深度对抗神经网络(DANN)笔记
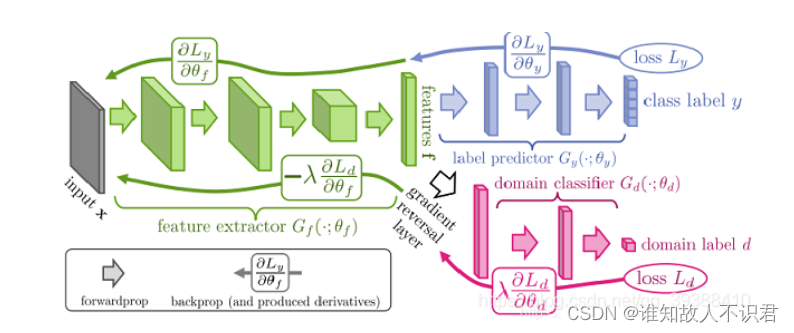
一 总体介绍DANN是一种迁移学习方法,是对抗迁移学习方法的代表方法。基本结构由特征提取层f,分类器部分c和对抗部分d组成,其中f和c其实就是一个标准的分类模型,通过GAN(生成对抗网络)得到迁移对抗模型的灵感。但此时生成的不是假样本,而是假特征,一个足以让目标域和源域区分不开的假特征。而领域判别器D其实是个标准的二分类分类器,0是源域,1是目标域。它本身的目标是区分源域和目标域,而我们想要的结果
一 总体介绍
DANN是一种迁移学习方法,是对抗迁移学习方法的代表方法。基本结构由特征提取层f,分类器部分c和对抗部分d组成,其中f和c其实就是一个标准的分类模型,通过GAN(生成对抗网络)得到迁移对抗模型的灵感。但此时生成的不是假样本,而是假特征,一个足以让目标域和源域区分不开的假特征。
而领域判别器D其实是个标准的二分类分类器,0是源域,1是目标域。它本身的目标是区分源域和目标域,而我们想要的结果是使判别器越来越分不出数据特征来自源域还是目标域,感觉起来这很矛盾。但其实我们引入一个梯度反转层就可以完美避免这个问题。
引入梯度反转层(GRL),分类器c和判别器d朝着优化分类器效果的方向反向传播优化梯度。有了梯度反转层,简单的说就是判别器d反向传播时,梯度更新前引入了一个“ - ”。这样就可以同时满足判别器和我们需求的一致性。
下面是DANN的基本网络图。
二 UDTL代码库中的DANN网络
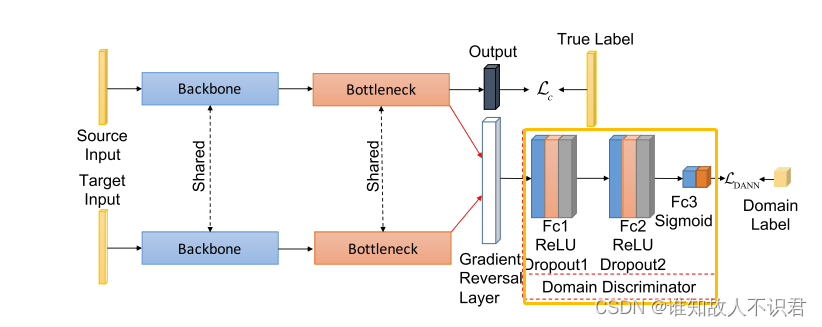
对抗网络部分代码。
from torch import nn
import numpy as np
def calc_coeff(iter_num, high=1.0, low=0.0, alpha=10.0, max_iter=10000.0):
return np.float(2.0 * (high - low) / (1.0 + np.exp(-alpha * iter_num / max_iter)) - (high - low) + low)
### 如果self.trade_off_adversarial == 'Step',则调用此函数得到coeff的值,不然self.trade_off_adversarial == 'Cons',则coeff是个固定的值
###coeff——————coeff = self.lam_adversarial 其中trade_off_adverial充当域分类器部分的学习率随着迭代过程会逐渐递减——————学习率
def grl_hook(coeff):#补充连接,因为是引入块,需要连接到model层的梯度: grad.clone()
def fun1(grad):
return -coeff * grad.clone()
return fun1
class AdversarialNet(nn.Module):
def __init__(self, in_feature, hidden_size,max_iter=10000.0, trade_off_adversarial='Step', lam_adversarial=1.0):
super(AdversarialNet, self).__init__()
self.ad_layer1 = nn.Sequential(
nn.Linear(in_feature, hidden_size),
nn.ReLU(inplace=True),
nn.Dropout(),
)
self.ad_layer2 = nn.Sequential(
nn.Linear(hidden_size, hidden_size),
nn.ReLU(inplace=True),
nn.Dropout(),
)
self.ad_layer3 = nn.Linear(hidden_size, 1)
self.sigmoid = nn.Sigmoid()
# parameters
self.iter_num = 0
self.alpha = 10
self.low = 0.0
self.high = 1.0
self.max_iter = max_iter
self.trade_off_adversarial = trade_off_adversarial
self.lam_adversarial = lam_adversarial
self.__in_features = 1
def forward(self, x):
if self.training:
self.iter_num += 1
if self.trade_off_adversarial == 'Cons':
coeff = self.lam_adversarial
elif self.trade_off_adversarial == 'Step':
coeff = calc_coeff(self.iter_num, self.high, self.low, self.alpha, self.max_iter) #学习率
else:
raise Exception("loss not implement")
x = x * 1.0
x.register_hook(grl_hook(coeff))#register_hook的作用:即对x求导时,对x的导数进行操作,并且register_hook的参数只能以函数的形式传过去,
#grl_hook(coeff)则返回的是梯度 * “——”梯度反转层作用
##register_hook的作用:对x求导,并将梯度保存下来,这样可以作为参数通过优化器通过反向传播过程进行更新优化,实现DANN所需效果
x = self.ad_layer1(x)
x = self.ad_layer2(x)
y = self.ad_layer3(x)
y = self.sigmoid(y)
return y
def output_num(self):
return self.__in_features#输出通道是1 代表域判别值0:源域 1:目标域
以上是赵志斌老师UDTL代码中的对抗网络部分的介绍,用于故障诊断数据。
这里要声明的是对于AdversarialNet网络而言,一维的数据和二维数据都可以拿来直接使用,实质上它仅仅是多出了一个二分类判别器和一个梯度反转层而已。
ZhaoZhibin/UDTL: Source codes for the paper "Applications of Unsupervised Deep Transfer Learning to Intelligent Fault Diagnosis: A Survey and Comparative Study" published in TIM (github.com)![]() https://github.com/ZhaoZhibin/UDTL
https://github.com/ZhaoZhibin/UDTL
三 网络的其他写法
这里博主还找到了另外一种的对抗网络写法。
import torch.nn as nn
from functions import ReverseLayerF#从functions中导入梯度反转层这一类
class CNNModel(nn.Module):
def __init__(self):
super(CNNModel, self).__init__()
self.feature = nn.Sequential()
self.feature.add_module('f_conv1', nn.Conv2d(3, 64, kernel_size=5))#这里是因为数据是mnist数据所以输入通道为3
self.feature.add_module('f_bn1', nn.BatchNorm2d(64))
self.feature.add_module('f_pool1', nn.MaxPool2d(2))
self.feature.add_module('f_relu1', nn.ReLU(True))
self.feature.add_module('f_conv2', nn.Conv2d(64, 50, kernel_size=5))
self.feature.add_module('f_bn2', nn.BatchNorm2d(50))
self.feature.add_module('f_drop1', nn.Dropout2d())
self.feature.add_module('f_pool2', nn.MaxPool2d(2))
self.feature.add_module('f_relu2', nn.ReLU(True))
#上面是backbone部分也是网络的特征提取部分
self.class_classifier = nn.Sequential()
self.class_classifier.add_module('c_fc1', nn.Linear(50 * 4 * 4, 100))
self.class_classifier.add_module('c_bn1', nn.BatchNorm1d(100))
self.class_classifier.add_module('c_relu1', nn.ReLU(True))
self.class_classifier.add_module('c_drop1', nn.Dropout())
self.class_classifier.add_module('c_fc2', nn.Linear(100, 100))
self.class_classifier.add_module('c_bn2', nn.BatchNorm1d(100))
self.class_classifier.add_module('c_relu2', nn.ReLU(True))
self.class_classifier.add_module('c_fc3', nn.Linear(100, 10))
self.class_classifier.add_module('c_softmax', nn.LogSoftmax(dim=1))
#上面是源域的分类器部分,只要是要对源域数据进行有效的分类
self.domain_classifier = nn.Sequential()
self.domain_classifier.add_module('d_fc1', nn.Linear(50 * 4 * 4, 100))
self.domain_classifier.add_module('d_bn1', nn.BatchNorm1d(100))
self.domain_classifier.add_module('d_relu1', nn.ReLU(True))
self.domain_classifier.add_module('d_fc2', nn.Linear(100, 2))
self.domain_classifier.add_module('d_softmax', nn.LogSoftmax(dim=1))
#上面是领域判别器部分,主要任务是要区分出源域和目标域
def forward(self, input_data, alpha):
input_data = input_data.expand(input_data.data.shape[0], 3, 28, 28)
feature = self.feature(input_data)
feature = feature.view(-1, 50 * 4 * 4)
reverse_feature = ReverseLayerF.apply(feature, alpha)
#前向网络中注意到,reverse_feature是通过ReverseLayerF.apply将feature进行反向的梯度计算。
class_output = self.class_classifier(feature)
domain_output = self.domain_classifier(reverse_feature)
#并将处理过的reverse_feature特征给domain_classifer进行域判别。
return class_output, domain_output
对应的ReverseLayerF部分代码:
from torch.autograd import Function
class ReverseLayerF(Function):
@staticmethod
def forward(ctx, x, alpha):
ctx.alpha = alpha
return x.view_as(x)
@staticmethod
def backward(ctx, grad_output):
output = grad_output.neg() * ctx.alpha
####grad_output.neg()梯度取负操作,反向内容的核心。
return output, None代码地址:https://github.com/fungtion/DANN_py3
通过介绍以上两种不同写法的对抗网络模型,相信你也可以看到对抗网络的核心其实很简单。
仅仅是多出了一个领域判别器和一个梯度反转层。
但采用对抗网络作为迁移网络方法又能很好的解决很多域迁移领域的问题,特别是在域之间的差异较大的情况时,往往要比以MMD(最大均值差异)为代表的度量学习方法效果要好。
以上是我学习过程中对DANN进行的一些总结工作,欢迎评论区讨论交流。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)