
机器学习----乳腺癌数据集的逻辑回归
机器学习----乳腺癌数据集的逻辑回归
| 1. 介绍乳腺癌数据集
现在我们已经建立了逻辑回归工作原理的基础,并且您已经学会了使用sklearn。您可以参见《机器学习----使用Sklearn构建逻辑回归模型》。我们已经构建了为分类数据集构建逻辑回归模型的工具,我们将介绍一个新数据集。
在乳腺癌数据集中,每个数据点都有来自乳房肿块图像的测量值以及它是否癌变。目标是使用这些测量来预测肿块是否癌变。该数据集直接内置在 scikit-learn 中,因此我们不需要读取 csv。让我们从加载数据集开始,对数据及其格式进行分析。
from sklearn.datasets import load_breast_cancer
cancer_data = load_breast_cancer()返回的对象(我们存储在 cancer_data 变量中)是一个类似于 Python 字典的对象。我们可以使用 keys 方法查看可用的键。
print(cancer_data.keys())我们将从查看 DESCR 开始,它提供了数据集的详细描述。
print(cancer_data['DESCR'])我们可以看到有 30 个特征,569 个数据点,目标是恶性(癌性)或良性(非癌性)。对于每个数据点,我们都有乳房质量的测量值(半径、纹理、周长等)。
对于 10 次测量中的每一次,都会计算多个值,因此我们有平均值、标准误差和最差值。这会产生 10 x 3 或 30 个总特征。
Tips :在乳腺癌数据集中,有几个特征是基于其他列计算的。弄清楚要计算哪些附加特征的过程是特征工程。
| 2. 使用pandas加载乳腺癌数据集
让我们从 cancer_data 对象中提取特征和目标数据。首先,特征数据与“数据”键一起存储。当我们查看它时,我们看到它是一个 numpy 数组,有 569 行和 30 列。那是因为我们有 569 个数据点和 30 个特征。
以下是返回数据的 numpy 数组:
cancer_data['data']让我们用shape看它是一个569行30列的数组。
cancer_data['data'].shape
# (569, 30)为了将其放入 Pandas DataFrame 并使其更易于阅读,我们需要列名。这些与“feature_names”键一起存储。
现在我们可以用我们所有的特征数据创建一个 Pandas DataFrame。
df = pd.DataFrame(cancer_data['data'], columns=cancer_data['feature_names'])
print(df.head())Result:
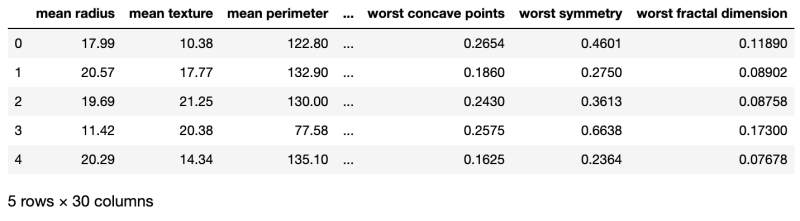
我们可以看到 DataFrame 中有 30 列,因为我们有 30 个特征。输出被截断以适合屏幕。我们使用了 head 方法,所以我们的结果只有 5 个数据点。
我们仍然需要将目标数据放在我们的 DataFrame 中,可以通过 'target' 键找到。我们可以看到目标是一个 1 和 0 的一维 numpy 数组。
print(cancer_data['target'])如果我们查看数组的形状,我们会发现它是一个具有 569 个值的一维数组(这是我们拥有的数据点的数量)。
print(cancer_data['target'].shape)为了解释这些 1 和 0,我们需要知道 1 或 0 是良性还是恶性。这是由 target_names 给出的
print(cancer_data['target_names'])这给出了数组 ['malignant' 'benign'] ,它告诉我们 0 表示恶性,1 表示良性。让我们将此数据添加到 Pandas DataFrame 中。
df['target'] = cancer_data['target']
print(df.head())您可以运行下述代码以查看结果:
import pandas as pd
from sklearn.datasets import load_breast_cancer
cancer_data = load_breast_cancer()
df = pd.DataFrame(cancer_data['data'], columns=cancer_data['feature_names'])
df['target'] = cancer_data['target']
print(df.head())Result:
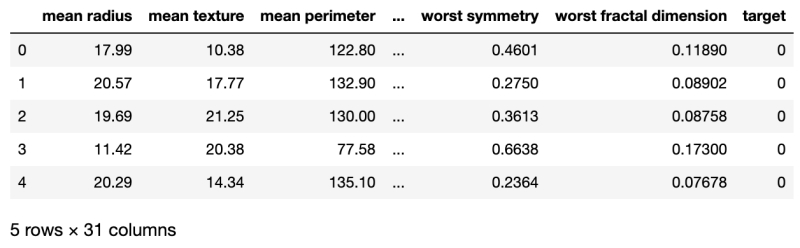
Tips : 仔细检查您是否正确解释了布尔列,这一点很重要。在我们的例子中,0 表示恶性,1 表示良性。
| 3. 构建逻辑回归模型
现在我们已经查看了我们的数据并将其转换为一种舒适的格式,我们可以构建我们的特征矩阵 X 和目标数组 y,这样我们就可以构建一个逻辑回归模型。
X = df[cancer_data.feature_names].values
y = df['target'].values现在我们创建一个 Logistic Regression 对象并使用 fit 方法来构建模型。
model = LogisticRegression()
model.fit(X, y)当我们运行此代码时,我们会收到收敛警告。这意味着模型需要更多时间来找到最优解。一种选择是增加迭代次数。您也可以切换到不同的求解器,这就是我们要做的。求解器是模型用来求解直线方程的算法。您可以在 Logistic Regression 文档中查看可能的求解器
model = LogisticRegression(solver='liblinear')
model.fit(X, y)让我们看看模型对我们数据集中的第一个数据点的预测。回想一下,predict 方法需要一个二维数组,所以我们必须将数据点放在一个列表中。
model.predict([X[0]])所以模型预测第一个数据点是良性的。为了查看模型在整个数据集上的表现如何,我们使用 score 方法来查看模型的准确性。
model.score(X, y)
# 0.9595782073813708Tips : 使用我们开发的工具,我们可以为任何分类数据集构建模型。
| 6.1 完整代码
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
cancer_data = load_breast_cancer()
print(cancer_data.keys())
# print(cancer_data['DESCR'])
# cancer_data['data'].shape
df = pd.DataFrame(cancer_data['data'], columns=cancer_data['feature_names'])
# print(df.head())
# print(cancer_data['target'].shape)
# print(cancer_data['target_names'])
df['target'] = cancer_data['target']
X = df[cancer_data.feature_names].values
y = df['target'].values
model = LogisticRegression(solver='liblinear')
model.fit(X, y)
model.predict([X[0]])
print(model.score(X, y))当然,你也可以访问github存储库来下载代码:
https://github.com/Zesheng-Wang/Machine-Learning
References:
Hoss Belyadi, Alireza Haghighat, in Machine Learning Guide for Oil and Gas Using Python, 2021https://www.ibm.com/topics/logistic-regressionhttps://en.wikipedia.org/wiki/Logistic_regressionhttps://towardsdatascience.com/machine-learning-classifiershttps://www.statisticssolutions.com/free-resources/directory-of-statistical-analyses/what-is-logistic-regression/
| 7.1 写在最后
学习不是一蹴而就的,机器学习所涉及的内容非常宽泛,除了一些数学公式以外,我们也算站在巨人的肩膀上了。作为一种面向应用的方式方法,在不同的场景下同样有着不同的解决方式,后面我们会介绍一些模型评估的方法。希望本篇的内容可以帮你了解什么是sklearn以及逻辑回归,在项目中理解机器学习,而不是做一个调包侠,希望可以帮你打下坚实的基础。
勘误:
由于我自己也不是资深编程高手,在创作此内容时尽管已经力求精准,查阅了诸多资料,还是难保有所疏漏,如果各位发现有误可以公众号内留言,欢迎指正。
你要偷偷学Python,然后惊艳所有人。

-END-
感谢大家的关注
你关心的,都在这里

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)