Pandas-去重函数drop_duplicates()详解
可使用drop_duplicates()函数对数据进行去重处理,drop_duplicates()函数的语法格式如下,主要对各个参数进行讲解
·
Panda DataFrame 对象提供了一个数据去重的函数 drop_duplicates(),本节对该函数的用法做详细介绍。
格式介绍
drop_duplicates()函数的语法格式如下:
data.drop_duplicates(subset=['a','b','b'],keep='first',inplace=True)
参数说明如下:
subset:表示要进去重的列名,默认为 None。
keep:有三个可选参数,分别是 first、last、False,默认为 first,表示只保留第一次出现的重复项,删除其余重复项,last 表示只保留最后一次出现的重复项,False 则表示删除所有重复项。
inplace:布尔值参数,默认为 False 表示删除重复项后返回一个副本,若为 Ture 则表示直接在原数据上删除重复项。
示例数据
代码:
import pandas as pd
data = pd.DataFrame({
'a':[2,1,1,1,1,1,2],
'b':[1,3,2,4,1,1,5],
'c':[1,3,2,4,1,1,3],
'd':[1,3,2,4,1,1,8]
})
print (data)
打印结果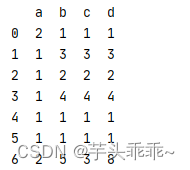
实际应用
1、默认保留第一次出现的重复项
代码:
import pandas as pd
data = pd.DataFrame({
'a':[2,1,1,1,1,1,2],
'b':[1,3,2,4,1,1,5],
'c':[1,3,2,4,1,1,3],
'd':[1,3,2,4,1,1,8]
})
data_del = data.drop_duplicates()
print (data_del)
打印结果
2、删除所有重复项
代码:
import pandas as pd
data = pd.DataFrame({
'a':[2,1,1,1,1,1,2],
'b':[1,3,2,4,1,1,5],
'c':[1,3,2,4,1,1,3],
'd':[1,3,2,4,1,1,8]
})
data_del = data.drop_duplicates(keep=False)
print (data_del)
打印结果
3、根据指定列标签去重
代码:
import pandas as pd
data = pd.DataFrame({
'a':[2,1,1,1,1,1,2],
'b':[1,3,2,4,1,1,5],
'c':[1,3,2,4,1,1,3],
'd':[1,3,2,4,1,1,8]
})
data_del = data.drop_duplicates(subset=['b'],keep=False)
print (data_del)
打印结果
4、指定多列同时去重
代码:
import pandas as pd
data = pd.DataFrame({
'a':[2,1,1,1,1,1,2],
'b':[1,3,2,4,1,1,5],
'c':[1,3,2,4,1,1,3],
'd':[1,3,2,4,1,1,8]
})
data_del = data.drop_duplicates(subset=['b','c'],keep=False)
print (data_del)
打印结果

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)