使用python将数据集划分为训练集、验证集和测试集
划分数据集众所周知,将一个数据集只区分为训练集和验证集是不行的,还需要有测试集,本博文针对上一篇没有分出测试集的不足,重新划分数据集直接上代码:#split_data.py#划分数据集flower_data,数据集划分到flower_datas中,训练集:验证集:测试集比例为6:2:2import osimport randomfrom shutil import copy2# 源文件路径file
·
划分数据集
众所周知,将一个数据集只区分为训练集和验证集是不行的,还需要有测试集,本博文针对上一篇没有分出测试集的不足,重新划分数据集
直接上代码:
#split_data.py
#划分数据集flower_data,数据集划分到flower_datas中,训练集:验证集:测试集比例为6:2:2
import os
import random
from shutil import copy2
# 源文件路径
file_path = r"D:/other/ClassicalModel/other/flower_data"
# 新文件路径
new_file_path = r"D:/other/ClassicalModel/other/flower_datas"
# 划分数据比例为6:2:2
split_rate = [0.6, 0.2, 0.2]
print("Starting...")
print("Ratio= {}:{}:{}".format(int(split_rate[0] * 10), int(split_rate[1] * 10), int(split_rate[2] * 10)))
class_names = os.listdir(file_path)
# 在目标目录下创建文件夹
split_names = ['train', 'val', 'test']
# 判断是否存在木匾文件夹
if os.path.isdir(new_file_path):
pass
else:
os.mkdir(new_file_path)
for split_name in split_names:
# split_path = os.path.join(new_file_path, split_name)
split_path = new_file_path + "/" + split_name
if os.path.isdir(split_path):
pass
else:
os.mkdir(split_path)
# 然后在split_path的目录下创建类别文件夹
for class_name in class_names:
class_split_path = os.path.join(split_path, class_name)
if os.path.isdir(class_split_path):
pass
else:
os.mkdir(class_split_path)
# 按照比例划分数据集,并进行数据图片的复制
# 首先进行分类遍历
for class_name in class_names:
current_class_data_path = os.path.join(file_path, class_name)
current_all_data = os.listdir(current_class_data_path)
current_data_length = len(current_all_data)
current_data_index_list = list(range(current_data_length))
random.shuffle(current_data_index_list)
train_path = os.path.join(os.path.join(new_file_path, 'train'), class_name)
val_path = os.path.join(os.path.join(new_file_path, 'val'), class_name)
test_path = os.path.join(os.path.join(new_file_path, 'test'), class_name)
train_stop_flag = current_data_length * split_rate[0]
val_stop_flag = current_data_length * (split_rate[0] + split_rate[1])
current_idx = 0
train_num = 0
val_num = 0
test_num = 0
for i in current_data_index_list:
src_img_path = os.path.join(current_class_data_path, current_all_data[i])
if current_idx <= train_stop_flag:
copy2(src_img_path, train_path
train_num = train_num + 1
elif (current_idx > train_stop_flag) and (current_idx <= val_stop_flag):
copy2(src_img_path, val_path)
val_num = val_num + 1
else:
copy2(src_img_path, test_path
test_num = test_num + 1
current_idx = current_idx + 1
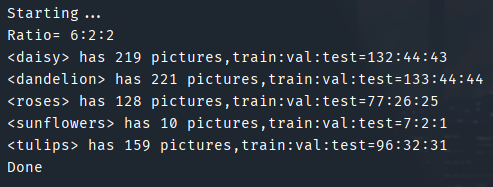
print("<{}> has {} pictures,train:val:test={}:{}:{}".format(class_name, current_data_length, train_num, val_num,
test_num))
print("Done")
输出结果:
注意:
只需要修改file_path(源文件夹)和new_file_path(新生成的文件夹)
其次是修改split_rate

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 8
8 1
1- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)