Pandas 找出并查看数据中的重复行
dup_row = data.duplicated(subset=['用户编号', '统计日期'])data.insert(0, 'is_dup', dup_row)data[data['is_dup'] == True]
·
示例:
df = pd.DataFrame({
'用户编号': ['小明', '小明', '小王', '小美', '小张', '小王'],
'统计日期': ['11.12', '11.12', '11.12', '11.12', '11.13', '11.13'],
'消费金额': [4, 3, 5, 10, 2, 5]
})
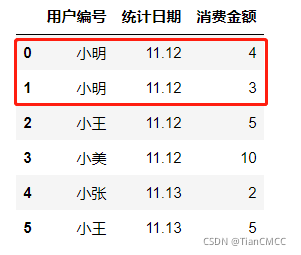
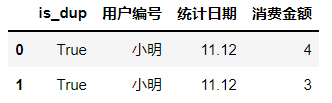
可见用户 “小明”,在11.12当日产生的消费金额不一致,因此判断为异常数据,将其找出:
dup_row = df.duplicated(subset=['用户编号', '统计日期'], keep=False)
df.insert(0, 'is_dup', dup_row)
df[df['is_dup'] == True]

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)