yolov7训练自己的数据集及报错处理
yolov7训练自己的数据集及报错处理,其实和yolov5差不太多
######################1##########################
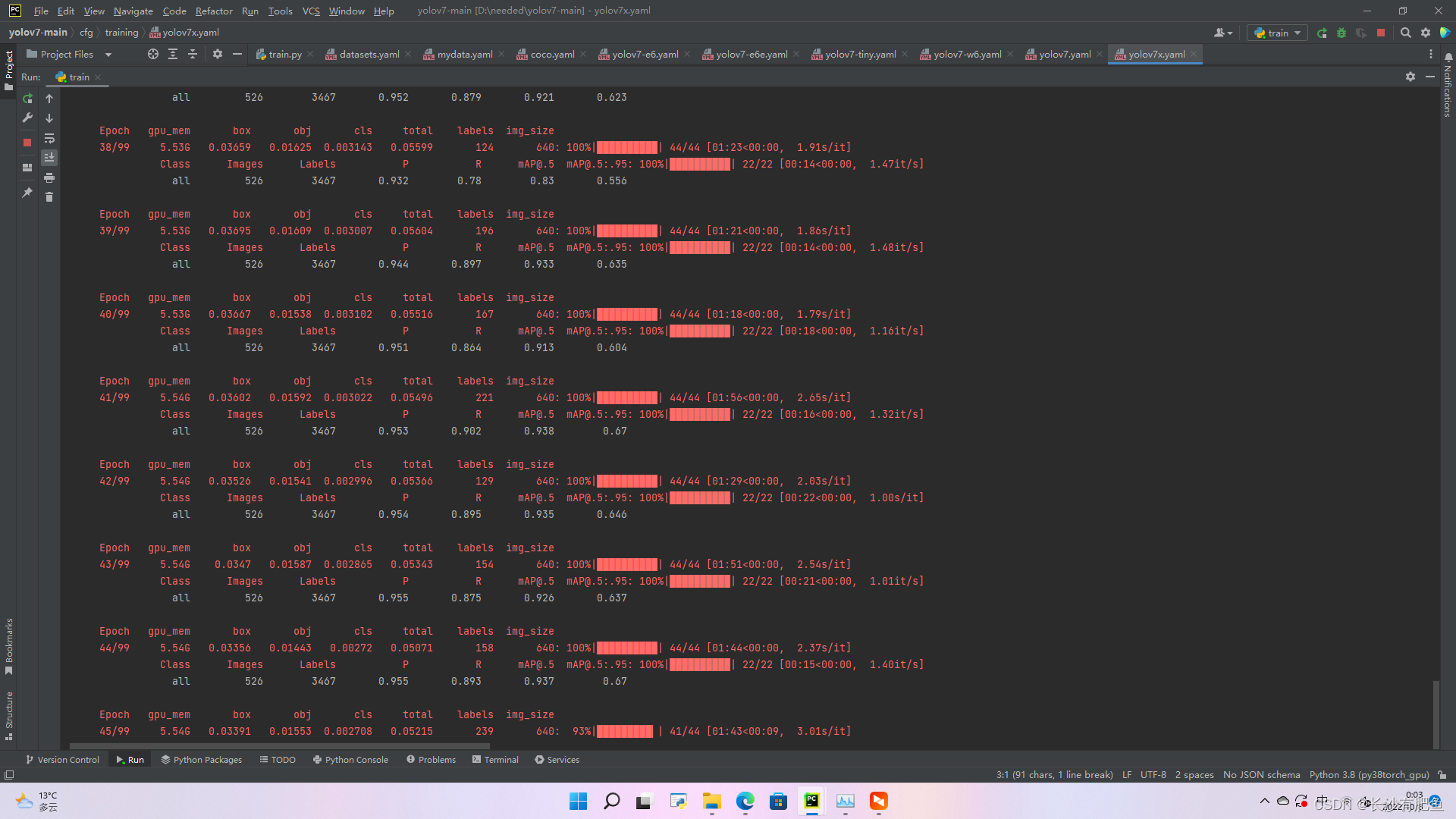
D:\Anaconda3\envs\py38torch_gpu\python.exe D:\needed\yolov7-main\train.py --weights weights/yolov7.pt --cfg cfg/training/yolov7.yaml --data data/datasets.yaml --device 0 --batch-size 8 --epoch 5
YOLOR 2022-9-16 torch 1.9.0+cu111 CUDA:0 (NVIDIA GeForce RTX 3060 Ti, 8191.5MB)Namespace(adam=False, artifact_alias='latest', batch_size=8, bbox_interval=-1, bucket='', cache_images=False, cfg='cfg/training/yolov7.yaml', data='data/datasets.yaml', device='0', entity=None, epochs=5, evolve=False, exist_ok=False, freeze=[0], global_rank=-1, hyp='data/hyp.scratch.p5.yaml', image_weights=False, img_size=[640, 640], label_smoothing=0.0, linear_lr=False, local_rank=-1, multi_scale=False, name='exp', noautoanchor=False, nosave=False, notest=False, project='runs/train', quad=False, rect=False, resume=False, save_dir='runs\\train\\exp5', save_period=-1, single_cls=False, sync_bn=False, total_batch_size=8, upload_dataset=False, v5_metric=False, weights='weights/yolov7.pt', workers=0, world_size=1)
tensorboard: Start with 'tensorboard --logdir runs/train', view at http://localhost:6006/
2022-10-07 21:29:10.393199: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'cudart64_101.dll'; dlerror: cudart64_101.dll not found
2022-10-07 21:29:10.393278: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
hyperparameters: lr0=0.01, lrf=0.1, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.3, cls_pw=1.0, obj=0.7, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.2, scale=0.9, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.15, copy_paste=0.0, paste_in=0.15, loss_ota=1
wandb: Install Weights & Biases for YOLOR logging with 'pip install wandb' (recommended)
fatal: not a git repository (or any of the parent directories): .git
Traceback (most recent call last):
File "D:\needed\yolov7-main\utils\google_utils.py", line 26, in attempt_download
assets = [x['name'] for x in response['assets']] # release assets
KeyError: 'assets'During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:\needed\yolov7-main\train.py", line 616, in <module>
train(hyp, opt, device, tb_writer)
File "D:\needed\yolov7-main\train.py", line 86, in train
attempt_download(weights) # download if not found locally
File "D:\needed\yolov7-main\utils\google_utils.py", line 31, in attempt_download
tag = subprocess.check_output('git tag', shell=True).decode().split()[-1]
File "D:\Anaconda3\envs\py38torch_gpu\lib\subprocess.py", line 415, in check_output
return run(*popenargs, stdout=PIPE, timeout=timeout, check=True,
File "D:\Anaconda3\envs\py38torch_gpu\lib\subprocess.py", line 516, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command 'git tag' returned non-zero exit status 128.Process finished with exit code 1
answer:下载yolov7.pt权重文件
修改train.py中:
parser.add_argument('--weights', type=str, default='yolov7.pt', help='initial weights path')#######################2##########################
_pickle.UnpicklingError: STACK_GLOBAL requires str找到数据集下面的图片和标签文件,删掉labels.cache,labels.cache.npy文件
yolov7用自己的数据集训练:
1.data文件夹下面的mydata.yaml文件修改:
train: D:\needed\air-filter\train\images # 训练集绝对路径 进入到训练集存放图片的文件夹里面,按ctrl+L复制过来即可 val: D:\needed\air-filter\valid\images # 验证集绝对路径 进入到验证集存放图片的文件夹里面,按ctrl+L复制过来即可 # test: D:\needed\air-filter\train\images nc: 6 # class数 names: ['aa','bb','cc','dd','ee','ff'] # 模型类别名
2.修改yolov7.yaml文件
将nc修改为自己的类别数,如果自己的GPU不给力,把下面的参数改改:
depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple
3.训练
--weights weights/'yolov7.pt' --cfg cfg/training/yolov7.yaml --data data/mydata.yaml --device 0 --batch-size 16 --epoch 100 --device 0







华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容
 免费领云主机
免费领云主机




 华为云 x DeepSeek:AI驱动云上应用创新
华为云 x DeepSeek:AI驱动云上应用创新

 DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
 华为云数字人,助力行业数字化业务创新
华为云数字人,助力行业数字化业务创新
 企业数据治理一站式解决方案及应用实践
企业数据治理一站式解决方案及应用实践
 轻松构建AIoT智能场景应用
轻松构建AIoT智能场景应用


所有评论(0)