【Python数据分析实战】豆瓣读书分析(含代码和数据集)
@[TOC]豆瓣一.导入数据二.数据清洗2.1清理null值2.2清洗出版时间列2.3转换评分及平均数量的数据类型2.4清洗页数列2.5清洗价格列2.6去除书名重复的数据2.7哪个出版社的书籍评分较高?2.8哪些书值得一读?2.9作者排名(10部作品及以上)三.数据分析与可视化3.1各年作品出版数量折线图3.2各价位作品数量直方图3.3各出版社出版作品数量条形图&评分折线图3.4作者作品评
·
@[TOC]豆瓣
一.导入数据
数据集:
链接:douban.csv
提取码:pmls
#加载需要使用的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#读取数据
df=pd.read_csv(r'/PythonTest/Data/book_douban.csv',index_col=0)
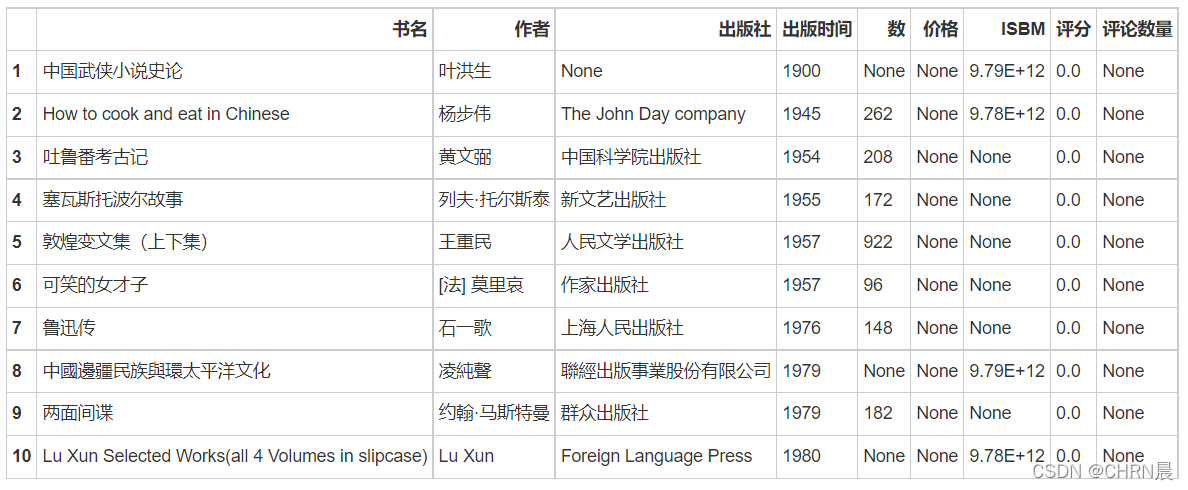
#查看前十行
df.head(10)
```
```python
df.info()

二.数据清洗
#重命名‘数’列为‘页数’
df=df.rename(columns={'数':'页数'})
#重置索引
df.reset_index(drop=True,inplace=True)
# 查看矩阵形状
df.shape
# 查看评分的统计信息
df.describe()
2.1清理null值
# 将’none‘转换为null
df.replace('None',np.nan,inplace=True)
# 查看缺失值情况
df.isnull().sum()
# 去除'ISBM'列
del df['ISBM']
# 去除指定列含有空值的行
df.dropna(axis=0,subset=['作者','出版社','出版时间','页数','价格','评分','评论数量'],
how='any',inplace=True)
# 重置索引
df.reset_index(drop=True,inplace=True)
# 确认是否还有空值
df.isna().sum()

2.2清洗出版时间列
从数据集中可以发现出版时间的数据格式多样,有1999,2012/12,1923-4,2019年六月,因此需要提取出其年份
# 为了便于统计,通过正则提取出版时间的年份
import re
df['出版时间']=df['出版时间'].str.replace(' ','')
for index,row in df.iterrows():
num=re.findall('\d+',row[3])
num=''.join(num)[0:4]
df.iloc[index,3]=num
# 将出版时间转换为整数型
df.drop(df[df['出版时间'].str.len()!=4].index,axis=0,inplace=True)
df['出版时间']=df['出版时间'].astype(np.int32)
# 发现出版时间超出实际时间的数据,将其清除
df.drop(df[df['出版时间']>2019].index,inplace=True)
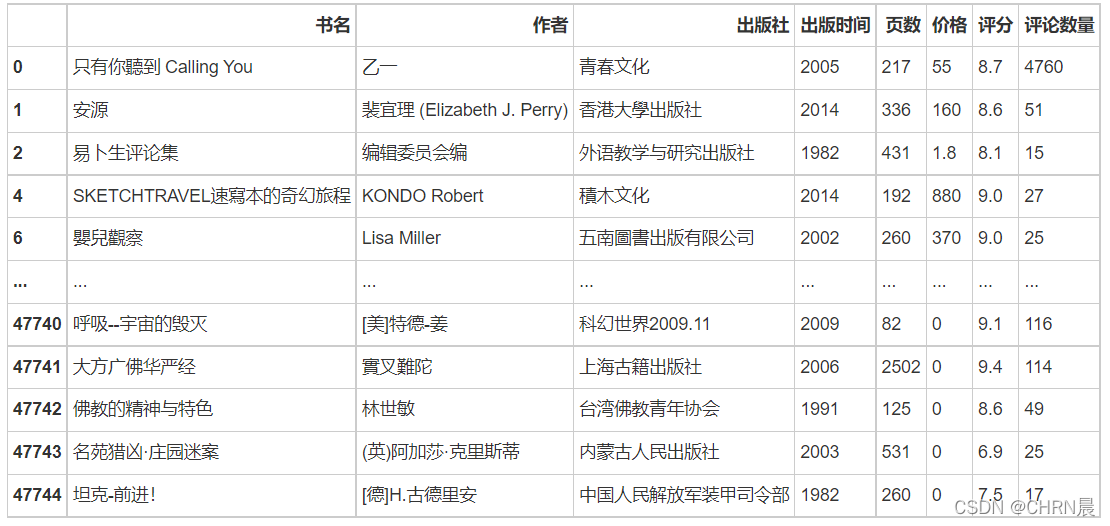
2.3转换评分及平均数量的数据类型
# 转换数据类型
df['评分']=df['评分'].astype(float)
df['评论数量']=df['评论数量'].astype(np.int32)
2.4清洗页数列
# 查看页数是否含有小数点的情况
df['页数'].str.contains('\.').value_counts()
结果:
False 46173
True 7
Name: 页数, dtype: int64
# 规范页数的格式,去除含有其他字符的数据比如‘.’
df['页数']=df['页数'].apply(lambda x:x.replace(',','').replace(' ',''))
df.drop(df[~(df['页数'].str.isdecimal())].index,axis=0,inplace=True)
# 转换页数的格式
df['页数']=df['页数'].astype(np.int32)
# # 清除页数为0的数据
df.drop((df[df['页数']==0]).index,inplace=True)
2.5清洗价格列
# 规范价格的格式,去除价格不是纯数字的数据
df['价格']=df['价格'].apply(lambda x:x.replace(',','').replace(' ',''))
for r_index,row in df.iterrows():
if row[5].replace('.','').isdecimal()==False:
df.drop(r_index,axis=0,inplace=True)
elif row[5][-1].isdecimal()==False:
df.drop(r_index,axis=0,inplace=True)
# 转换价格的格式
df['价格']=df['价格'].astype(float)
# 将价格低于1元的书籍去除
df.drop(df[df['价格']<1].index,inplace=True)
2.6去除书名重复的数据
# 查看此时重复的书名
df['书名'].value_counts()

# 查看重复书名数量
df['书名'].duplicated().value_counts()
结果:
False 42813
True 2073
Name: 书名, dtype: int64
# 按照评论数量排名,然后去重,以保证数据可靠性
df=df.sort_values(by='评论数量',ascending=False)
df.reset_index(drop=True,inplace=True)

# 对排序后的数据进行去重
df.drop_duplicates(subset='书名', keep='first',inplace=True)
df.reset_index(drop=True,inplace=True)
# 查看是否还有重复的数据
df['书名'].value_counts()
# 清理后的数据
df.to_excel(r'/PythonTest/Data/douban_book.xls',encoding='utf_8_sig')
df
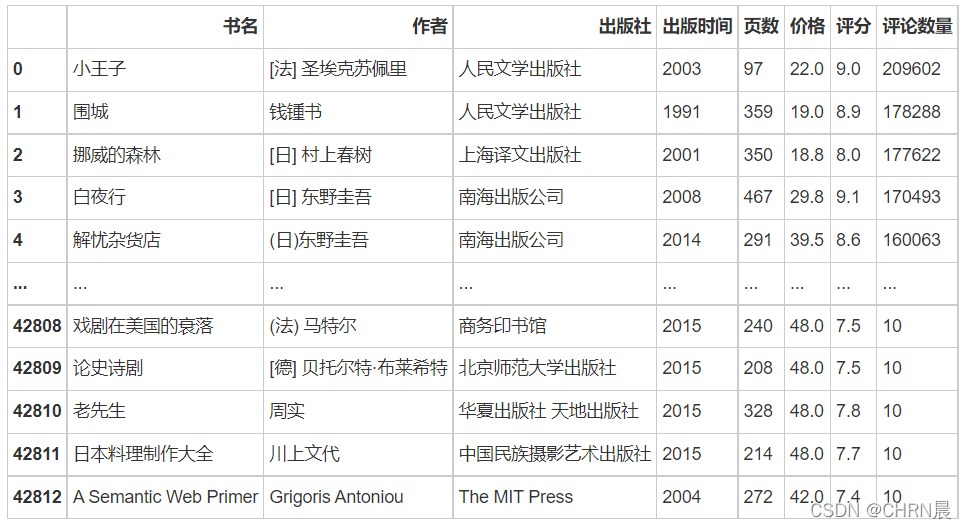
2.7哪个出版社的书籍评分较高?
# 先统计各出版社的出版作品数量
press=df['出版社'].value_counts()
press=pd.DataFrame(press)
press=press.reset_index().rename(columns={'index':'出版集团','出版社':'出版数量'})
press
# 将出版作品数量大于200的出版社名称提取到列表中
lst=press[press['出版数量']>200]['出版集团'].tolist()
# 将列表中的出版社的作品平均分计算出来,并按照降序排序
press_rank=df[df['出版社'].isin(lst)].groupby(by='出版社',as_index=False).agg(
{'评分':np.mean}).sort_values(by='评分',ascending=False)
# 保存为excel
press_rank.to_excel(r'/PythonTest/Data/press_rank.xls',encoding='utf_8_sig')
press_rank

2.8哪些书值得一读?
# 将评论数量大于50000的作品提取出来,并按照评分降序排序
sor=df[df['评论数量']>50000].sort_values(by='评分',ascending=False)
sor
# 计算评分列的平均值
df['评分'].mean()
# 加权总分 = (v ÷ (v+m)) × R + (m ÷ (v+m))
#-R :该电影的算数平均分 。 是用普通的方法计算出的平均分
# -v :该电影投票人数
# -m:进入排行需要的最小投票数
sor.eval('加权总分=(((评论数量/(评论数量+50000))*评分)+(50000/(评论数量+50000)))',inplace=True)
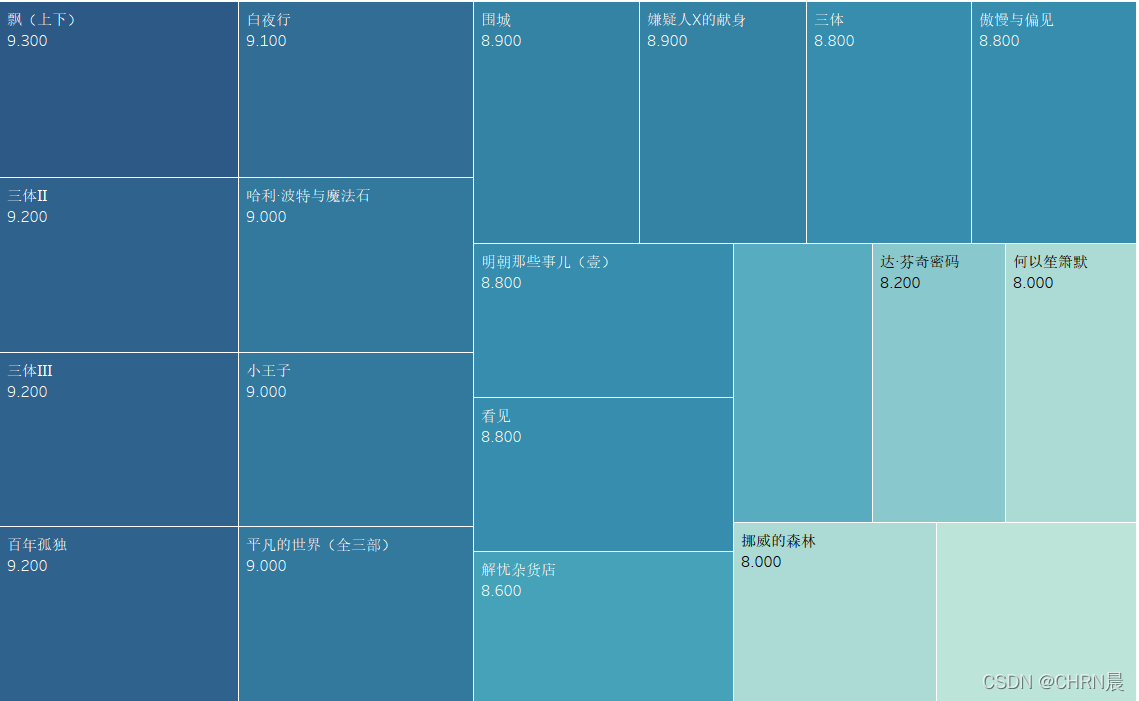
book_rank=sor.sort_values(by='加权总分',ascending=False).reset_index(drop=True).head(20)
# 保存为excel
book_rank.to_excel(r'/PythonTest/Data/book_rank.xls',encoding='utf_8_sig')
book_rank
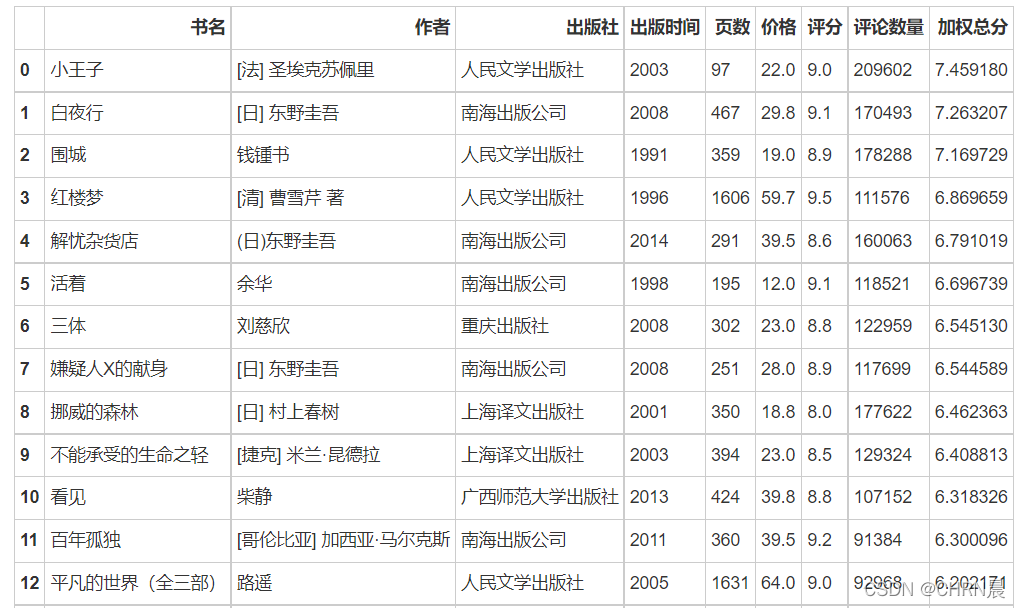
2.9作者排名(10部作品及以上)
# 先提取出评论数量大于100的作品
df1=df[df['评论数量']>100]
# 再提取出评分大于等于8的作品
df1=df1[df1['评分']>=8]
# 将过滤后的的作品按作者进行统计
writer=df1['作者'].value_counts()
writer=pd.DataFrame(writer)
writer.reset_index(inplace=True)
writer.rename(columns={'index':'作家','作者':'作品数量'},inplace=True)
writer
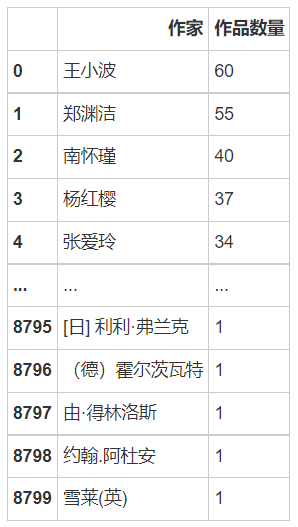
# 提取出优秀作品数量大于等于10的作家
lst1=writer[writer['作品数量']>=10]['作家'].tolist()
# 求得每位作家的平均得分
writer_rank=df1[df1['作者'].isin(lst1)].groupby(by='作者',as_index=False).agg(
{'评分':np.mean}).sort_values(by='评分',ascending=False).reset_index(drop=True).head(20)
# 保存为excel
writer_rank.to_excel(r'/PythonTest/Data/writer_rank.xls',encoding='utf_8_sig')
writer_rank
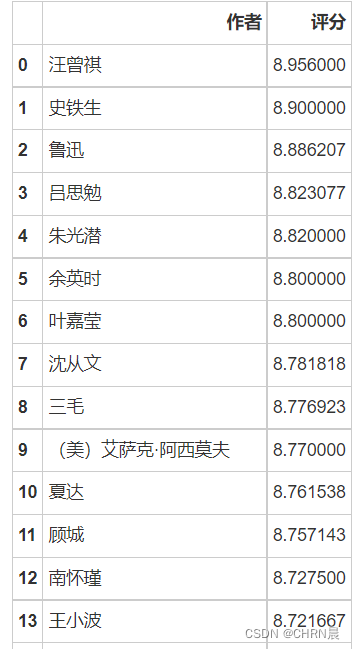
三.数据分析与可视化
3.1各年作品出版数量折线图

3.2各价位作品数量直方图
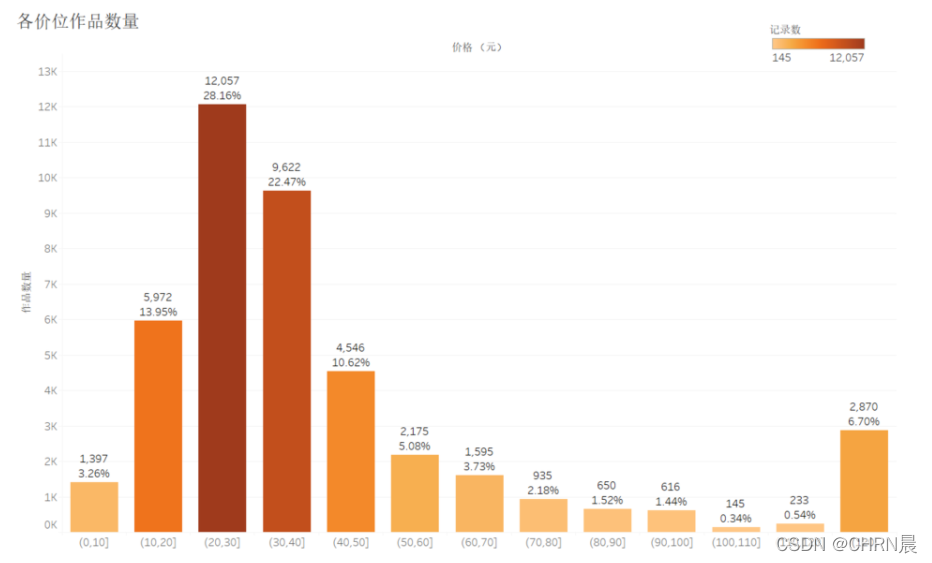
3.3各出版社出版作品数量条形图&评分折线图

3.4作者作品评分条形图
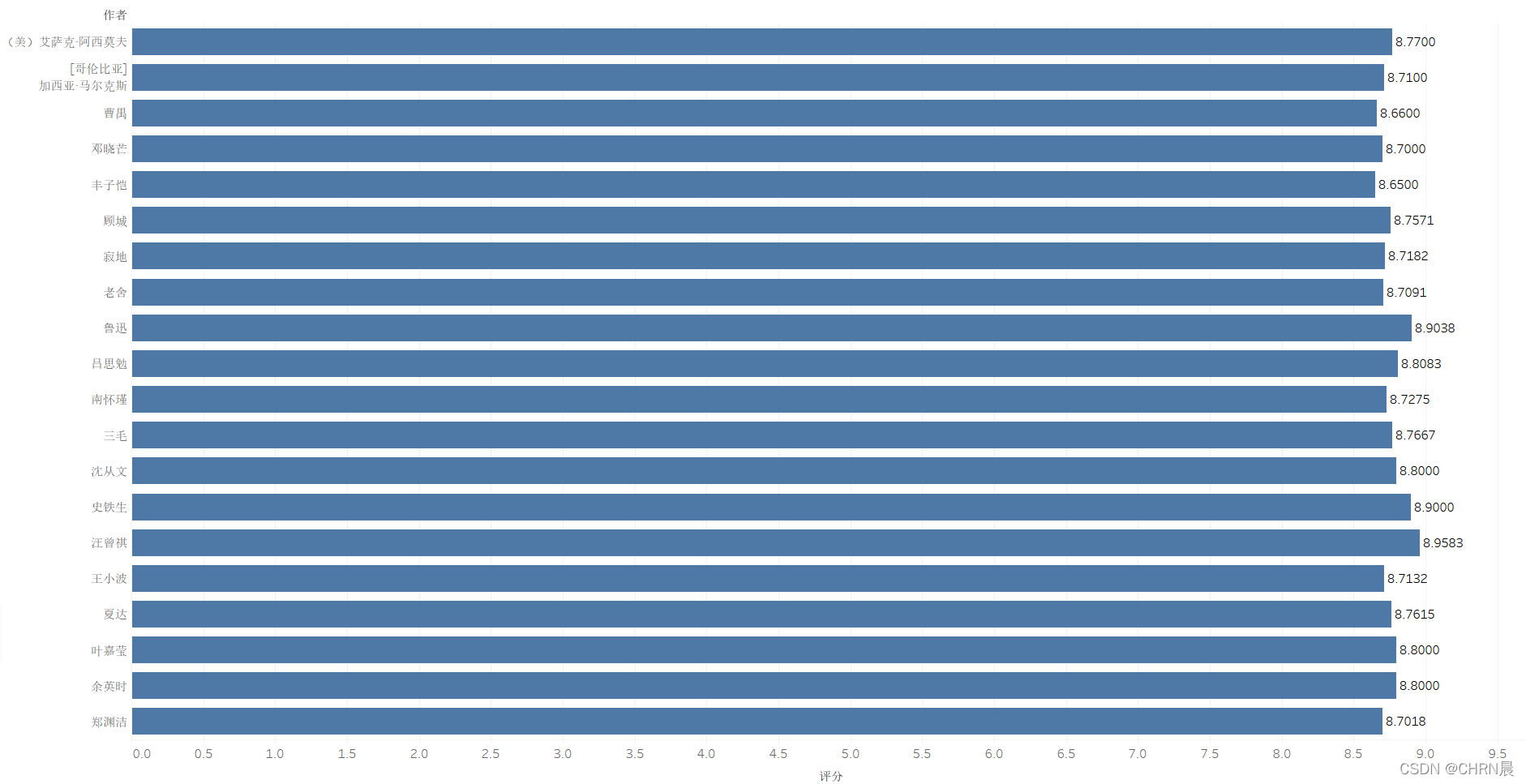
3.5作品评分树状图

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)