机器学习实战三: 预测汽车油耗效率 MPG
预测汽车油耗效率 MPG这次做一个简单的线性回归的实验,用来预测汽车的油耗效率 MPG,让我们通过这次实验,更加清晰的了解一下LinearRegression,如果想更加清晰的了解的话,可以看看吴恩达机器学习ex1 Linear Regression (python)目录Read In Data探究数据模型拆分训练集和测试集单变量线性回归搭建线性回归模型可视化结果训练集测试集模型评价多变量线性回归
预测汽车油耗效率 MPG
这次做一个简单的线性回归的实验,用来预测汽车的油耗效率 MPG,让我们通过这次实验,更加清晰的了解一下LinearRegression,如果想更加清晰的了解的话,可以看看吴恩达机器学习ex1 Linear Regression (python)
如果想了解更多的知识,可以去我的机器学习之路 The Road To Machine Learning通道
Read In Data
我们先读入数据,其中,这里面一个有九列,他们分别都有对应的意义,其中有一列是汽车油耗效率mpg
- mpg - > 燃油效率
- cylinders -> 气缸
- displacement - > 排量
- horsepower - > 马力
- weight - > 重量
- acceleration - > 加速度
- model year - > 型号年份
- origin = > 编号
- car name - > 原产地
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
path = '../data_files/3.MPG/auto-mpg.data'
columns = ["mpg", "cylinders", "displacement", "horsepower", "weight", "acceleration", "model year", "origin", "car name"]
# mpg - > 燃油效率
# cylinders -> 气缸
# displacement - > 排量
# horsepower - > 马力
# weight - > 重量
# acceleration - > 加速度
# model year - > 型号年份
# origin = > 编号
# car name - > 原产地
cars = pd.read_csv(path, delim_whitespace=True, names=columns)
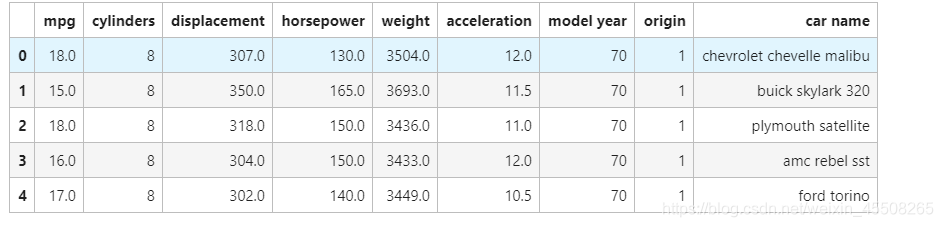
cars.info()
这时候就读完数据了
探究数据模型
在我们可视化数据的时候,我们会发现origin和car name都是离散型的,就没有选择他们进行一个线性回归模型的搭建,除此之外,由于在horsepower中,有一些值是存在’?‘我们就要选取那些不是’?‘的进行操作
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
cars = cars[cars.horsepower != '?']
#用散点图分别展示气缸、排量、重量、加速度与燃油效率的关系
fig = plt.figure(figsize=(13,20))
ax1 = fig.add_subplot(321)
ax2 = fig.add_subplot(322)
ax3 = fig.add_subplot(323)
ax4 = fig.add_subplot(324)
ax5 = fig.add_subplot(325)
ax1.scatter(cars['cylinders'],cars['mpg'],alpha=0.5)
ax1.set_title('cylinders')
ax2.scatter(cars['displacement'],cars['mpg'],alpha=0.5)
ax2.set_title('displacement')
ax3.scatter(cars['weight'],cars['mpg'],alpha=0.5)
ax3.set_title('weight')
ax4.scatter(cars['acceleration'],cars['mpg'],alpha=0.5)
ax4.set_title('acceleration')
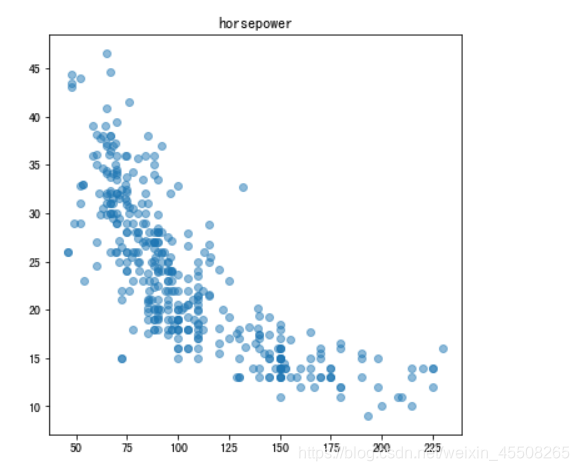
ax5.scatter([float(x) for x in cars['horsepower'].tolist()],cars['mpg'],alpha=0.5)
ax5.set_title('horsepower')
从下图我们可以看出,汽车的燃油效率mpg与排量displacement、重量weight、马力horsepower三者都存在一定的线性关系,其中汽车重量weight与燃油效率线性关系最为明显,首先我们就利用weight一个单变量去构建线性回归模型,看看是否能预测出来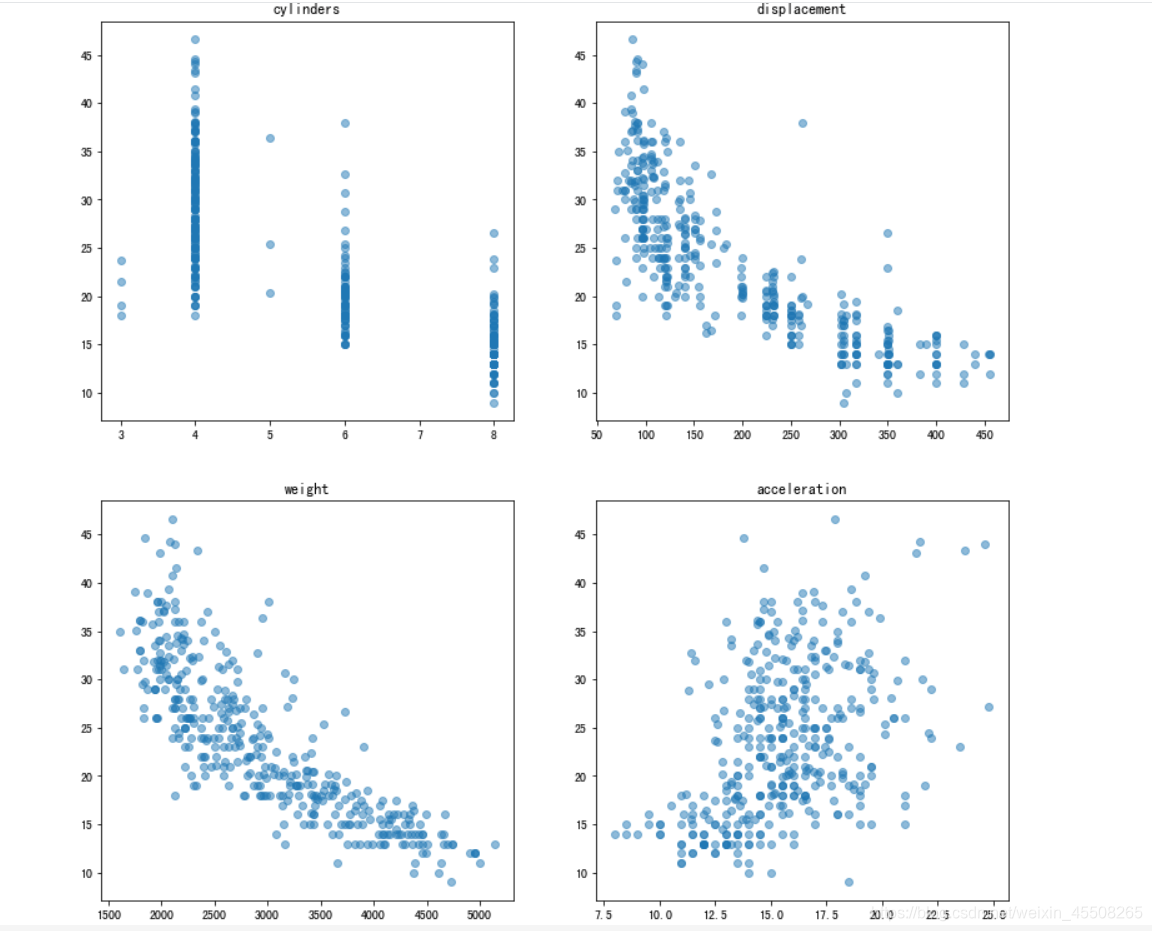
拆分训练集和测试集
Y = cars['mpg']
X = cars[['weight']]
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,test_size=0.2,random_state=0)
取数据中的20%作为测试集,其他均为测试集
单变量线性回归
搭建线性回归模型
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr = lr.fit(X_train,Y_train)
利用训练集去训练模型
可视化结果
利用我们训练完的模型去测试一下我们的训练集和测试集
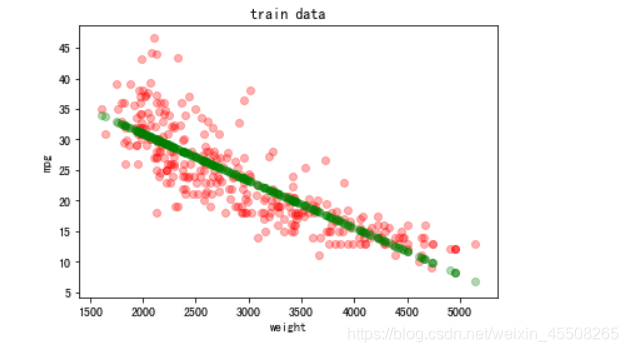
训练集
plt.scatter(X_train, Y_train, color = 'red', alpha=0.3)
plt.scatter(X_train, lr.predict(X_train),color = 'green',alpha=0.3)
plt.xlabel('weight')
plt.ylabel('mpg')
plt.title('train data')
plt.show()
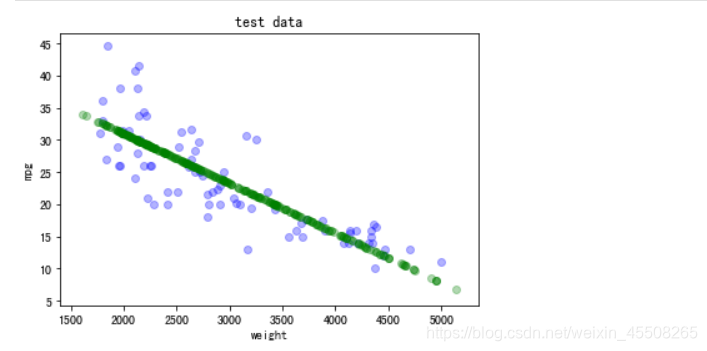
测试集
plt.scatter(X_test,Y_test,color = 'blue',alpha=0.3)
plt.scatter(X_train,lr.predict(X_train),color='green',alpha=0.3)
plt.xlabel('weight')
plt.ylabel('mpg')
plt.title('test data')
plt.show()
模型评价
print(lr.coef_)
print(lr.intercept_)
print('score = {}'.format(lr.score(X,Y)))
'''
[-0.00772198]
46.43412847740396
score = 0.6925641006507041
'''
可以看到,最后的结果的分数大约是0.69左右,还是挺不错的
多变量线性回归模型
刚刚我们是利用了单变量的线性回归模型,我们猜测,如果用多变量的线性回归模型会不会更好呢,因为汽车的燃油效率mpg与排量displacement、重量weight、马力horsepower三者都存在一定的线性关系
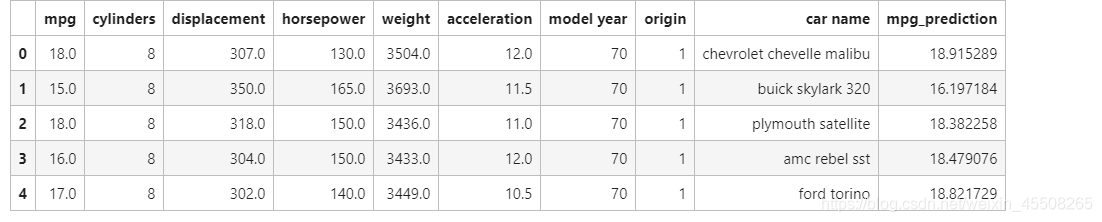
首先就要重新提取数据,为了对数据更加清晰,我们将预测出来mpg_prediction也加入数据中
cars = cars[cars.horsepower != '?']
mul = ['weight','horsepower','displacement'] # 选择三个变量进行建立模型
mul_lr = LinearRegression()
mul_lr.fit(cars[mul],cars['mpg']) # 训练模型
cars['mpg_prediction'] = mul_lr.predict(cars[mul])
cars.head()
模型得分
mul_score = mul_lr.score(cars[mul],cars['mpg'])
mul_score
# 0.7069554693444708
从结果可以看出来,这个模型得分大约是71,说明多变量线性回归模型还是比单变量线性回归模型优的,预测的也更加准确一点
from sklearn.metrics import mean_squared_error as mse
mse = mse(cars['mpg'],cars['mpg_prediction'])
print('mse = %f'%mse)
print('rmse = %f'%np.sqrt(mse))
'''
mse = 17.806188
rmse = 4.219738
'''
并且得出了MSE和RMSE的值
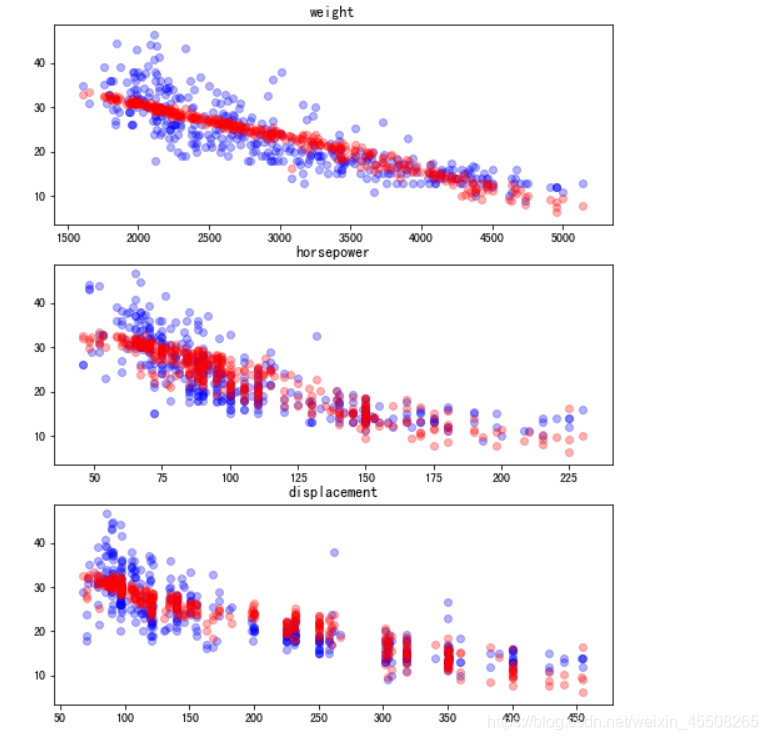
可视化
fig = plt.figure(figsize = (8,8))
ax1 = fig.add_subplot(3,1,1)
ax2 = fig.add_subplot(3,1,2)
ax3 = fig.add_subplot(3,1,3)
ax1.scatter(cars['weight'], cars['mpg'], c='blue', alpha=0.3)
ax1.scatter(cars['weight'], cars['mpg_prediction'], c='red', alpha=0.3)
ax1.set_title('weight')
ax2.scatter([ float(x) for x in cars['horsepower'].tolist()], cars['mpg'], c='blue', alpha=0.3)
ax2.scatter([ float(x) for x in cars['horsepower'].tolist()], cars['mpg_prediction'], c='red', alpha=0.3)
ax2.set_title('horsepower')
ax3.scatter(cars['displacement'], cars['mpg'], c='blue', alpha=0.3)
ax3.scatter(cars['displacement'], cars['mpg_prediction'], c='red', alpha=0.3)
ax3.set_title('displacement')
plt.show()
到这里又成功了,真不错,继续加油
每日一句
If you find a path with no obstacles, it probably doesn’t lead anywhere.
太容易的路,可能根本就不能带你去任何地方。
如果需要数据和代码,可以自提
- 路径1:我的gitee
- 路径2:百度网盘
链接:https://pan.baidu.com/s/1U9dteXf56yo3fQ7b9LETsA
提取码:5odf

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)