选择了000,导致数据区域的5个bits都是白色,增加扫描器的识别难度。
举个栗子:

Version Information 版本信息
在Version 7之后,需要有这个编码,对应下图蓝色的部分。

Version Information一共是18个bits,其中包括6个bits的版本号以及12个bits的纠错码,下面是一个示例:

同样的,这18个bits数据也会被绘制在两个区域:
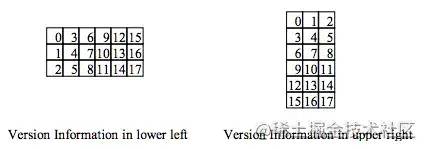
exp:解释一下为什么低版本的不需要格式区域,想象一下版本1的二维码边长为21,上面那条边 去掉2个定位符的边长总共14 剩下 7,再去掉定位旁边的2个空列白格 剩下5,再去掉格式信息的1个格子,还剩4个格子。4个格子再去放需要占据3个格子的版本信息,还剩一格,存放其他数据的区域过少。
所以低版本二维码为了腾出更多区域给数据区,放弃了版本区。
那低版本的二维码怎么知道 我这个二维码到底是哪个版本的呢?
可以用三个定位符的位置计算二维码的边长,从而得反推出二维码的版本(比如边长21对应版本1)
数据码和纠错码
然后填的是我们上面计算出来的最终编码(数据码 + 纠错码),右下角开始沿着橙色线绘制;下图右下角为二维码中每个块中二进制排列结构,橙色线与左侧二维码的橙色线条对应
Mask 掩码图案

经过上面的操作后,图就填好了,但是因为数据的不均衡可能会出现有大面积的黑或者白色块,导致扫描识别困难。所以,还需要做一个Masking的操作,取Mask和绘制出来的图案进行XOR。
总共8个mask矩阵,与原二维码分别XOR,最终选择 XOR后惩罚得分最低的mask模型 作为该二维码的mask模型,并把mask模型类型对应的3bit二进制数据写入格式区域。举个🌰:
初始二维码矩阵

mask模型
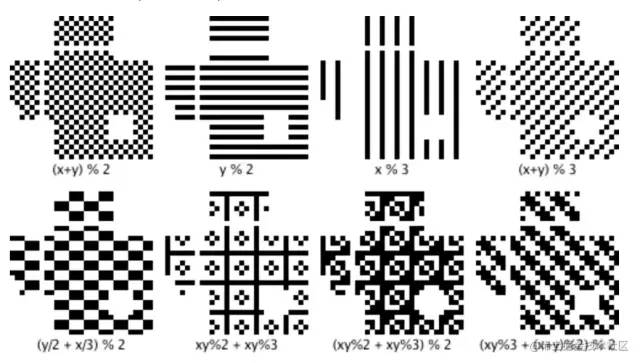
用原始二维码矩阵和8个mask模型分别XOR,得到一下8个结果矩阵。

计算每个矩阵的乘法分,取其中惩罚分最低的作为最终的二维码矩阵(惩罚分越高代表二维码的识别度越低)
上面的例子中,计算出来模型0 的惩罚分最低,所以应该选择Mask Pattern 0 作为我们最终生成的二维码矩阵。
惩罚分计算规则
Rule 1
逐行检查,如果有5个连续的像素,增加3点惩罚。
如果在前5个之后还有连续的像素,则后续每个相同颜色的像素再增加1点惩罚。
按相同的条件检查每一行、每一列,然后把惩罚分数加起来。

Rule 2
查找 >= 2x2 的相同颜色的模块。QR码规范规定,对于大小为m×n的实色块,惩罚分数为3×(m-1)×(n-1)
Rule 3
寻找**黑白黑黑黑白黑**的模式,查找任意一边存在4个白色块的模式,如下图:

每次发现有这样的模式时,惩罚分+40(可能是因为影响定位标识的识别:从定位符的重心传一条线,这条线经过的区域满足黑白黑黑黑白黑模型)。(下图有2个这样的模式)

Rule 4
计算黑白模块的比例,计算的规则如下:
计算总像素个数
计算黑色像素个数
计算黑色像素模块的占比百分比
计算上面的百分比中的前和后5的整数倍的百分比,举个栗子,对于43%,前向5的整数倍是40,后向5的整数倍是45.
用步骤4得到的前向/后向百分比,和50做差,求绝对值。例如:|40-50|=10,|45-50|=5。
对步骤5得到的数除以5,例如:10/5=2,5/5=1.
取步骤6中较小的数乘以10,得到最后的分数。例如:上例中1更小,所以分数是1*10=10
所以为什么我们看到的二维码总是黑白交错的,不会出现大面积的连续黑块或者连续白块,就是因为这个mask XOR 校正的关系。
推荐阅读:
欢迎关注我的公众号
学习技术或投稿


长按上图,识别图中二维码即可关注

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)