PDFPlumber使用入门
背景最近需要一个工具来解析PDF文件,获取其文本内容、标题、表格等,在GitHub上发现了这个神仙工具,发现用起来还挺方便的。在这里做一个简单的介绍,帮助一些想入门的英文不好的同学。环境macOS 10.14PDFPlubmer v0.5.21python>=3.5教程开始首先附上GitHub链接:GitHub - jsvine/pdfplumber: Plumb a PDF for det
背景
最近需要一个工具来解析PDF文件,获取其文本内容、标题、表格等,在GitHub上发现了这个神仙工具,发现用起来还挺方便的。在这里做一个简单的介绍,帮助一些想入门的英文不好的 同学。
环境
macOS 10.14
PDFPlubmer v0.5.21
python>=3.5
教程开始
应用场景
获取PDF中的每个文本字符、矩形和行的详细信息,以及可以进行表格提取和可视化调试。主要应用于机器生成的PDF上,而非扫描的pdf文档。
安装
可以直接使用pip进行python包的安装,执行指令:
pip install pdfplumber
之后运行python,若能成功导入该包即安装成功。
$ python3
Python 3.6.5 (default, Jun 17 2018, 12:13:06)
[GCC 4.2.1 Compatible Apple LLVM 9.1.0 (clang-902.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pdfplumber
>>> # 安装成功
命令行使用
这里提供一个官方的简单的使用样例
$ curl "https://cdn.rawgit.com/jsvine/pdfplumber/master/examples/pdfs/background-checks.pdf" > background-checks.pdf
$ pdfplumber < background-checks.pdf > background-checks.csv
执行完成后即可将一个pdf中的各种详细信息,包含每一个字符、线、表格等,导出到一个csv文件中。
可选参数
| 参数 | 描述 |
|---|---|
--format [format] | csv or json。json格式返回更多信息; 它包含PDF级别的元数据(metadata)和每个页面的高度/宽度信息。 |
--pages [list of pages] | 一个以空格分隔,以1索引开头的页面或带连字符的页面范围的列表。例如 1,11-15,它将返回第1、11、12、13、14和15页的数据。 |
--types [list of object types to extract] | 选择为char、anno、line、curve、rect、rect_edge。默认为 char,anno,line,curve,rect。 |
Python包
简单样例
import pdfplumber
with pdfplumber.open("path/to/file.pdf") as pdf:
first_page = pdf.pages[0]
print(first_page.chars[0])
读取PDF
pdfplumber提供了两种读取pdf的方式:
pdfplumber.open("path/to/file.pdf")pdfplumber.load(file_like_object)
这两种方法都返回pdfplumber.PDF类的实例(instance)。
加载带密码的pdf需要传入参数password,例如:pdfplumber.open("file.pdf", password = "test")
pdfplumber.PDF类
处于最上层的pdfplumber.PDF类表示单个PDF,并且具有两个主要属性:
| 属性 | 描述 |
|---|---|
.metadata | 从PDF的Info中获取元数据键 /值对字典。 通常包括“ CreationDate”,“ ModDate”,“ Producer”等。 |
.pages | 一个包含pdfplumber.Page实例的列表,每一个实例代表PDF每一页的信息。 |
pdfplumber.Page类
pdfplumber.Page类是pdfplumber整个的核心,大多数操作都围绕这个类进行操作,它具有以下几个属性:
| 属性 | 描述 |
|---|---|
.page_number | 页码顺序,从第一页的1开始,第二页为2,依此类推。 |
.width | 页面宽度 |
.height | 页面高度 |
.objects/.chars/.lines/.rects/.curves/.figures/.images | 这些属性中的每一个都是一个列表,并且每个列表针对嵌入面上的每个此类对象包含一个字典。 有关更多详细信息,请参见下面的"对象(Object)"。 |
以及这些主要的方法(method):
| 方法 | 描述 |
|---|---|
.crop(bounding_box) | 返回裁剪后的页面,该bouding_box(边界框)应表示为具有值(x0, top, x1, bottom)的4元组。 裁剪后的页面保留了至少部分位于边界框内的对象。 如果对象仅部分落在该框内,则也会被涵盖。 |
.within_bbox(bounding_box) | 和.crop相似,但是只会包含完全在bounding_box内的部分。 |
.filter(test_function) | 返回仅包含.objects的页面版本,该对象的test_function(obj)返回True。 |
.extract_text(x_tolerance=0, y_tolerance=0) | 将页面的所有字符对象整理到一个字符串中。 若其中一个字符的 x1与下一个字符的x0之差大于x_tolerance,则添加空格。若其中一个字符的 doctop与下一个字符的doctop之差大于y_tolerance,则添加换行符。 |
.extract_words(x_tolerance=0, y_tolerance=0, horizontal_ltr=True, vertical_ttb=True) | 返回所有单词外观及其边界框的列表。字词被认为是字符序列,其中(对于“直立”字符)一个字符的x1和下一个字符的x0之差小于或等于x_tolerance,并且一个字符的doctop和下一个字符的doctop小于或等于y_tolerance。对于非垂直字符也采用类似的方法,但是要测量它们之间的垂直距离,而不是水平距离。参数 horizontal_ltr和vertical_ttb指示是否应从左到右(对于水平单词)/从上到下(对于垂直单词)读取字词。 |
.extract_tables(table_settings) | 从页面中提取表格数据。 有关更多详细信息,请参见下面的“表格抽取”。 |
.to_image(**conversion_kwargs) | 返回PageImage类的实例。 有关更多详细信息,请参见下面的“可视化调试”。 有关conversion_kwargs,请参见此处。 |
对象(Object)
对于每一个pdfplumber.PDF和pdfplumber.Page的实例都提供了对4种对象操作的方法。以下属性均返回所对应对象的Python列表:
.chars代表每一个独立的字符;.annos代表注释里的每一个独立的字符;.lines代表一个独立的一维的线;.rects代表一个独立的二维的矩形;.curves(弯曲,曲线)代表一系列连接的点;.images代表一个图像;
每一个对象用一个Python词典dict进行表示,具有以下属性:
| 属性 | 描述 |
|---|---|
page_number | 找到此字符的页码。 |
text | 字符文本,如"z"、“Z"或者"你”。 |
fontname | 字符的字体。 |
size | 字号。 |
adv | 等于文本宽度字体大小缩放因子。 |
upright | 字符是否是直立的。 |
height | 字符高度。 |
width | 字符宽度。 |
x0 | 字符左侧到页面左侧的距离。 |
y0 | 字符底部到页面底部的距离。 |
x1 | 字符右侧到页面左侧的距离。 |
y1 | 字符顶部到页面底部的距离。 |
top | 字符顶部到页面顶部的距离。 |
bottom | 字符底部到页面顶部的距离。 |
doctop | 字符顶部到文档顶部的距离。 |
obj_type | "char"或"anno" |
| 属性 | 描述 |
|---|---|
page_number | 找到此线的页码。 |
height | 线的高度。 |
width | 线的宽度。 |
x0 | 线的最左侧到页面左侧的距离。 |
y0 | 线的底部到页面底部的距离。 |
x1 | 线的最右侧到页面左侧的距离。 |
y1 | 线的顶部到页面底部的距离。 |
top | 线的顶部到页面顶部的距离。 |
bottom | 线的底部到页面顶部的距离。 |
doctop | 线的顶部到文档顶部的距离。 |
linewidth | 线的粗度。 |
obj_type | "line" |
| 属性 | 描述 |
|---|---|
page_number | 找到此矩形的页码。 |
height | 矩形的高度。 |
width | 矩形的宽度。 |
x0 | 矩形的最左侧到页面左侧的距离。 |
y0 | 矩形的底部到页面底部的距离。 |
x1 | 矩形的最右侧到页面左侧的距离。 |
y1 | 矩形的顶部到页面底部的距离。 |
top | 矩形的顶部到页面顶部的距离。 |
bottom | 矩形的底部到页面顶部的距离。 |
doctop | 矩形的顶部到文档顶部的距离。 |
linewidth | 矩形边框的粗度。 |
obj_type | "rect" |
| 属性 | 描述 |
|---|---|
page_number | 找到此曲线的页码。 |
points | 点,作为(x,top)元组的列表,用以描述曲线。 |
height | 曲线bounding_box的高度。 |
width | 曲线bounding_box的宽度。 |
x0 | 曲线的最左侧点到页面左侧的距离。 |
y0 | 曲线最底部点到页面底部的距离。 |
x1 | 曲线的最右侧点到页面左侧的距离。 |
y1 | 曲线最顶部点到页面底部的距离。 |
top | 曲线最顶部的点到页面顶部的距离。 |
bottom | 曲线最底部点到页面顶部的距离。 |
doctop | 曲线最顶部点到文档顶部的距离。 |
linewidth | 连线的粗度。 |
obj_type | "curve" |
此外,pdfplumber.PDF和pdfplumber.Page都提供对两个派生对象列表的访问:.rect_edges(将每个矩形分解成四行)和.edges(将.rect_edges与.lines组合)。
可视化调试
注:使用pdfplumber的可视化调试工具需要额外用到两个工具
- ImageMagick,安装指南
- ghostscript,安装指南。或直接使用
apt install ghostscript(Ubuntu) /brew install ghostscript(Mac)
使用.to_image()创建PageImage
要将任何页面(包括裁剪的页面)转换为PageImage对象,请调用my_page.to_image()。 您可以选择传递resolution = {integer}关键字参数,默认为72。例如:
im = my_pdf.pages[0].to_image(resolution=150)
PageImage对象可以在IPython / Jupyter notbook上很好地展示,它们自动呈现为单元格输出。 例如: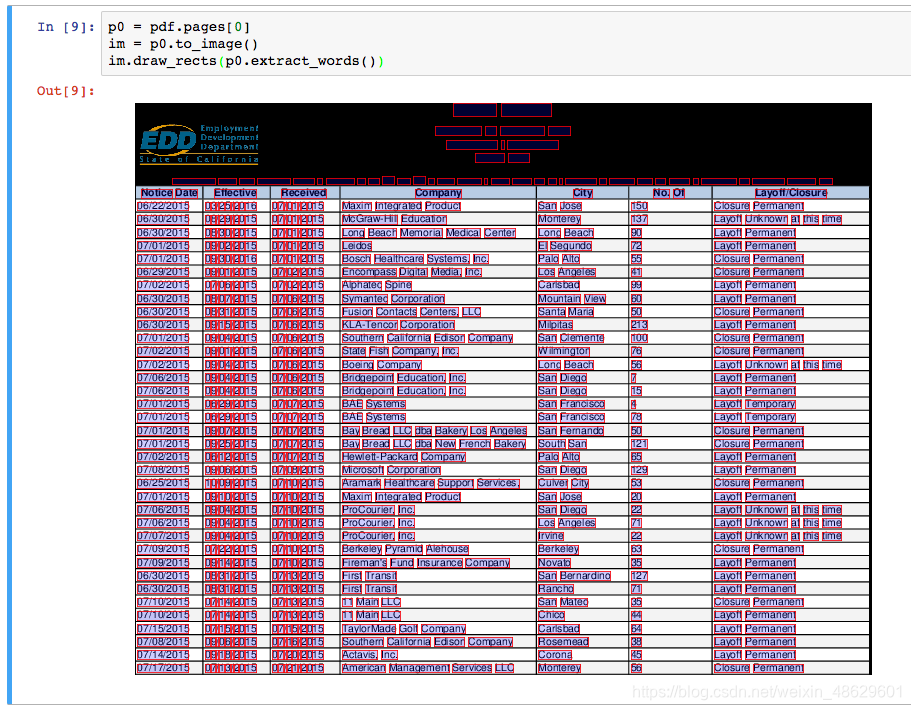
基础PageImage方法
| 方法 | 描述 |
|---|---|
im.reset() | 清除到目前为止已绘制的所有内容。 |
im.copy() | 将图像复制到新的PageImage对象。 |
im.save(path_or_fileobject, format="PNG") | 保存带注释的图像。 |
绘图方法
你可以将显式坐标或任何pdfplumber.PDF对象(例如,char,line,rect)传递给这些方法。
| 单一操作 | 批量操作 | 描述 |
|---|---|---|
im.draw_line(line, stroke={color}, stroke_width=1) | im.draw_lines(list_of_lines, **kwargs) | 用line,curve或两个2元组绘制一条线(例如((x,y), (x, y)))。 |
im.draw_vline(location, stroke={color}, stroke_width=1) | im.draw_vlines(list_of_locations, **kwargs) | 在location的x坐标处绘制一条垂直线。 |
im.draw_hline(location, stroke={color}, stroke_width=1) | im.draw_hlines(list_of_locations, **kwargs) | 在location的y坐标处绘制一条水平线。 |
im.draw_rect(bbox_or_obj, fill={color}, stroke={color}, stroke_width=1) | im.draw_rects(list_of_rects, **kwargs) | 从rect,char等或4元组边界框绘制一个矩形。 |
im.draw_circle(center_or_obj, radius=5, fill={color}, stroke={color}) | im.draw_circles(list_of_circles, **kwargs) | 在(x, y)坐标或char,rect等的中心处绘制一个圆。 |
注意:上面的方法是基于Pillow的ImageDraw方法构建的,但是已经对参数进行了调整,以与SVG的fill/stroke/stroke_width命名法保持一致。
表格抽取
pdfplumber的表检测方法大量借鉴了Anssi Nurminen的硕士学位论文(可能需要翻墙阅读),并受到Tabula的启发。 它是这样的:
- 对于任何给定的PDF页面,请找到(a)明确定义的行 且/或(b)页面上的单词对齐所隐含的行。
- 合并重叠或几乎重叠的线。
- 找到所有这些线的交点。
- 查找使用这些相交作为其顶点的最细粒度的矩形集(即单元格)。
- 将连续的单元格分组到表中。
表格抽取方法
pdfplumber.Page对象可以调用以下表格方法:
| 方法 | 描述 |
|---|---|
.find_tables(table_settings={}) | 返回Table对象的列表。Table对象提供对.cells,.rows和.bbox属性以及.extract(x_tolerance = 3, y_tolerance = 3)方法的访问。 |
.extract_tables(table_settings={}) | 返回从页面上找到的所有表中提取的文本,并以结构table -> row -> cell的形式表示为列表列表的列表。 |
.extract_table(table_settings={}) | 返回从页面上最大的表中提取的文本,以列表列表的形式显示,结构为row -> cell。 (如果多个表具有相同的大小——以单元格的数量来衡量——此方法将返回最接近页面顶部的表。) |
.debug_tablefinder(table_settings={}) | 返回TableFinder类的实例,可以访问.edges,.intersections,.cells和.tables属性。 |
例如:
pdf = pdfplumber.open("path/to/my.pdf")
page = pdf.pages[0]
page.extract_table()
表格抽取设置
默认情况下,extract_tables使用页面的垂直和水平线(或矩形边缘)作为单元格分隔符。 但是该方法可以通过table_settings参数进行高度自定义。 可能的设置及其默认值:
{
"vertical_strategy": "lines",
"horizontal_strategy": "lines",
"explicit_vertical_lines": [],
"explicit_horizontal_lines": [],
"snap_tolerance": 3,
"join_tolerance": 3,
"edge_min_length": 3,
"min_words_vertical": 3,
"min_words_horizontal": 1,
"keep_blank_chars": False,
"text_tolerance": 3,
"text_x_tolerance": None,
"text_y_tolerance": None,
"intersection_tolerance": 3,
"intersection_x_tolerance": None,
"intersection_y_tolerance": None,
}
| 设置 | 描述 |
|---|---|
"vertical_strategy" | "lines", "lines_strict", "text", 或 "explicit",具体含义见下文。 |
"horizontal_strategy" | "lines", "lines_strict", "text", 或 "explicit",具体含义见下文。 |
"explicit_vertical_lines" | 明确划分表中单元格的垂直线列表,用于明确划分表格中的单元格。 可以与以上任何策略结合使用。 列表中的项目应为数字(表示页面的整个高度的线条的x坐标)或line/rect/curve对象。 |
"explicit_horizontal_lines" | 明确划分表中单元格的水平线列表。 可以与以上任何策略结合使用。 列表中的项目应为数字(表示页面的整个高度的线条的y坐标)或line/rect/curve对象。 |
"snap_tolerance" | snap_tolerance像素内的平行线将被“捕捉”到相同的水平或垂直位置。 |
"join_tolerance" | 同一条直线上的线段(其末端在彼此的join_tolerance之内)将被“拼接”为单个线段。 |
"edge_min_length" | 短于edge_min_length的边将在尝试重建表之前被丢弃。 |
"min_words_vertical" | 使用"vertical_strategy": " text"时,至少min_words_vertical个单词必须共享相同的对齐方式。 |
"min_words_horizontal" | 使用"horizontal_strategy": " text"时,至少min_words_horizontal个单词必须共享相同的对齐方式。 |
"keep_blank_chars" | 使用text策略时,将" "字符作为单词的一部分而不是单词分隔符。 |
"text_tolerance","text_x_tolerance","text_y_tolerance" | 当text策略搜索单词时,它将期望每个单词中的各个字母相差不超过text_tolerance像素。(tolerance:容忍) |
"intersection_tolerance","intersection_x_tolerance","intersection_y_tolerance" | 将边缘合并为单元格时,正交边缘必须在intersection_tolerance像素内才能被视为相交。 |
表格抽取策略
vertical_strategy和horizontal_strategy都接受以下选项:
| 策略 | 描述 |
|---|---|
"lines" | 使用页面的图形线(包括矩形对象的边)作为潜在表格单元格的边界。 |
"lines_strict" | 使用页面的图形线(而不是矩形对象的边)作为潜在表格单元格的边界。 |
"text" | 对于vertical_strategy:推导连接页面上单词的左,右或中心的(虚构)线,并将这些线用作潜在的表格单元格的边界。对于 horizontal_strategy:相同,但使用顶部的单词。 |
"explicit" | 仅使用在explicit_vertical_lines / explicit_horizontal_lines中显式定义的行。 |
注意
-
在尝试提取表之前,裁剪页面通常很有帮助
Page.crop(bounding_box)。 -
pdfplumber的表提取已针对v0.5.0进行了彻底的重新设计,并引入了很多显著更新。
引用
https://github.com/jsvine/pdfplumber

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 29
29 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)