
Python大数据分析与挖掘实战微课版答案 Python大数据分析与挖掘实战课后答案 例题 课后作业 python题目 python题库 数据分析与挖掘题库 数据分析与挖掘项目
(在此仅展示题目,所有数据、代码、答案、习题等点我头像,在资源中!!!)以下关于pandas 数据预处理说法正确的是()。A、pandas没有做哑变量的函数B、在不导入其他厍的情况下,仅仅使用 pandas就可实现聚类分析离散化C、pandas 可以实现所有的数据预处理操作D、cut 函数默认情况下做的是等宽法离散化正确答案: D 我的答案:D 得分: 10.0分2关于标准差标准化,下列说法中
(在此仅展示题目,所有数据、代码、答案、习题等点我头像,在资源中!!!)
以下关于pandas 数据预处理说法正确的是()。
- A、
pandas没有做哑变量的函数
- B、
在不导入其他厍的情况下,仅仅使用 pandas就可实现聚类分析离散化
- C、
pandas 可以实现所有的数据预处理操作
- D、
cut 函数默认情况下做的是等宽法离散化
正确答案: D 我的答案:D 得分: 10.0分
2
关于标准差标准化,下列说法中错误的是()。
- A、
经过该方法处理后的数据均值为0,标准差为1
- B、
可能会改变数据的分布情况
- C、
Python中可自定义该方法实现函数:
def StandardScaler(data):
data=(data-data.mean())/data.std()
return data
- D、
计算公式为:
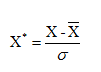
正确答案: B 我的答案:B 得分: 10.0分
3
下列与标准化方法有关的说法中错误的是()。
- A、
离差标准化简单易懂,对最大值和最小值敏感度不高
- B、
标准差标准化是最常用的标准化方法,又名零—匀值标准化
- C、
小数定标标准化实质上就是将数据按照一定的比例缩小
- D、
多个特征的数据的K-Means聚类不需要对数据进行标准化
正确答案: A 我的答案:A 得分: 10.0分
4
以下关于异常值检测的说法中错误的是()。
- A、
3δ原则利用了统计学中小概率事件的原理分布
- B、
使用箱线图方法时要求数据服从或近似服从正态分布
- C、
基于聚类的方法可以进行离群点检测
- D、
基于分类的方法可以进行离群点检测
正确答案: D 我的答案:D 得分: 10.0分
5
以下关于缺失值检测的说法中,正确的是()。
- A、
mull和notnull可以对缺失值进行处理
- B、
dropna方法既可以删除观测记录,亦可以制徐特征
- C、
fillna 方法中用来若换缺失值的值只能是数据框
- D、
pandas库中的interpolate模块包含了多种插值方法
正确答案: B 我的答案:B 得分: 10.0分
6
以下关于drop_ duplicates 函数的说法中错误的是()。
- A、
仅对DataFrame和Series 类型的数据有效
- B、
仅支持单-特征的数据去重
- C、
数据重复时默认保留第一个数据
- D、
该函数不会改变原始数据排列
正确答案: B 我的答案:B 得分: 10.0分
7
下列关于concat函数、append方法、merge函数和join方法的说法正确的是()。
- A、
concat 是最常用的主键合并的函数,能够实现内连按和外连接
- B、
append 方法只能用来做纵向堆叠,适用于所有纵向堆叠情况
- C、
merge 是最常用的主键合并的函数,但不能够实现左连接和右连接
- D、
join 是常用的主键合并方法之一,但不能够实现左连接和右连接
正确答案: D 我的答案:D 得分: 10.0分
答案解析:
8
以下关于数据分析预处理的过程描述正确的是()
- A、
数据清洗包含广数机积准化、数据合并和缺失值处理
- B、
数据合并按照合并轴方向主要分为左连接、右连接、内连接和外连接
- C、
数据分析的预处理过程主要包括效据清洗, 数据合井、敏据标准化柏数据转换,它们之间存在交叉,没有严格的先后关系。
- D、
数据标准化的主要对象是类别型的特征
正确答案: C 我的答案:C 得分: 10.0分
二.多选题(共2题,20.0分)
1
以下属于Pandas库中序列的属性的是
- A、
方法
- B、
值
- C、
切片
- D、
索引
正确答案: BD 我的答案:BD 得分: 10.0分
2
Pandas库中序列由那两部分组成
- A、
索引
- B、
切片
- C、
对应的值
- D、
对应的域
正确答案: AC 我的答案:AC 得分: 10.0分
一.单选题(共5题,50.0分)
1
Python支持多行语句,下面对于多行语句描述有误的是
- A、
一行可以书写多个语句
- B、
一个语句可以分多行书写
- C、
一行多语句可以用分号隔开
- D、
一个语句多行书写时直接按回车即可
正确答案: D 我的答案:D 得分: 10.0分
2
标识符可以用于变量、函数、对象等的命名,对于标识符描述错误的是
- A、
标识符不可以以数字开头
- B、
标识符可以由数字、字母和下划线组成
- C、
标识符不区分大小写
- D、
保留字做标识符是会出错
正确答案: C 我的答案:C 得分: 10.0分
3
对于字符串的标识,Python中可以使用的方法很多,下面正确的是
- A、
'what's happend to you ?'
- B、
"what's happend to you ?"
- C、
'what\\'s happend to you ?'
- D、
""what's "happend to you ?"
正确答案: B 我的答案:B 得分: 10.0分
4
在书写Python脚本时,需要进行必要的编码声明,关于编码声明错误的是
- A、
在首行声明有效
- B、
在第二行声明有效
- C、
在第三行声明有效
- D、
只有在首行或第二行声明才有效
正确答案: C 我的答案:C 得分: 10.0分
5
下列语法正确的是
- A、
print"hello,world"
- B、
print(‘hello,world’)
- C、
print('hello,world')
- D、
print(hello,world)
正确答案: C 我的答案:C 得分: 10.0分
二.简答题(共3题,30.0分)
1
大数据、数据分析、数据挖掘的概念分别是什么?
正确答案:
我的答案:
1、大数据(big data):
指无法在可承受的时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产;
在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编写的《大数据时代》 中大数据指不用随机分析法(抽样调查)这样的捷径,而采用所有数据进行分析处理。大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(价值)Veracity(真实性) 。
2、数据分析:
是指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。这一过程也是质量管理体系的支持过程。在实用中,数据分析可帮助人们作出判断,以便采取适当行动。
数据分析的数学基础在20世纪早期就已确立,但直到计算机的出现才使得实际操作成为可能,并使得数据分析得以推广。数据分析是数学与计算机科学相结合的产物。
3、数据挖掘(英语:Data mining):
又译为资料探勘、数据采矿。它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称:KDD)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
2
数据挖掘与分析的流程
正确答案:
我的答案:
确定任务目标
提取目标数据集
数据预处理
建立大数据分析与挖掘模型
模型的解释与评估
知识的应用
3
大数据挖掘与分析的主要功能有哪些?
正确答案:
我的答案:
数据的统计分析与特征描述
关联规则挖掘和相关性分析
分类和回归
聚类分析
异常检测活着利群点分析
三.其它(共2题,20.0分)
1
使用int函数分别对5.20、-5.20、5.60、-5.60四舍五入后取整
正确答案:
print('当数值取5.20时,四舍五入结果为:',int(5.20 + 0.5) )
print('当数值取5.60时,四舍五入结果为:',int(5.60 + 0.5) )
print('当数值取-5.20时,四舍五入结果为:',int(-5.20 - 0.5) )
print('当数值取-5.60时,四舍五入结果为:',int(-5.60 - 0.5) )
我的答案:
5;-5;6;-6
Python中int()函数采用向零取整的方式取整。
用int()实现四舍五入的功能这里分两部分实现:
当数值为正数时,在该数值上加0.5 ,例如: print('当数值取5.20时,四舍五入结果为:',int(5.20 + 0.5) ) # 结果为5
print('当数值取5.60时,四舍五入结果为:',int(5.60 + 0.5) ) # 结果为6
#当数值为负数时,在该数值上减0.5,例如: print('当数值取-5.20时,四舍五入结果为:',int(-5.20 - 0.5) ) # 结果为-5
print('当数值取-5.60时,四舍五入结果为:',int(-5.60 - 0.5) ) # 结果为-6
2
至少使用两种方法运行PyCharm,输出“Welcome to this World!”
正确答案:
我的答案:
-
print("Welcome to this World!")
-
a=input("Welcome to this World!")
print(a) -
print('Welcome to','this World!')
-
with open('D:\\Users\\x1c\\Desktop\\123.txt','w') as f:
f.write('Welcome to this World!')
f = open('123.txt','r',encoding='utf8')
for lines in f.readlines():
print(lines,end='')
f.close()
请根据新浪微博数据集,对12万左右的微博数据集进行分词、去除停用词、转化词向量等预处理操作,按照80%训练、20%测试进行随机划分数据集,构建基于微博情感分析识别模型,并计算模型的实际预测准确率。
请根据给定数据,通过提取出每个月各个站点的进站和出站的日客流量,对提取的数据进行可视化分析,完成分析周末和节假日是否能成为影响日客流量的影响因素,采用神经网络回归模型进行预测12月1日-7日客流量的数据。
请根据给定基于众包平台的任务数据和注册会员数据,分析任务定价的影响因素,并构建任务定价模型。最后利用构建的任务定价模型,对附件一的任务数据重新定价,并对新定价方案与原定价方案进行评价。
请根据给定航空公司客户数据,对航空公司数据进行处理并分析,实现以下目标:
-
借助航空公司客户数据,对客户进行分类;
-
对不同的客户类别进行特征分析,比较不同类别客户的客户价值;
-
对不同价值的客户类别提供个性化服务,指定相应的营销策略
基于财务与交易数据的量化投资分析
-
请根据Tushare平台数据,采用数量化的方法,对上市公司基本情况进行综合陪你评价,从而选出优质的上市公司;
-
根据选出的上市公司发行的A股股票,通过股票交易的技术分析指标,创建数据挖掘模型预测下一个交易日股票收盘价较开盘价的涨跌方向;
-
基于预测结果设计量化投资策略并进行实证检验。
请利用TensorFlow框架,构建多层神经网络模型,实现手写数字识别问题。
请运用TensorFlow框架,构建一个线性拟合模型f(x)=Wx+b,W和b为参数。
假设有以下数据集,每行代表一个顾客在超市的购买记录。如表所示
请利用关联规则支持度和置信度定义挖掘出任意两个商品之间的关联规则,并分析。
最小支持度和最小置信度分别为0.2和0.4
根据给定表的31个地区农村居民人均可支配收入情况作K-mean聚类分析。
企业到金融商业机构贷款,金融商业机构需要对企业进行评估。评估结果为0和1两种形式,0表示企业两年后破产,将拒绝贷款;而1表示企业2年后具备还款能力,可以贷款。如表2所示,已知前20家企业的3项评价指标值和评估结果,试建立逻辑回归模型、支持向量机模型、神经网络模型对剩余5家企业进行评估。
油气藏的储量密度Y与生油门限以下平均地温梯度X1、生油门限以下总有机碳百分比X2、生油岩体积与沉积岩百分比X3、砂泥岩厚度百分比X4、有机转化率X5有关,数据如表1所示
任务如下:
-
利用线性回归分析命令,求出Y与5个因素之间的线性回归关系式系数向量(包括常数项),并在命令窗口输出该系数向量。
-
求出线性回归关系的判定系数。
-
今有一个样本X1=4,X2=1.5,X3=10,X4=17,X5=9,试预测该样本的Y值。
请利用主成分分析对我国2019年城镇居民人均可支配收入情况进行排名,数据自行获取。
一、使用如下方法规范化数组:200,300,400,600,1000。
1. 令min =0,max=1、进行最小—最大规范化。
2. 标准差标准化
3. 小数定标规范
二、假设12个销售价格记录已经排序:5,10,13,15,35,50,55,72,92,204,215。
使用等宽法对其进行离散化处理。
三、自定义一个能够自动实现数据去重、缺失值中位数填补的函数。
根据文件“超市营业额2.xlsx”完成以下问题
1.查看单日交易总额最小的3天的交易数据,并查看这3天是周几。
2.把所有员工的工号前面增加一位数字,增加的数字和原工号最后一位相同,把修改后的数据写入新文件“超市营业额2_修改工号.xlsx”。
例如,工号1001变为11001,1003变为31003。
3.把每个员工的交易额数据写入文件“各员工的数据.xlsx”每个员工的数据占一个worksheet,结构和“超市营业额2.xlsx“一样,并以员工姓名作为worksheet的标题。
4.绘制折线图展示一个月内各柜台营业额每天的变化趋势。
5.绘制饼状图展示该月各柜台营业额在交易总额中的占比。
6.绘制柱状图展示张三在不同柜台的交易总额。
利用数据框中自身的聚合计算方法,计算并获得每个同学各科成绩的平均分,记为M1、M2、M3、M4。
创建一个Python脚本,命名为test2.py,完成以下功能:
读取以下Excel表格数据并用一个数据框变量df来保存,数据内容如下表所示:
对df第3、4列进行切片,切片后为一个新的数据框记为df1,并对df1利用自身的方法转换为Numpy数组Nt。
基于df第2列,构造一个逻辑数组TF,即满足交易日期小于等于2017-01-16且大于等于2017-01-05为真,否则为假。
以TF为索引,取Nt中的第2列交易量数据并求和,记为S。
创建一个Python脚本,命名为test1.py,完成以下功能:
读取以下4位同学的成绩并用一个数据框变量pd来保存,其中成绩保存在一个TXT文件中,如下图所示:
对pd进行切片操作,分别获得小红、张明、小江、小李各科成绩,它们是4个数据框变量,分别记为pd1、pd2、pd3、pd4。
创建一个Python脚本,命名为test3.py,完成以下功能:
(1)生成两个2×2矩阵,并计算矩阵的乘积。
(2)求矩阵求矩阵
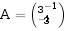
的特征值和特征向量。
(3)设有矩阵
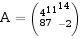
,试对其进行奇异分解。
(4)设有行列式 ,求其转置行列式DT,并计算 D和DT
创建一个Python脚本,命名为test2.py,完成以下功能:
加载练习1中生成的Python二进制数据文件,获得数组N4
提取N4第1行中的第2、4个元素,第3行中的第1、5个元素,组成一个新的二维数组N5
将N5与练习1中的N1进行水平合并,生成一个新的二维数组N6。
创建一个Python脚本,命名为test1.py,完成以下功能:
定义一个列表list1=[1,2,4,6,7,8],将其转化为数组N1
定义一个元组tup1=(1,2,3,4,5,6),将其转化为数组N2
利用内置函数,定义一个1行6列元素全为1的数组N3
将N1,N2,N3垂直连接,形成一个3行6列的二维数组N4
将N4保存为Python二进制数据文件(.npy格式)。
1.创建一个 Python 脚本命名为test1.py,实现以下功自
(1)定义一个元组t1=(1,2.'R', 'py','Matlab')和一个空列表list1。
(2)以 while循环的方式,用 append1函数依次向list1 中添加t1中的元素。
(3)定义一个空字典,命名为 dict1。
(4)定义一个嵌套列表Li-[k',[3,4,5],(1,2,6),18,501,采用for循环的方式,用setdefault(0
函数依次将Li中的元素添加到dict1中,其中Li元素对应的键依次为a、 b、c、d、e。
2.创建一个 Python脚本,
名为test2.py,实现以下功能。
圆柱体的表面积、体积,函数名为
1)定义一个函数,用于计算
comput,输入参数为底
只(S)、体积(V,返回多值的函数
可以用元组来表示。
半径r)、商(h,返回值为表面
计算底半径(r)=10、高(h)
的圆柱体表面积和体
(2)调用定义的A数 comput(
并输出其结果。
3.创建一个Python 脚本,命名为
test3.py,实现以下功能。
(1)生成两个2×2矩阵,并计算矩阵的乘积。
3-1
(2)求矩阵A=
的特征值和特征向量。
-1 3
41114
(3)设有矩阵A=
试对其进行奇异分解。
87-2
468
(4)设有行列式D=4 69,求,
5 6 8

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)