负采样(Negative Sampling)
来源:Coursera吴恩达深度学习课程在Word2Vec文章中,我们见到了Skip-Gram模型如何构造一个监督学习任务,把上下文映射到了目标词上,它如何学到一个实用的词嵌入(word embedding)。但是它的缺点(downside)就在于softmax计算起来很慢。因此,学习一个改善过的学习问题叫做负采样(negative sampling),它能做到与Skip-Gram模型相似的事情,
来源:Coursera吴恩达深度学习课程
在Word2Vec文章中,我们见到了Skip-Gram模型如何构造一个监督学习任务,把上下文映射到了目标词上,它如何学到一个实用的词嵌入(word embedding)。但是它的缺点(downside)就在于softmax计算起来很慢。因此,学习一个改善过的学习问题叫做负采样(negative sampling),它能做到与Skip-Gram模型相似的事情,但是用了一个更加有效的学习算法,让我们来看看。

在本视频中大多数的想法源于这篇论文:Distributed Representations of Words and Phrases and their Compositionality。
如上图,我们在这个算法中要做的是构造一个新的监督学习问题,那么问题就是给定一对单词,比如orange和juice,我们要去预测这是否是一对上下文词-目标词(context-target)。
在这个例子中orange和juice就是个正样本(标为1),那么orange和king就是个负样本(标为0)。我们要做的就是采样得到一个上下文词和一个目标词,把中间这列(juice,king,book....)叫做词(word)。生成样本的步骤如下:先抽取一个上下文词,然后在一定词距内(比如说正负10个词距)选一个目标词,①这就是生成这个表的第一行,即orange– juice -1的过程。②然后为了生成一个负样本,用相同的上下文词,再在字典中随机选一个词,在这里随机选了单词king,标记为0。③以此类推,再随机选一个词,于是orange–book–0。④我们再选点别的,orange可能正好选到the,记为0。⑤还是orange,再可能正好选到of这个词,标记为0,注意of被标记为0,即使of的确出现在orange词的前面。
总结一下,生成这些数据的方式是我们选择一个上下文词(orange),再选一个目标词(juice),这(上图绿色横框)就是表的第一行,它给了一个正样本(上下文,目标词,标签为1)。然后我们要做的是给定几次,比如K次。如果我们从字典中随机选到的词,正好出现在了词距内,比如说在上下文词orange正负10个词之内,也没事。
接下来我们将构造一个监督学习问题,其中学习算法输入x,输入这对词(context-word),要去预测目标的标签,即预测输出y(0或者1)。因此问题就是给定一对词,像orange和juice,你觉得它们会一起出现么?你觉得这两个词是通过对靠近的两个词采样获得的吗?这个算法就是要分辨这两种不同的采样方式,这就是如何生成训练集的方法。
那么如何选取K?Mikolov等人推荐小数据集的话,K从5到20比较好。如果数据集很大,K就选小一点。对于更大的数据集K选2到5,数据集越小K就越大(larger values of K for smaller data sets)。那么在这个例子中,我们就用K = 4。
下面我们讲解从x映射到y的监督学习模型:

如上图,首先介绍softmax模型,公式如下:

用记号c表示上下文词(context-word),记号t表示可能的目标词(target),用y表示0和1,表示是否是一对上下文-目标词。我们要做的就是定义一个逻辑回归模型,给定输入的c,t对的条件下,y = 1的概率,即:
![]()
这个模型基于逻辑回归模型,对每一个可能的目标词有一个参数向量θ_t和另一个参数向量e_c,即每一个可能上下文词的的嵌入向量,用这个公式估计y = 1的概率。如果你有K个样本,你可以把这个看作1/K的正负样本比例,即每一个正样本你都有K个对应的负样本来训练一个类似逻辑回归的模型。
在神经网络中,输入one-hot向量,再传递给E,通过两者相乘得到嵌入向量,这样转化为10,000个可能的逻辑回归分类问题,预测词汇表中这些可能的单词。把这些看作10,000个二分类逻辑回归分类器,但并不是每次迭代都训练全部10,000个,我们只训练其中的5个,我们要训练对应真正目标词那一个分类器,再训练4个随机选取的负样本,这就是K = 4的情况。不使用一个巨大的10,000维度的softmax是因为计算成本很高,而是把它转变为10,000个二分类问题,每个都很容易计算,每次迭代我们要做的只是训练它们其中的5个,一般而言就是 K + 1个,其中K个负样本和1个正样本。这个算只需更新K + 1个逻辑单元,K + 1个二分类问题,相对而言每次迭代的成本更低。
这个技巧就叫负采样。你有一个正样本词orange和juice,然后需要特意生成一些负样本,所以叫负采样,即用这4个负样本训练,4个额外的二分类器,在每次迭代中你选择4个不同的随机的负样本词去训练你的算法。
这个算法有一个重要的细节就是如何选取负样本?

(1)一个办法是对中间的这些词进行采样,即候选的目标词,根据其在语料中的经验频率(empirical frequency)进行采样,就是通过词出现的频率对其进行采样。但问题是这会导致你在like、the、of、and诸如此类的词上有很高的频率。(2)另一个极端就是用1除以词汇表总词数,即1/|v|,均匀且随机地抽取负样本,这对于英文单词的分布是非常没有代表性的。(3)所以论文的作者Mikolov等人根据经验,他们发现这个经验值的效果最好,它位于这两个极端的采样方法之间,既不用经验频率,也就是实际观察到的英文文本的分布,也不用均匀分布,他们采用以下方式:

上式的f(w_i)是观测到的在语料库中的某个英文词的词频(frequency of the word),通过3/4次方(the power of three-fourths)的计算,使其处于完全独立的分布和训练集的观测分布两个极端之间。Andrew并不确定这是否有理论证明,但是很多研究者现在使用这个方法,似乎也效果不错。
总结一下,我们已经知道了在softmax分类器中如何学到词向量,但是计算成本很高,可以尝试通过将其转化为一系列二分类问题来有效地学习词向量。当然和深度学习的其他领域一样,有很多开源的实现。
说明:记录学习笔记,如果错误欢迎指正!转载请联系我。

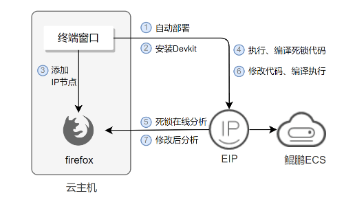
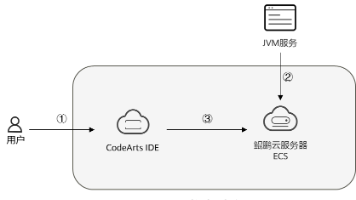
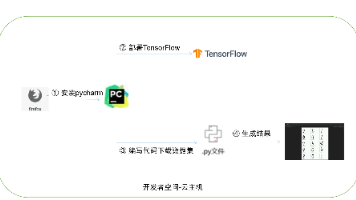
华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐
 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)