spss之数据预处理
文章目录目录一、spss对数据进行预处理问题思考:二、缺失类型完全随机缺失(MCAR)随机缺失(MAR)非随机缺失(MNAR)三、缺失值填补的方法完整观测数据分析填补:单值插补多重插补四、缺失值填补的过程描述缺失值的模式描述性:估计含有缺失值的变量的平均值、标准差、协方差和相关性矩阵对数据进行填补五、案例分析一、spss对数据进行预处理问题思考:1.为什么要进行数据预处理?基于样本推断总体,样本应
目录
描述性:估计含有缺失值的变量的平均值、标准差、协方差和相关性矩阵
一、spss对数据进行预处理
问题思考:
1.为什么要进行数据预处理?
- 基于样本推断总体,样本应当具有代表性
- 数据缺失导致信息丢失
2.缺失类型?
- 完全随机缺失
- 随机缺失
- 非随机缺失
3.哪些方法可用于缺失值处理?
- 删除缺失值的记录、观测、个体
- 填补:中位数填补、均值填补、多重插补
4.缺失值处理的过程/步骤?
二、缺失类型
-
完全随机缺失(MCAR)
缺失数据/变量与观察到的数据/变量和未观察到的数据/变量均没有关系(缺失与任何变量无关)
数据缺失后,剩余完整的数据任然具有代表性,只是样本量减少,估计精度变小
-
随机缺失(MAR)
缺失数据/变量与观察到的数据/变量有关,与未观察到的数据/变量无关
-
非随机缺失(MNAR)
缺失数据/变量与未观察到的数据/变量有关
三、缺失值填补的方法
-
完整观测数据分析
直接删除缺失的记录/观测/个体
适用于:缺失率较低(0.05)并且假设完全随机缺失的情况
-
填补:
单值插补
- 均值填补,中位数填补
- EM(Expectation-Maximization)--期望最大化
假设:缺失的数据为随机缺失,缺失与观测数据有关,与本身无关
假设缺失数据的分布(先验分布)并通过迭代最大化(MLE)假设分布的参数(后验分布)
- 回归(regression)
假设:缺失数据为完全随机缺失
多个线性回归估计值+随机误差
多重插补
优点:插补多个数据,考虑到了数据的波动性(方差),插补数据更加精确,更符合数据的特点
四、缺失值填补的过程
-
描述缺失值的模式
哪些变量缺失?缺失的比例?缺失的模式?
-
描述性:估计含有缺失值的变量的平均值、标准差、协方差和相关性矩阵
- 列表法:
假设:完全随机缺失
数据:完整数据
- 成对法:
假设:完全随机缺失
- 回归法
假设:完全随机缺失
- EM法:
假设:随机缺失
-
对数据进行填补
五、案例分析
---本案例是选自2021年第九届“泰迪”数据挖掘挑战赛的A题的数据
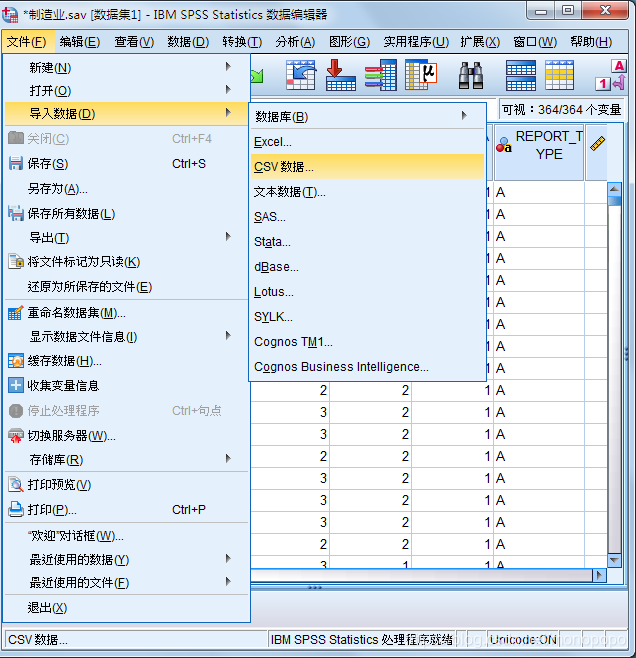
导入与合并数据
将附件2与附件1的数据(按照文件类型)导入到spss中,并且将数据合并
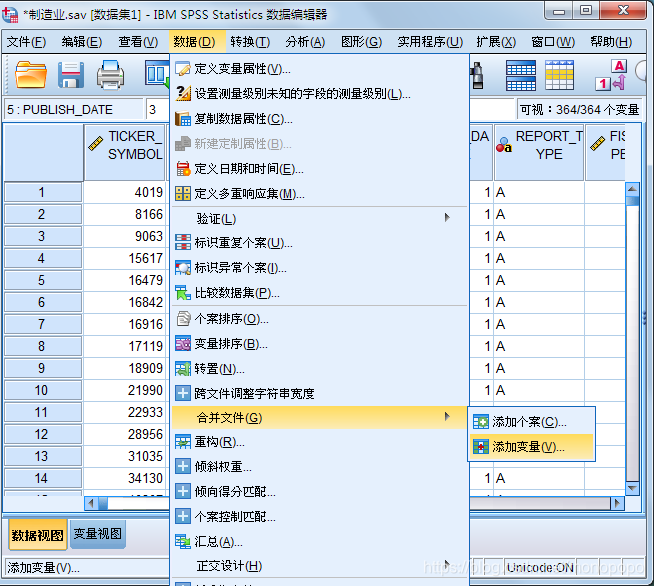
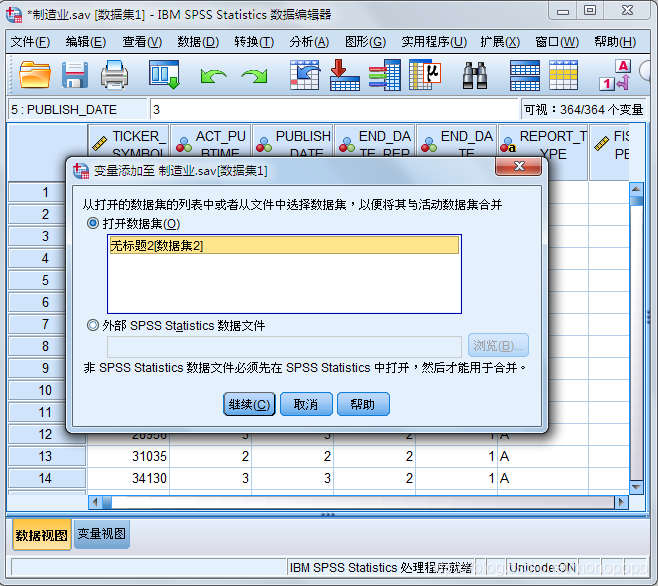
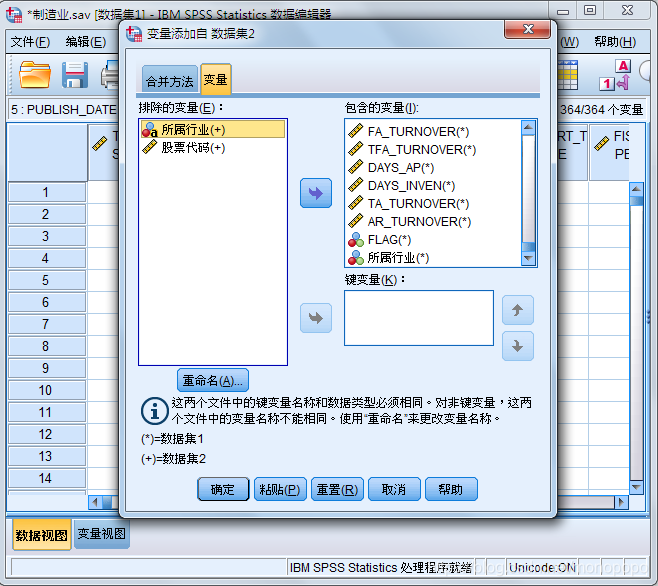
将需要的变量合并到数据表内,不需要的移到排除变量
重新编码变量
由于增加变量“所属行业”为字符串,在后续的数据处理过程会出现错误,此处进行重新编码,将各行业转变为相应的数字
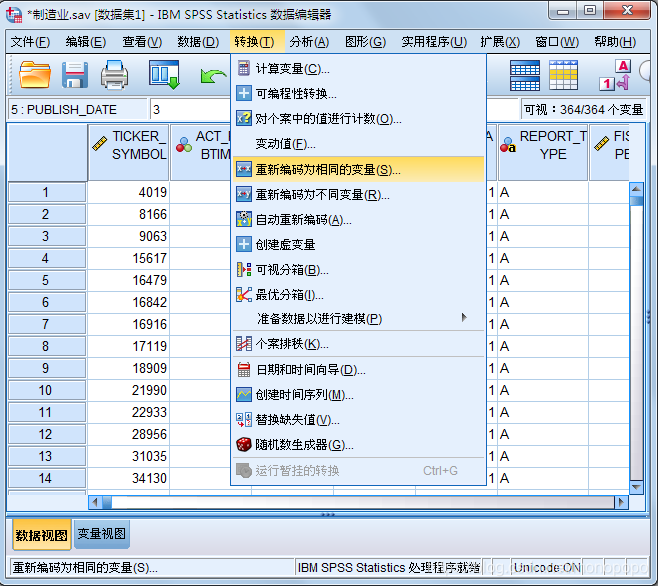
将所需要重新编码的变量选择到数字变量窗口中
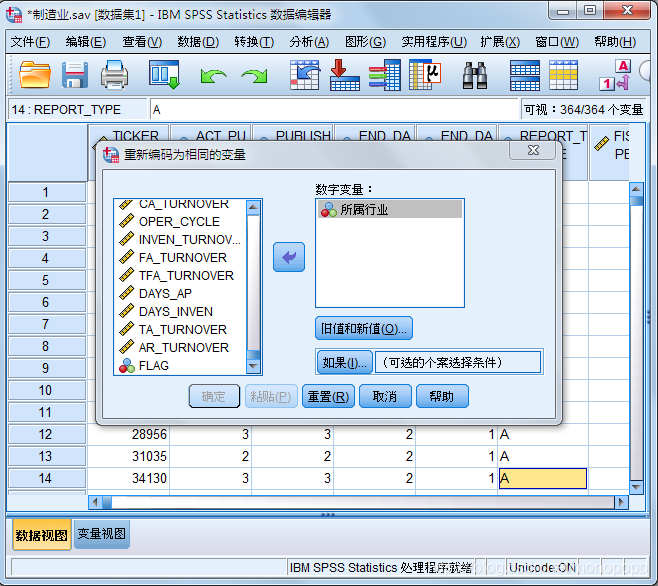
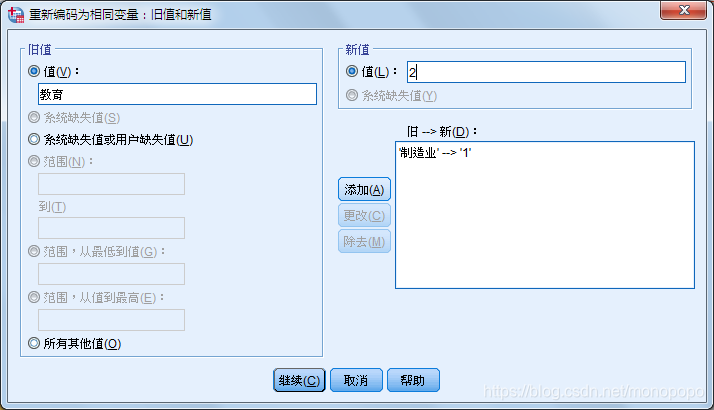
点击“旧值和新值”,将需要转变的变量分别填入旧值与新值,如下所示
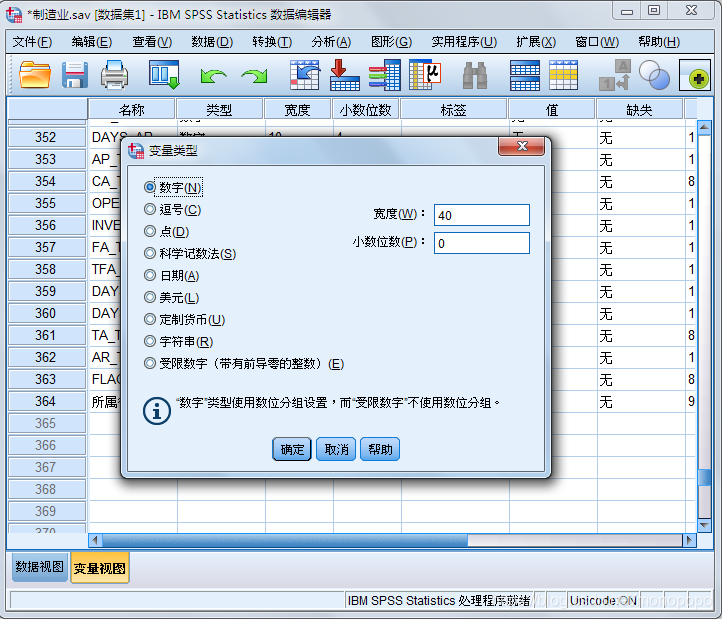
重新编码变量后,需要在变量视图中将变量类型调整为数字
筛选数据
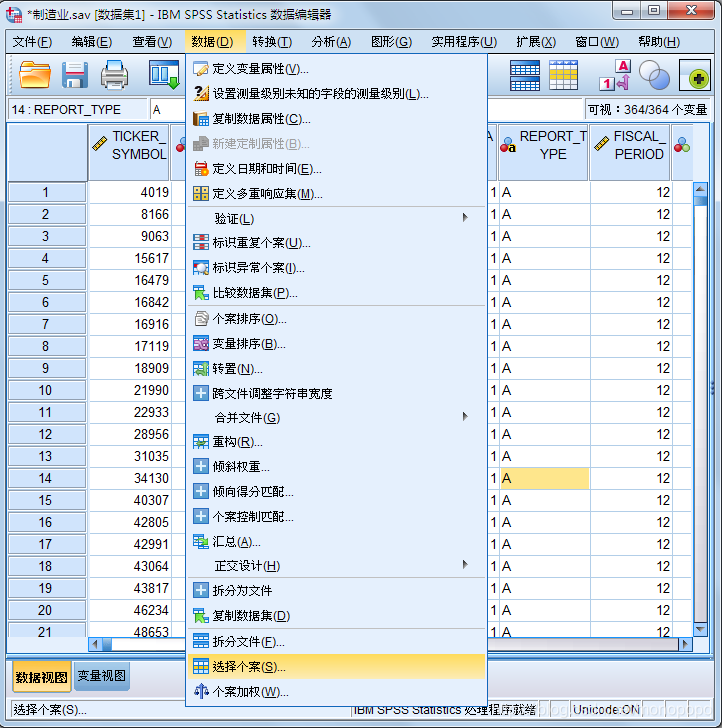
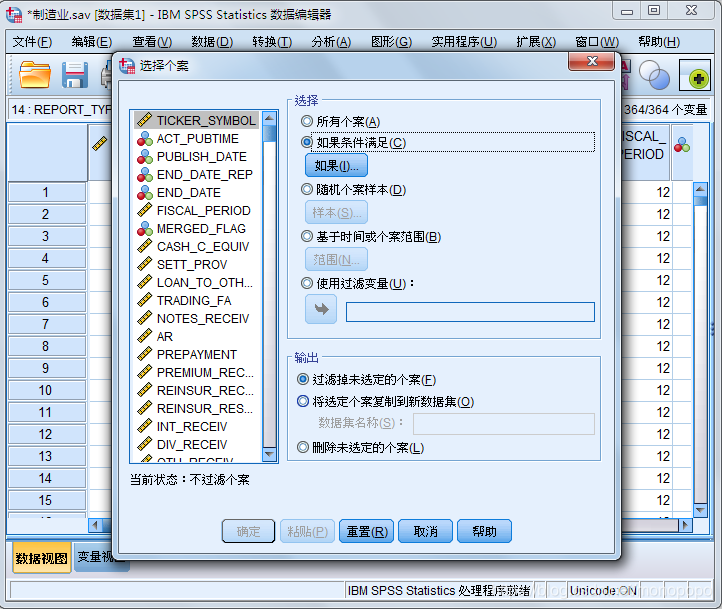
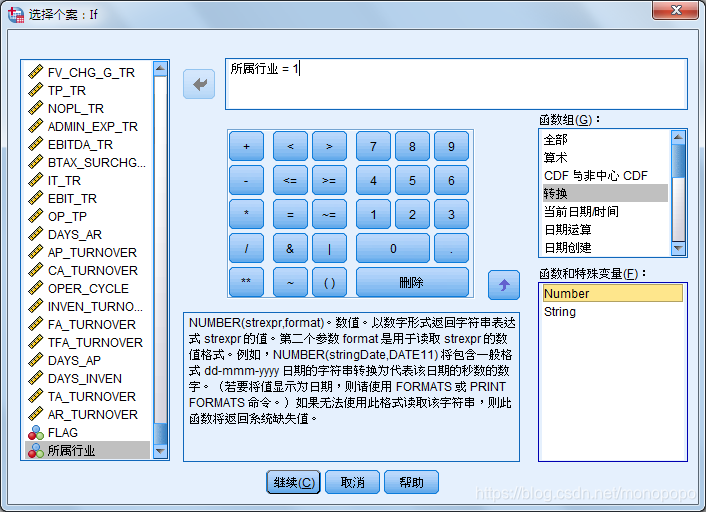
此处筛选的是“制造业”(制造业--1)的所有个案
将筛选好的数据写入到新的数据表内,并命名为“制造业”
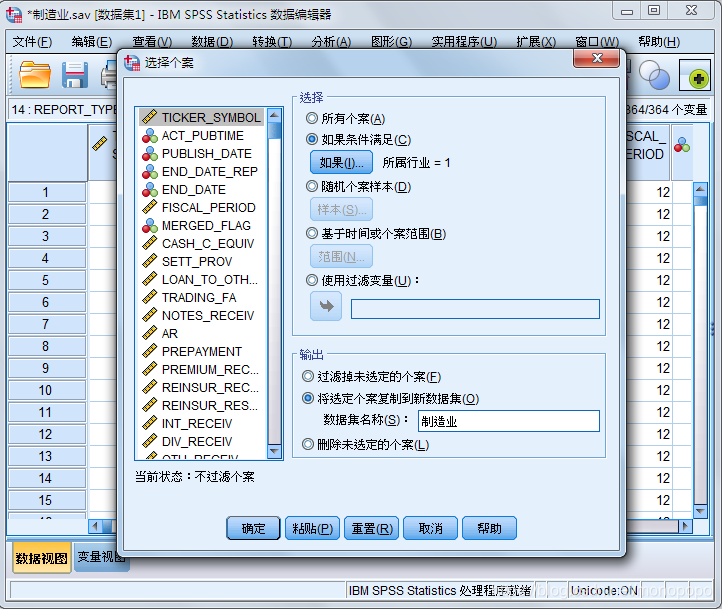
该步骤完成后,得到个案数为(2667个)
缺失值情况分析
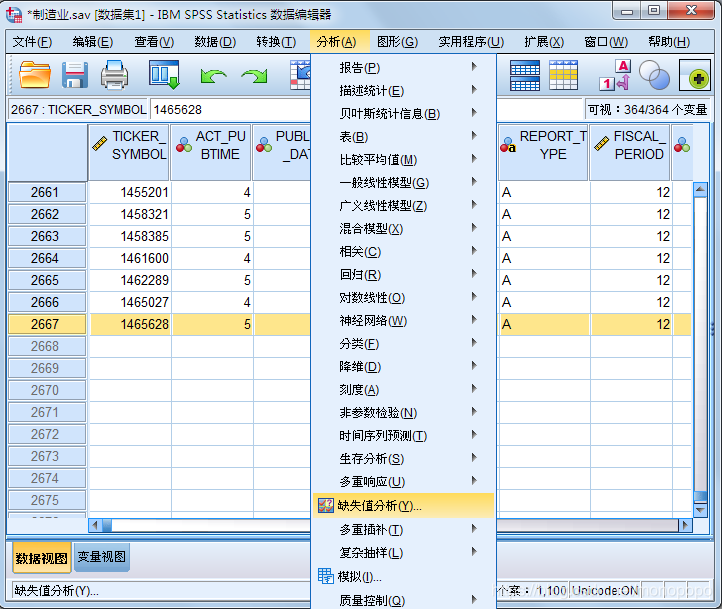
需要观测的连续型变量拉倒“定量变量”窗口
部分运行结果如下所示(建议:由于变量的数量较多,可将缺失率超过80%的变量去除)
个人建议:spss对于数据量庞大的样本,运行所需时间不太友好,使用python分析缺失值的情况更有效
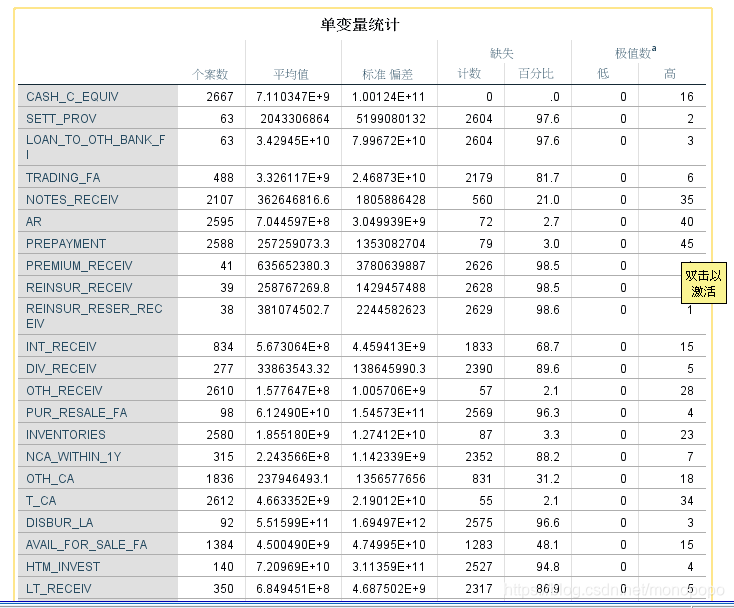
python方法去除缺失值为80%以上的缺失值
import pandas as pd
data = pd.read_csv('C:/Users/yezixbo/Desktop/111.csv',encoding='gb2312')
print(data.head())data.isnull().sum()
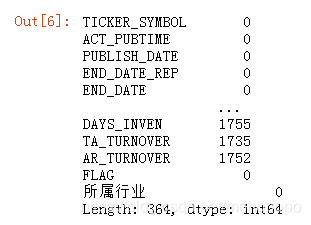
data2=data.dropna(thresh=2134.4,axis=1)
print(data2)
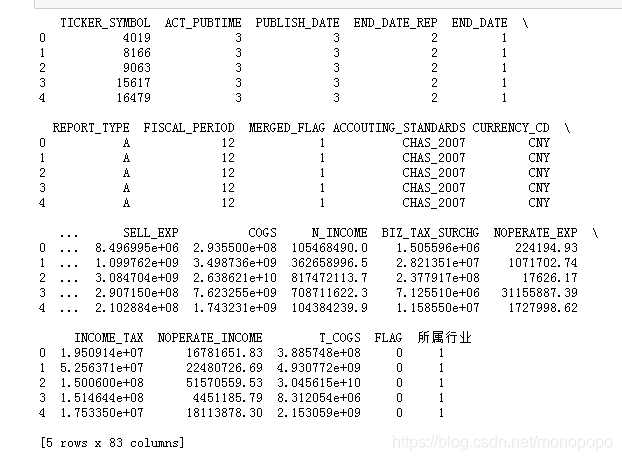
import xlwt
data2.to_csv('C:/Users/yezixbo/Desktop/制造业数据.csv')
缺失值填充
因变量FLAG(财务造假=1,财务非造假=0)
将财务造假与财务非造假的个案分离,再进行缺失值填充
(在进行缺失值填充前,需要检验缺失的类型是什么,是完全随机缺失,随机缺失,或则是不完全随机缺失,再选择合适的方法填补缺失值)
此处省略。。。。。。
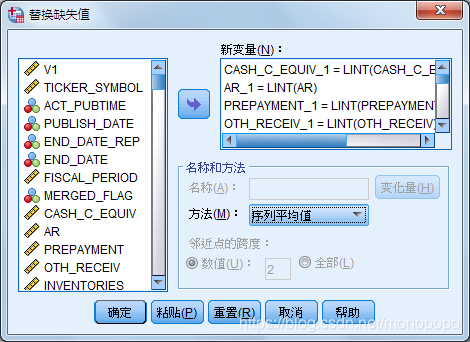
下表为数据填充完成后,财务造假与财务非造假数据的合并表
数据处理到这里就结束了!!

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)