python爬虫4:json提取数据
简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。稍加分析可以看出,type为热门类型(可选参数为movie,tv),tag为热门电影电视剧的类型(热门,最新,豆瓣高分等参数),page_limit为展示条数,page_start从第几部开始。JSONPath是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提
JSON
JSON(JavaScript Object Notation, JS对象简谱)是一种轻量级的数据交换格式。它基于 ECMAScript(European Computer Manufacturers Association, 欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
使用python中json库来爬取数据
案例:豆瓣网
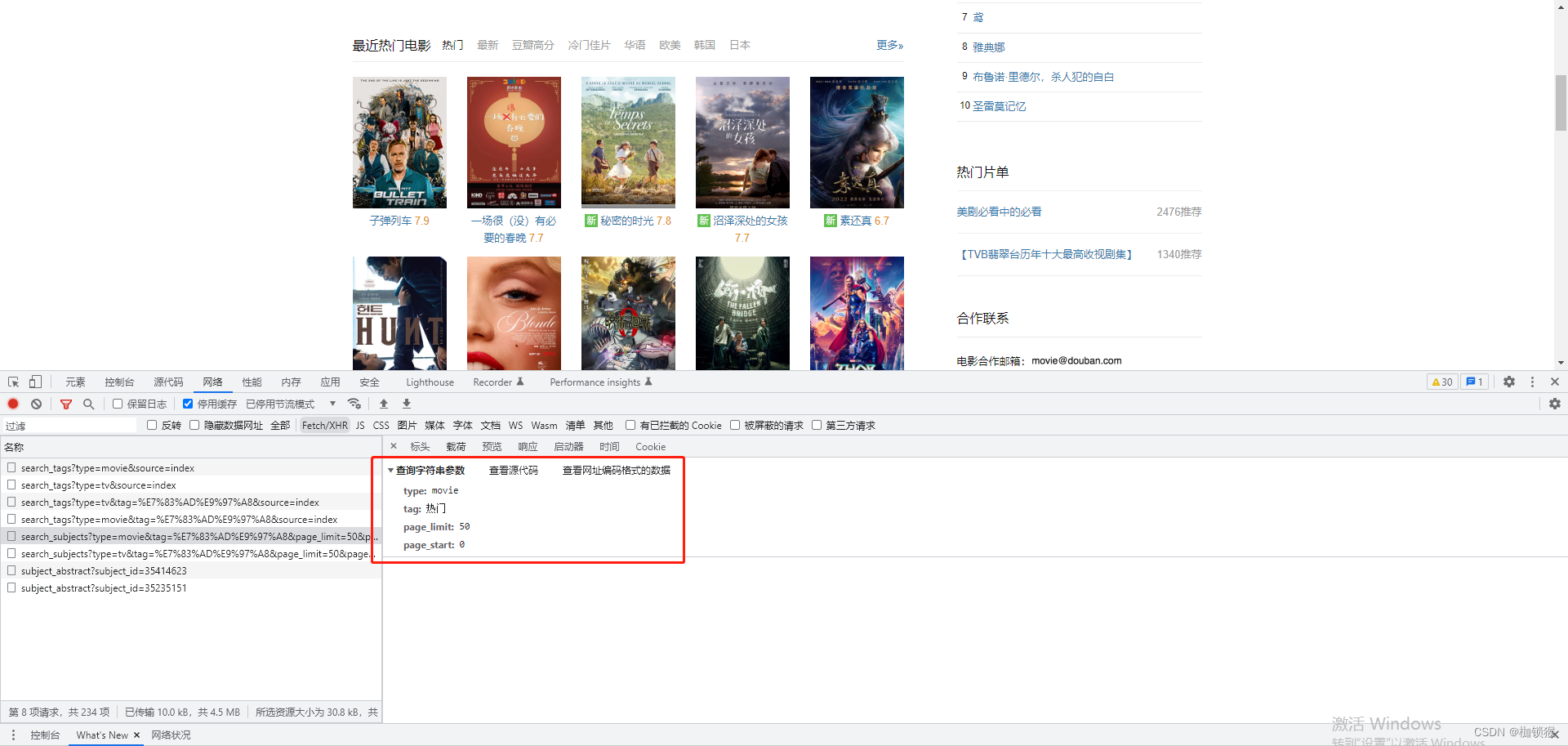
输入豆瓣网站,F12打开,查看接口请求参数
可以看到请求参数为:
type: movie
tag: 热门
page_limit: 50
page_start: 0
稍加分析可以看出,type为热门类型(可选参数为movie,tv),tag为热门电影电视剧的类型(热门,最新,豆瓣高分等参数),page_limit为展示条数,page_start从第几部开始
下面展示一些 代码:
import os
import requests
from fake_useragent import UserAgent
import json
def doubanjson(type,tag,page_limit):
url = 'https://movie.douban.com/j/search_subjects?'
params = {
"type": type,
"tag":tag,
"page_limit": page_limit,
"page_start": 0
}
ua = UserAgent()#随机请求头
head = {
'user-agent': ua.chrome
}
response = requests.get(url, params=params, headers=head)
jsons = json.loads(response.text)#转为字典
subjects = (jsons['subjects'])
mulu='豆瓣热门最新练习'#文件夹
if not os.path.exists(mulu):#判断是否存在该文件夹
os.mkdir(mulu)
#循环遍历取数据
for i in subjects:
name = i['title'] # 电影名称
img = i['cover'] # 电影照片
rate = i['rate'] # 电影评分
with open(mulu+'/'+'热门.txt', 'a+', encoding='utf-8') as f:
f.write('评分:' + rate + '名字:' + name + '下载地址:' + img + '\n')
print('正在下载:' + name)
#获取豆瓣中热门电影前50(电视剧为tv)
doubanjson('movie','热门',50)
JSONPAH
JSONPath是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括Javascript、Python、PHP和Java
站点: http://jsonpath.com/验证JsonPath的执行效果。
案例还是豆瓣网
下面展示一些 代码:
import os.path
import jsonpath
import requests
from fake_useragent import UserAgent
import json
def doubanjsonpath(type,tag,page_limit):
url = 'https://movie.douban.com/j/search_subjects?'
params = {
"type": type,
"tag": tag,
"page_limit": page_limit,
"page_start": 0
}
ua = UserAgent()#随机请求头
head = {
'user-agent': ua.chrome
}
mulu='豆瓣热门最新练习'#文件夹
if not os.path.exists(mulu):#判断是否存在该文件夹
os.mkdir(mulu)
response = requests.get(url, params=params, headers=head)
jsons = json.loads(response.text)#转为字典
title = jsonpath.jsonpath(jsons, '$..title') # 提取名称
rate = jsonpath.jsonpath(jsons, '$..rate') # 提取评分
cover = jsonpath.jsonpath(jsons, '$..cover') # 提取图片下载地址
#循环遍历下载
for a, b, c in zip(rate, title, cover):
with open(mulu+'/'+'热门.txt', 'a+', encoding='utf-8') as f:
f.write('评分:' + a + '名字:' + b + '下载地址:' + c + '\n')
print('正在下载:' + b)
#获取豆瓣中热门电视剧前50(电影请求参数是'movie')
doubanjsonpath('tv','热门',50)
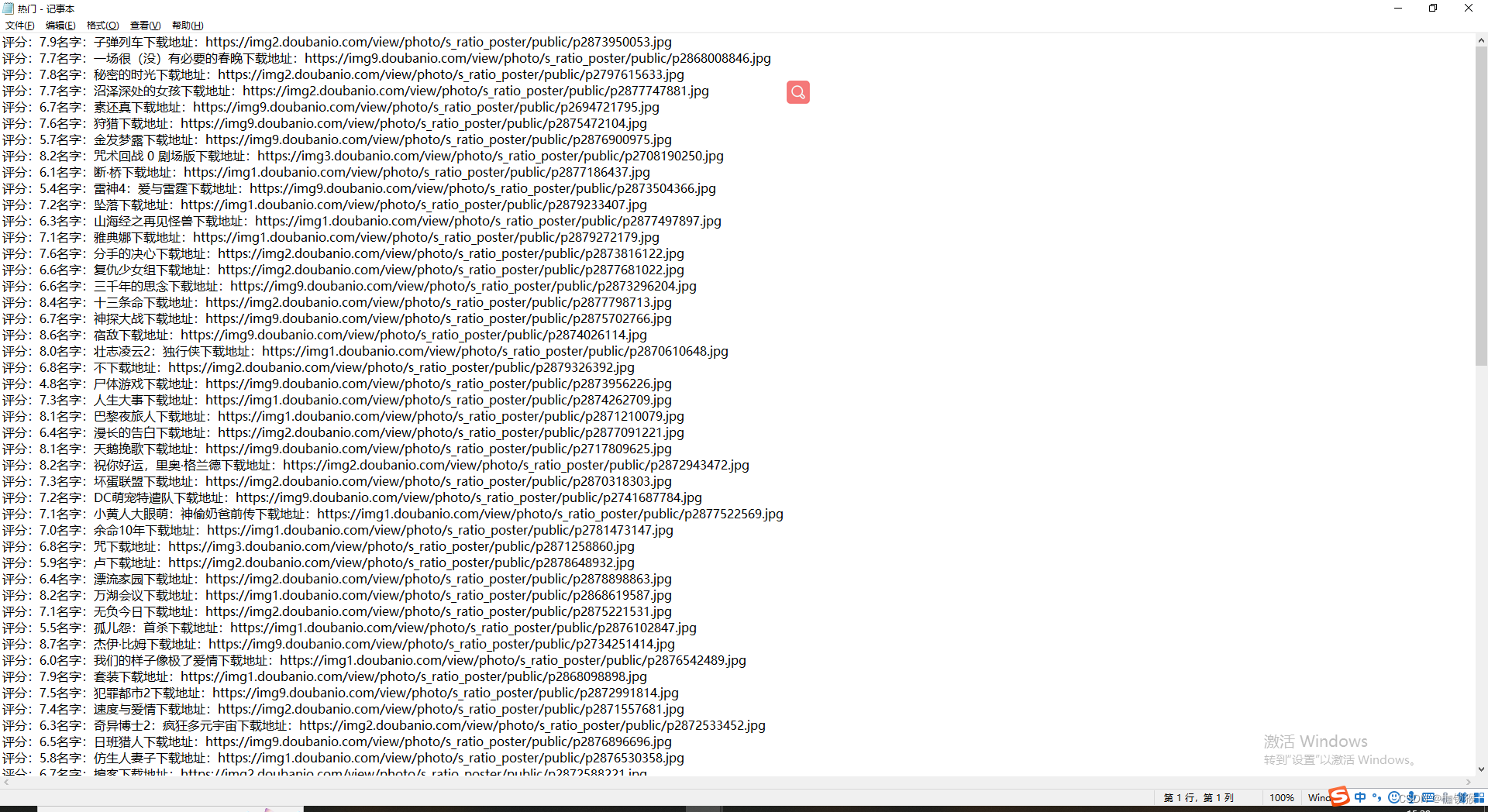
最终展示效果:

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)