python实现互信息和条件互信息的计算
最近在研究信息论的时候,需要计算两个变量之间的互信息和条件互信息,计算公式如下。在python的api里只找到了互信息的函数:from sklearn.metrics import mutual_info_scoreX = [1,1,2]Y = [2,3,1]# 计算X和Y之间的互信息print(mutual_info_score(X, Y))但是没有找到条件互信息的代码,于是自己动手实现了一下互
·
最近在研究信息论的时候,需要计算两个变量之间的互信息和条件互信息,计算公式如下。

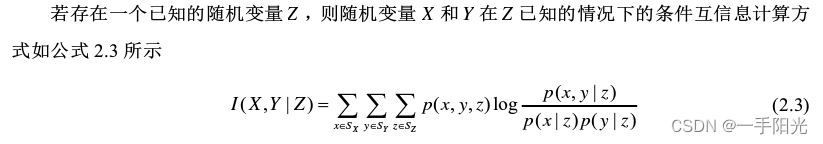
在python的api里只找到了互信息的函数:
from sklearn.metrics import mutual_info_score
X = [1,1,2]
Y = [2,3,1]
# 计算X和Y之间的互信息
print(mutual_info_score(X, Y))
但是没有找到条件互信息的代码,于是自己动手实现了一下互信息和条件互信息的代码,以免需要用到的朋友再重复造轮子了。
注意在计算中所用到的对数均是以自然对数e为底。互信息的代码没有用dataframe,有点繁琐。
互信息:
# 互信息计算公式 I(X;Y) = sigma(p_xy * ln(p_xy/(p_x * p_y)))
# 输入为一个dataframe,有两列数据,计算并返回的是这两列之间的互信息值
def mutualInfo(data):
X = np.asarray(data.iloc[:, 0])
Y = np.asarray(data.iloc[:, 1])
# 使用字典统计每一个x元素出现的次数
d_x = dict() # x的字典
for x in X:
if x in d_x:
d_x[x] += 1
else:
d_x[x] = 1
# 计算每个元素出现的概率
p_x = dict()
for x in d_x.keys():
p_x[x] = d_x[x] / X.size
# 使用字典统计每一个y元素出现的次数
d_y = dict() # y的字典
for y in Y:
if y in d_y:
d_y[y] += 1
else:
d_y[y] = 1
# 计算每个元素出现的概率
p_y = dict()
for y in d_y.keys():
p_y[y] = d_y[y] / Y.size
# 使用字典统计每一个(x,y)元素出现的次数
d_xy = dict() # x的字典
for i in range(X.size):
if (X[i], Y[i]) in d_xy:
d_xy[X[i], Y[i]] += 1
else:
d_xy[X[i], Y[i]] = 1
# 计算每个元素出现的概率
p_xy = dict()
for xy in d_xy.keys():
p_xy[xy] = d_xy[xy] / X.size
# print(d_x, d_y, d_xy)
# print(p_x, p_y, p_xy)
# 初始化互信息值为0
mi = 0
for xy in p_xy.keys():
mi += p_xy[xy] * np.log(p_xy[xy] / (p_x[xy[0]] * p_y[xy[1]]))
# print(mi)
return mi
条件互信息:
'''
功能:计算条件互信息。条件互信息计算公式 I(X;Y|Z) = sigma(p_xyz * ln(p_xy|z / (p_x|z * p_y|z)))
输入:data : 列数为3的dataframe
输出:计算并返回条件互信息值,已知第三列变量的条件下前两列变量之间相互依赖的程度
'''
def ConMutualInfo(data):
# 重新设置输入数据data的列名为'x','y','z'
data.columns = ['x','y','z']
# 获取不重复的(x,y,z)
data_xyz = data.drop_duplicates(subset=None, keep='first', inplace=False)
# 初始化条件互信息mi
mi = 0
# 遍历每一个不同的(x,y,z)
for i in range(data_xyz.shape[0]):
x = data_xyz.iloc[i]['x']
y = data_xyz.iloc[i]['y']
z = data_xyz.iloc[i]['z']
# 统计(x,y,z)出现的次数count_xyz
# count_xyz = (data[data['x']==2].index & data[data['y']==1].index).shape[0]
count_xyz = data.query("x=="+str(x) + " & y==" + str(y) + " & z==" + str(z)).shape[0]
# 计算(x,y,z)出现的概率p_xyz
p_xyz = count_xyz/data.shape[0]
# 统计z出现的次数count_z
data_z = data[data['z']==z]
count_z = data_z.shape[0]
# 计算条件概率:在当前的z下(x,y)出现的概率p_xy|z
p_xy_z = count_xyz/count_z
# 计算条件概率:在当前的z下x出现的概率p_x|z
count_xz = data.query("x=="+str(x) + " & z==" + str(z)).shape[0]
p_x_z = count_xz/count_z
# 计算条件概率:在当前的z下y出现的概率p_y|z
count_yz = data.query("y=="+str(y) + " & z==" + str(z)).shape[0]
p_y_z = count_yz/count_z
# print(p_xyz*np.log(p_xy_z/(p_x_z*p_y_z)))
mi += p_xyz*np.log(p_xy_z/(p_x_z*p_y_z))
# print(mi)
return mi

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 27
27 1
1- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)