朴素贝叶斯处理鸢尾花数据集分类
一、实验目的(1)掌握贝叶斯算法原理;(2)掌握朴素贝叶斯原理;(3)使用朴素贝叶斯处理鸢尾花数据集分类二、实验内容(1)导入库,加载鸢尾花数据,输出样本和鸢尾花特征(2)数据分割,数据分割,形成模型训练数据和测试数据(3)高斯贝叶斯模型构建(4)计算预测值并计算准确率(5)画图三、实验代码import numpy as npimport pandas as pdimport matplotlib
一、实验目的
(1) 掌握贝叶斯算法原理;
(2) 掌握朴素贝叶斯原理;
(3) 使用朴素贝叶斯处理鸢尾花数据集分类
二、实验内容
(1)导入库,加载鸢尾花数据,输出样本和鸢尾花特征
(2)数据分割,数据分割,形成模型训练数据和测试数据
(3)高斯贝叶斯模型构建
(4)计算预测值并计算准确率
(5)画图
三、实验代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn.preprocessing import StandardScaler, MinMaxScaler, PolynomialFeatures
from sklearn.naive_bayes import GaussianNB
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
data = pd.read_csv('iris.csv',header=None)
x = data.drop([4],axis=1)
x = x.drop([0],axis=0)
x = np.array(x,dtype=float)
print(x)
y=pd.Categorical(data[4]).codes
print(data[4])
y=y[1:151]
print(y)
p=x[:,2:5]
x_train1,x_test1,y_train1,y_test1=train_test_split(x,y,train_size=0.8,random_state=14)
x_train,x_test,y_train,y_test=x_train1,x_test1,y_train1,y_test1
print('训练数据集样本数目:%d,测试数据集样本数目:%d'%(x_train.shape[0],x_test.shape[0]))
clf=GaussianNB()
ir=clf.fit(x_train,y_train)
y_pred=ir.predict(x_test)
acc = np.sum(y_test == y_pred)/x_test.shape[0]
print('测试集准确度:%.3f'% acc)
y_pred = ir.predict(x_train)
acc = np.sum(y_train == y_pred)/x_train.shape[0]
print('训练集准确度:%.3f'% acc)
print('选取前两个特征值')
p=x[:,:2]
p_train1,p_test1,y_train1,y_test1=train_test_split(p,y,train_size=0.8,random_state=1)
p_train,p_test,y_train,y_test=p_train1,p_test1,y_train1,y_test1
print('训练数据集样本数目:%d,测试数据集样本数目:%d'%(p_train.shape[0],p_test.shape[0]))
clf=GaussianNB()
ir=clf.fit(p_train,y_train)
y_pred=ir.predict(p_test)
acc = np.sum(y_test == y_pred)/p_test.shape[0]
print('测试集准确度:%.3f'% acc)
y_pred = ir.predict(p_train)
acc = np.sum(y_train == y_pred)/p_train.shape[0]
print('训练集准确度:%.3f'% acc)
p1_max,p1_min = max(p_test[:,0]),min(p_test[:,0])
p2_max,p2_min = max(p_test[:,1]),min(p_test[:,1])
t1 = np.linspace(p1_min,p1_max,500)
t2 = np.linspace(p2_min,p2_max,500)
p1,p2 = np.meshgrid(t1,t2)#生成网格采样点
p_test1 = np.stack((p1.flat, p2.flat), axis=1)
y_hat = ir.predict(p_test1)
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
plt.figure(facecolor='w')
plt.pcolormesh(p1, p2, y_hat.reshape(p1.shape),shading='auto', cmap=cm_light) # 预测值的显示
plt.scatter(p_test[:, 0], p_test[:, 1], c=y_test, edgecolors='k', s=50, cmap=cm_dark) # 样本
plt.xlabel(u'花萼长度', fontsize=14)
plt.ylabel(u'花萼宽度', fontsize=14)
plt.title(u'GaussianNB对鸢尾花数据的分类结果', fontsize=16)
plt.grid(True)
plt.xlim(p1_min, p1_max)
plt.ylim(p2_min, p2_max)
plt.show()
print('选取后两个特征值')
q=x[:,2:4]
q_train1,q_test1,y_train1,y_test1=train_test_split(q,y,train_size=0.8,random_state=1)
q_train,q_test,y_train,y_test=q_train1,q_test1,y_train1,y_test1
print('训练数据集样本数目:%d,测试数据集样本数目:%d'%(q_train.shape[0],q_test.shape[0]))
clf=GaussianNB()
ir=clf.fit(q_train,y_train)
y_pred=ir.predict(q_test)
acc = np.sum(y_test == y_pred)/q_test.shape[0]
print('测试集准确度:%.3f'% acc)
y_pred = ir.predict(q_train)
acc = np.sum(y_train == y_pred)/q_train.shape[0]
print('训练集准确度:%.3f'% acc)
q1_max,q1_min = max(q_test[:,0]),min(q_test[:,0])
q2_max,q2_min = max(q_test[:,1]),min(q_test[:,1])
t1 = np.linspace(q1_min,q1_max,500)
t2 = np.linspace(q2_min,q2_max,500)
q1,q2 = np.meshgrid(t1,t2)#生成网格采样点
q_test1 = np.stack((q1.flat, q2.flat), axis=1)
y_hat = ir.predict(q_test1)
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
plt.figure(facecolor='w')
plt.pcolormesh(q1, q2, y_hat.reshape(q1.shape),shading='auto', cmap = cm_light) # 预测值的显示
plt.scatter(q_test[:, 0], q_test[:, 1], c=y_test, edgecolors='k', s=50, cmap= cm_dark) # 样本
plt.xlabel(u'花瓣长度', fontsize=14)
plt.ylabel(u'花瓣宽度', fontsize=14)
plt.title(u'GaussianNB对鸢尾花数据的分类结果', fontsize=16)
plt.grid(True)
plt.xlim(q1_min, q1_max)
plt.ylim(q2_min, q2_max)
plt.show()
print('选第一个特征值')
a=x[:,:1]
a_train1,a_test1,y_train1,y_test1=train_test_split(a,y,train_size=0.8,random_state=1)
a_train,a_test,y_train,y_test=a_train1,a_test1,y_train1,y_test1
print('训练数据集样本数目:%d,测试数据集样本数目:%d'%(a_train.shape[0],a_test.shape[0]))
clf=GaussianNB()
ir=clf.fit(a_train,y_train)
y_pred=ir.predict(a_test)
acc = np.sum(y_test == y_pred)/a_test.shape[0]
print('测试集准确度:%.3f'% acc)
y_pred = ir.predict(a_train)
acc = np.sum(y_train == y_pred)/a_train.shape[0]
print('训练集准确度:%.3f'% acc)
print('选第二个特征值')
b=x[:,1:2]
b_train1,b_test1,y_train1,y_test1=train_test_split(b,y,train_size=0.8,random_state=1)
b_train,b_test,y_train,y_test=b_train1,b_test1,y_train1,y_test1
print('训练数据集样本数目:%d,测试数据集样本数目:%d'%(b_train.shape[0],b_test.shape[0]))
clf=GaussianNB()
ir=clf.fit(b_train,y_train)
y_pred=ir.predict(b_test)
acc = np.sum(y_test == y_pred)/b_test.shape[0]
print('测试集准确度:%.3f'% acc)
y_pred = ir.predict(b_train)
acc = np.sum(y_train == y_pred)/b_train.shape[0]
print('训练集准确度:%.3f'% acc)
print('选第三个特征值')
c=x[:,2:3]
c_train1,c_test1,y_train1,y_test1=train_test_split(c,y,train_size=0.8,random_state=1)
c_train,c_test,y_train,y_test=c_train1,c_test1,y_train1,y_test1
print('训练数据集样本数目:%d,测试数据集样本数目:%d'%(c_train.shape[0],c_test.shape[0]))
clf=GaussianNB()
ir=clf.fit(c_train,y_train)
y_pred=ir.predict(c_test)
acc = np.sum(y_test == y_pred)/c_test.shape[0]
print('测试集准确度:%.3f'% acc)
y_pred = ir.predict(c_train)
acc = np.sum(y_train == y_pred)/c_train.shape[0]
print('训练集准确度:%.3f'% acc)
print('选第四个特征值')
d=x[:,3:4]
d_train1,d_test1,y_train1,y_test1=train_test_split(d,y,train_size=0.8,random_state=1)
d_train,d_test,y_train,y_test=d_train1,d_test1,y_train1,y_test1
print('训练数据集样本数目:%d,测试数据集样本数目:%d'%(d_train.shape[0],d_test.shape[0]))
clf=GaussianNB()
ir=clf.fit(d_train,y_train)
y_pred=ir.predict(d_test)
acc = np.sum(y_test == y_pred)/d_test.shape[0]
print('测试集准确度:%.3f'% acc)
y_pred = ir.predict(d_train)
acc = np.sum(y_train == y_pred)/d_train.shape[0]
print('训练集准确度:%.3f'% acc)
四、实验结果与分析
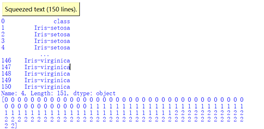
1、成功加载鸢尾花数据,并输出样本和特征
2、成功进行数据分割,形成模型训练数据和测试数据,高斯贝叶斯模型构建完成后,可计算预测值并计算准确率

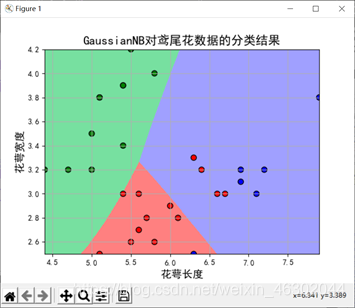
3、取样本前两个特征值,成功计算预测值并计算准确率
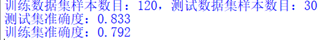
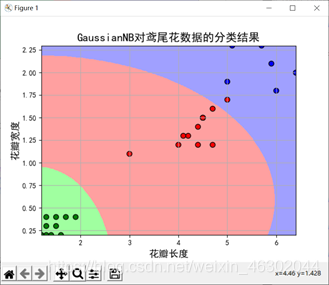
4、取样本后两个特征值,成功计算预测值并计算准确率

5、取样本第一个特征值,成功计算预测值并计算准确率

6、取样本第二个特征值,成功计算预测值并计算准确率

7、取样本第三个特征值,成功计算预测值并计算准确率

8、取样本第四个特征值,成功计算预测值并计算准确率

9、当训练样本与测试样本比为3:2时

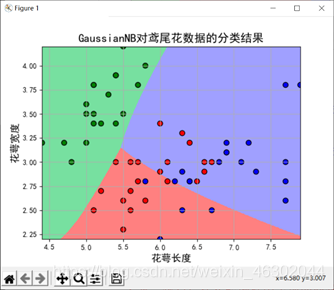

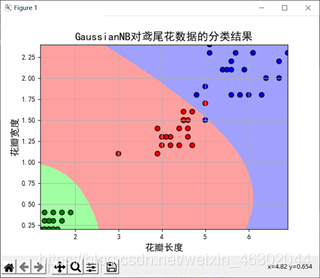
我们发现前两个特征值误差变大,但后两个特征值的误差没有明显变化。
10、当训练样本与测试样本比为9:1时

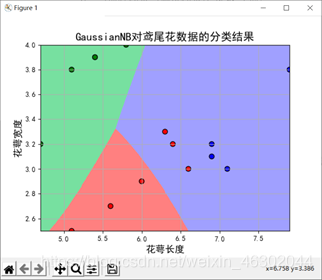

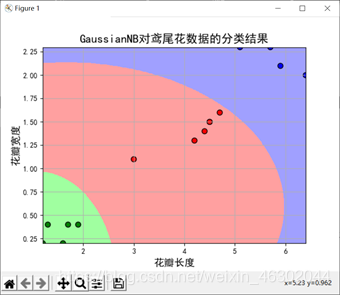
我们发现前两个特征值测试误差变大,后两个特征值测试误差变小
11、经过分析发现,前两个特征值对检测结果的误差更大,后两个特征值更适合进行分类。
训练样本与测试样本之间的比重也会在很大程度上影响到测试误差。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 11
11 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)