Pandas中的GroupBy分组及agg()分组聚合
Pandas中的分组聚合功能其实类似SQL语句中的group by自己及聚合函数用法。
1 GroupBy分组
Pandas中的分组聚合功能其实类似SQL语句中的group by自己及聚合函数用法。其常规用法举例如下:
import pandas as pd
import numpy as np
def odd(num):
return (num%2)==0
data=pd.DataFrame([['a',2],
['a',10],
['c',3]],columns=list('AB'))
res1=data.groupby('A')['B'].sum()其结果如下:

Pandas中支持的分组聚合函数主要有以下几种:count(求数据量)、sum(求和)、mean(求均值)、median(求中位数)、std(求方差)、var(求标准差)、min(求最小值)、max(求最大值)、prod(求积)、first(求第一个值)、last(求最后一个值)。这些聚合方法都会排除每个分组内的NaN值。
1.1 通过函数进行分组
Pandas中除了直接使用字段对数据进行分组之外,还可以使用字段的计算处理结果作为分组依据。这里只重点介绍分组之后各个组的数据,不做聚合计算。具体如下:
def odd(num):
return (num%2)==0
data=pd.DataFrame(np.arange(21).reshape(3,7),columns=list('ABCDEFG'))
print("第一种分组结果:")
#相当于依据data的索引值在odd函数上的运行结果作为分类标准
for key,group in data.groupby(odd):
print(key)
print(group)
print("第二种分组结果:")
#相当于依据B列在odd函数的运行结果作为分类标准
for key,group in data.groupby(odd(data['B'])):
print(key)
print(group)
代码运行结果如下:
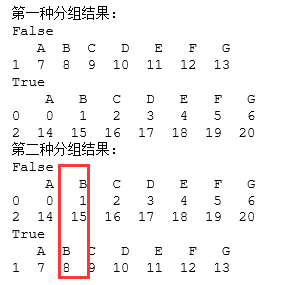
关于使用自定义函数对数据进行分组时,总结如下:
- 首先,除了自定义函数,python中的内建函数,比如len等,也可以直接用来进行分组。
- 其次,这些函数不仅可以作用在索引列上,也可以自己指定作用列。
- 最后,指定了自定义函数的作用列之后,列中的每个值都会传入到函数中执行。并根据其函数运行结果对原始数据进行分组。
1.2 在axis=1轴上进行分组
Pandas中使用groupby()时默认是在axis=0轴上进行分组的,也可以通过设置在axis=1轴上进行分组。
import pandas as pd
import numpy as np
def odd(num):
return int(num)%2==0
data=pd.DataFrame(np.arange(20).reshape(4,5),index=list('1234'),columns=list('12345'))
print("原始数据:")
print(data)
data_axis0=data.groupby(odd,axis=0)#默认依据index在odd上的运行结果进行分组
print("按axis=0进行分组结果如下:")
for key,group in data_axis0:
print(key)
print(group)
data_axis1=data.groupby(odd,axis=1)#默认依据column在odd上的运行结果进行分组
print("按axis=1进行分组结果如下:")
for key,group in data_axis1:
print(key)
print(group)代码运行结果如下:
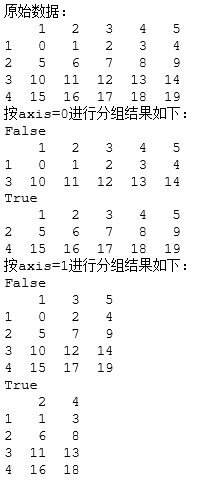
这里要注意以下两点:
- pands中的两种数据类型DataFrame和Series都支持GroupBy操作,但Series只支持在axis=0轴上进行操作。因为Series没有axis=1轴。
- 若未设置axis参数,默认按axis=0轴进行聚合。
1.3 使用其他数据进行分组
除了DataFrame/Series本身的数据之外,Pandas还可以依据其他数据对DataFrame/Series进行分组。具体举例如下:
import pandas as pd
import numpy as np
data=pd.DataFrame(np.arange(30).reshape(5,6),index=list('12345'),columns=list('ABCDEF'))
print(data)
date_list=[2004,2005,2006,2005,2004]
data_1=data.groupby(date_list)
print("分组结果如下:")
for key,group in data_1:
print(key)
print(group)运行结果如下:

注意:
- 首先,在这种写法中不能设置axis参数(笔者是在python3.6版本进行的实验)。原因暂且不明。
- 其次,从代码运行结果进行反推可以得出以下两个结论:1.聚合默认是在axis=0轴进行的。2.代码中的date_list中的每个元素按照顺序与dataframe中的记录一一对应。所以date_list的长度要和dataframe中的记录数一致。
除了使用上述List类型的数据作为分组依据,还可以使用Series和字典作为分组依据。下面仅以字典类型为例:
import pandas as pd
import numpy as np
data=pd.DataFrame(np.arange(20).reshape(4,5),index=list('1234'),columns=list('12345'))
by_dict={'1':'red','2':'yellow','3':'yellow','4':'black','5':'white'}
by_dict1={'1':'red','2':'yellow','3':'yellow','5':'white'}
data_1=data.groupby(by_dict)
print("按by_dict分组的结果:")
for key,group in data_1:
print(key)
print(group)
data_2=data.groupby(by_dict1)
print("按by_dict1分组的结果:")
data_3=data.groupby(by_dict1)
for key,group in data_3:
print(key)
print(group)代码运行结果如下:

注意:
- 使用字典或Series作为依据对数据进行分组时,如果行索引或列索引在分组依据(代码中的by_dict和by_dict1变量)中并没有找到对应关系,则对应的行或列是不参与最终的分组的(不是自成一组,可以从by_dict1分组的结果中看出此结论)。
- 分组依据中可以出现行索引或列索引中没有出现的值。比如by_dict1中的5
- 使用Series和字典时,可以设置axis参数。
2 agg()方法的使用
前文介绍过,可以直接在GroupBy变量之后直接使用聚合函数,但这种情况下只能支持一种聚合计算。但使用agg()方法就可以对不同的列使用不同的聚合计算,而且还可以自定义聚合函数。具体举例如下:
df=pd.DataFrame({
'Data1':np.random.randint(0,10,5),
'Data2':np.random.randint(10,20,5),
'key1':list("aabba"),
'key2':list('xyyxy')
})
def collect_data(x):
return x.tolist()
res1=df.groupby('key1').agg({'Data1':['min','max'],
'Data2':'sum',
'key2':['count',collect_data]})
res2=df.groupby('key1').agg(['first','count'])
res3=df.groupby('key2')['Data1'].agg(idx=collect_data,all_sum='sum')res1、res2、res3结果如下:



这里要注意以下几点:
- 可以使用dict给不同的列指定不同的聚合函数;可以使用List型同时指定多个聚合函数;还可以使用idx=collect_data这种同时指定聚合计算及聚合后的字段名;
- agg()中min\max\count等聚合函数要加'';
- 这里要注意一点,分组之后的数据是按列传入到聚合函数中的。这一点很重要,不明白这一点就不理解自定义函数的写法。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)