automl框架:AutoGluon介绍
文章目录automl框架:AutoGluon介绍原理安装案例加载数据集测试通过leaderboard查看各个学习器参考automl框架:AutoGluon介绍原理大部分automl框架是基于超参数搜索技术,例如基于贝叶斯搜索的hyperopt技术等AutoGluon则依赖融合多个无需超参数搜索的模型,三个臭皮匠顶个诸葛亮stacking: 在同一份数据上训练出多个不同类型的模型,这些模型可以是KN
·
automl框架:AutoGluon介绍
原理
- 大部分automl框架是基于超参数搜索技术,例如基于贝叶斯搜索的hyperopt技术等
- AutoGluon则依赖融合多个无需超参数搜索的模型,三个臭皮匠顶个诸葛亮
- stacking: 在同一份数据上训练出多个不同类型的模型,这些模型可以是KNN、tree、核方法等,这些模型的输出进入到一个线性模型里面得到最终的输出,就是对这些输出做加权求和,这里的权重是通过训练得出。
- K-则交叉Bagging:Bagging是训练同类别的多个模型,他们可能使用不同的初始权重或者数据块,最终将这些模型的输出做平均来降低模型的方差。
- K-则交叉Bagging,源自于K-则交叉验证。
- 相同点都是对数据集做K折
- K-则交叉验证:相同的初始参数,训练多次,对每次的误差求平均后作为这些初始参数的最终误差,为了最大化利用数据集,可以有效避免过拟合和欠拟合。
- (是为了验证初始参数)
- K-则交叉Bagging:每一则对应不同的初始参数,训练出多个模型,对结果求平均(3个臭皮匠顶个诸葛亮)
- 多层Stacking:将多个模型输出的数据,合并起来,再做一次Stacking。在上面再训练多个模型,最后用一个线性模型做输出。
- 为了避免后面层过多拟合数据,多层Stacking通常配合K-则交叉Bagging使用,也就是说这里的每个模型是K个模型的Bagging。它对下一层stacking的输出,是指每个bagging模型对应验证集上输出的合并
安装
conda create -y --force -n p38 python=3.8 pip
conda activate p38
pip install -U "mxnet<2.0.0"
pip install autogluon
案例
加载数据集
from autogluon.tabular import TabularDataset, TabularPredictor
train_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv')
subsample_size = 500 # subsample subset of data for faster demo, try setting this to much larger values
train_data = train_data.sample(n=subsample_size, random_state=0)
label = 'class'
save_path = 'agModels-predictClass' # specifies folder to store trained models
predictor = TabularPredictor(label=label, path=save_path).fit(train_data)
fit函数执行的日志如下:
- 首先推导是什么问题,binary、multiclass还是regression
- 进行数据预处理(Data preprocessing and feature engineering)
- AsTypeFeatureGenerator
- FillNaFeatureGenerator
- IdentityFeatureGenerator、CategoryFeatureGenerator
- DropUniqueFeatureGenerator
- 通过eval_metric参数决定评估指标来衡量预测性能,默认是accuracy(准确性)
- 自动拆分训练集和验证集,holdout_frac=0.2
- 训练模型(从最快的模型开始尝试,作为stack1)
- KNeighborsUnif
- KNeighborsDist
- LightGBMXT
- LightGBM
- 最后一个是WeightedEnsemble(作为stack2)
- 保存模型
Beginning AutoGluon training ...
AutoGluon will save models to "agModels-predictClass/"
AutoGluon Version: 0.2.0
Train Data Rows: 500
Train Data Columns: 14
Preprocessing data ...
AutoGluon infers your prediction problem is: 'binary' (because only two unique label-values observed).
2 unique label values: [' >50K', ' <=50K']
If 'binary' is not the correct problem_type, please manually specify the problem_type argument in fit() (You may specify problem_type as one of: ['binary', 'multiclass', 'regression'])
Selected class <--> label mapping: class 1 = >50K, class 0 = <=50K
Note: For your binary classification, AutoGluon arbitrarily selected which label-value represents positive ( >50K) vs negative ( <=50K) class.
To explicitly set the positive_class, either rename classes to 1 and 0, or specify positive_class in Predictor init.
Using Feature Generators to preprocess the data ...
Fitting AutoMLPipelineFeatureGenerator...
Available Memory: 84412.85 MB
Train Data (Original) Memory Usage: 0.29 MB (0.0% of available memory)
Inferring data type of each feature based on column values. Set feature_metadata_in to manually specify special dtypes of the features.
Stage 1 Generators:
Fitting AsTypeFeatureGenerator...
Stage 2 Generators:
Fitting FillNaFeatureGenerator...
Stage 3 Generators:
Fitting IdentityFeatureGenerator...
Fitting CategoryFeatureGenerator...
Fitting CategoryMemoryMinimizeFeatureGenerator...
Stage 4 Generators:
Fitting DropUniqueFeatureGenerator...
Types of features in original data (raw dtype, special dtypes):
('int', []) : 6 | ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', ...]
('object', []) : 8 | ['workclass', 'education', 'marital-status', 'occupation', 'relationship', ...]
Types of features in processed data (raw dtype, special dtypes):
('category', []) : 8 | ['workclass', 'education', 'marital-status', 'occupation', 'relationship', ...]
('int', []) : 6 | ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', ...]
0.2s = Fit runtime
14 features in original data used to generate 14 features in processed data.
Train Data (Processed) Memory Usage: 0.03 MB (0.0% of available memory)
Data preprocessing and feature engineering runtime = 0.27s ...
AutoGluon will gauge predictive performance using evaluation metric: 'accuracy'
To change this, specify the eval_metric argument of fit()
Automatically generating train/validation split with holdout_frac=0.2, Train Rows: 400, Val Rows: 100
Fitting model: KNeighborsUnif ...
0.73 = Validation accuracy score
0.02s = Training runtime
0.04s = Validation runtime
Fitting model: KNeighborsDist ...
0.65 = Validation accuracy score
0.01s = Training runtime
0.05s = Validation runtime
Fitting model: LightGBMXT ...
0.83 = Validation accuracy score
198.28s = Training runtime
0.04s = Validation runtime
Fitting model: LightGBM ...
0.85 = Validation accuracy score
342.98s = Training runtime
0.08s = Validation runtime
Fitting model: RandomForestGini ...
0.84 = Validation accuracy score
1.83s = Training runtime
0.16s = Validation runtime
Fitting model: RandomForestEntr ...
0.83 = Validation accuracy score
1.39s = Training runtime
0.31s = Validation runtime
Fitting model: CatBoost ...
0.84 = Validation accuracy score
0.87s = Training runtime
0.03s = Validation runtime
Fitting model: ExtraTreesGini ...
0.82 = Validation accuracy score
1.35s = Training runtime
0.14s = Validation runtime
Fitting model: ExtraTreesEntr ...
0.82 = Validation accuracy score
1.49s = Training runtime
0.23s = Validation runtime
Fitting model: NeuralNetFastAI ...
Warning: Exception caused NeuralNetFastAI to fail during training... Skipping this model.
CUDA error: out of memory
Fitting model: XGBoost ...
0.85 = Validation accuracy score
152.17s = Training runtime
0.02s = Validation runtime
Fitting model: NeuralNetMXNet ...
0.84 = Validation accuracy score
9.57s = Training runtime
0.59s = Validation runtime
Fitting model: LightGBMLarge ...
0.83 = Validation accuracy score
745.44s = Training runtime
0.01s = Validation runtime
Fitting model: WeightedEnsemble_L2 ...
0.85 = Validation accuracy score
0.27s = Training runtime
0.0s = Validation runtime
AutoGluon training complete, total runtime = 1460.95s ...
TabularPredictor saved. To load, use: predictor = TabularPredictor.load("agModels-predictClass/")
测试
test_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv')
y_test = test_data[label] # values to predict
test_data_nolab = test_data.drop(columns=[label]) # delete label column to prove we're not cheating
predictor = TabularPredictor.load(save_path) # unnecessary, just demonstrates how to load previously-trained predictor from file
y_pred = predictor.predict(test_data_nolab)
perf = predictor.evaluate_predictions(y_true=y_test, y_pred=y_pred, auxiliary_metrics=True)
输出结果为:
Evaluation: accuracy on test data: 0.8397993653393387
Evaluations on test data:
{
"accuracy": 0.8397993653393387,
"balanced_accuracy": 0.7437076677780596,
"mcc": 0.5295565206264157,
"f1": 0.6242496998799519,
"precision": 0.7038440714672441,
"recall": 0.5608283002588438
}
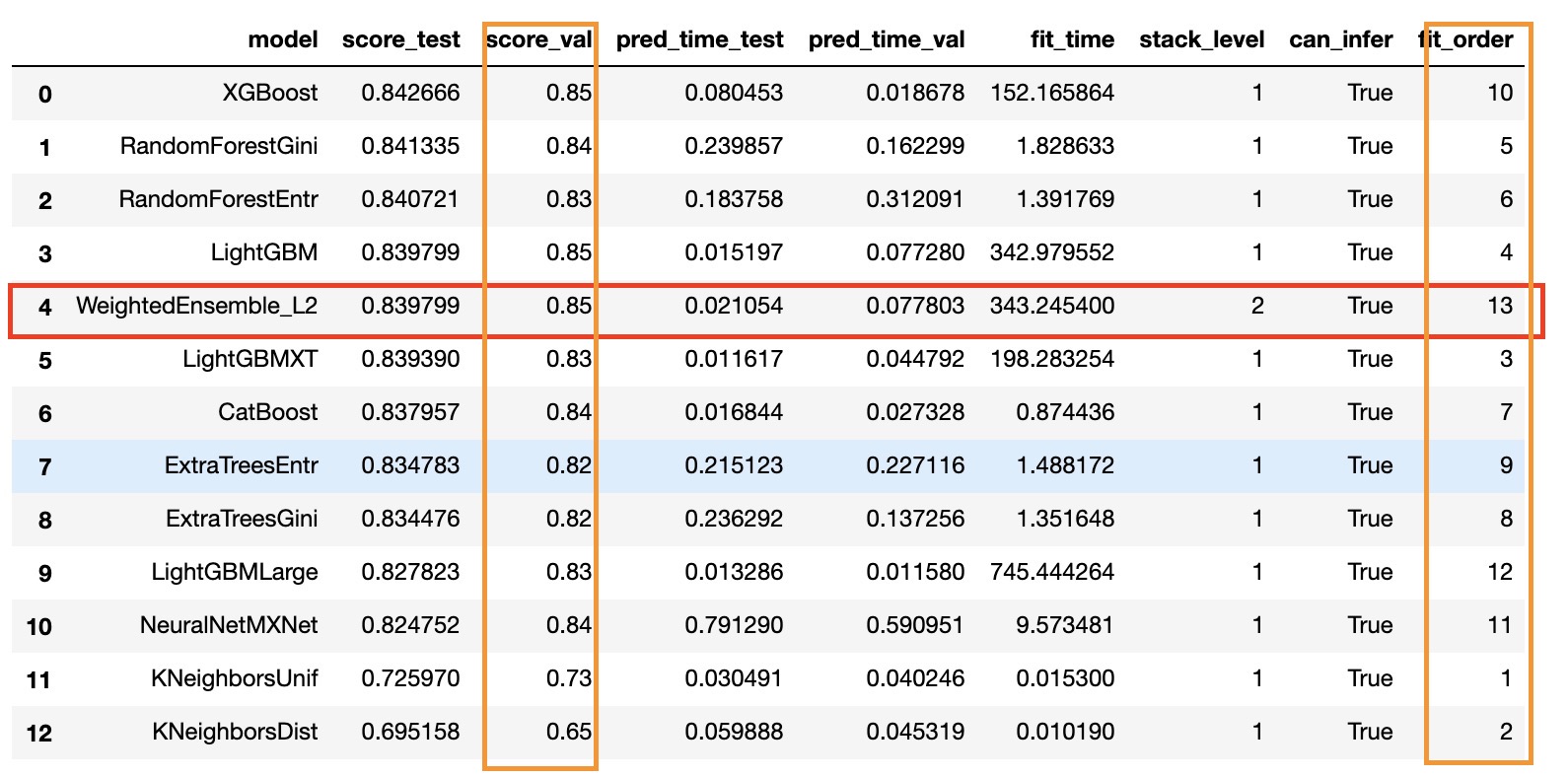
通过leaderboard查看各个学习器
predictor.leaderboard(test_data, silent=True)
参考
- https://auto.gluon.ai/dev/tutorials/tabular_prediction/tabular-quickstart.html
- 论文:https://arxiv.org/abs/2003.06505
- arXiv 同archive 读['a:rkaiv]

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)