数据指标间相关性分析+假设检验
最近想做一个自动化分析指标间相关性系数的东西,不知道能做什么东西,因为连怎么进行相关性分析都不会…… 所以就从头呗,先了解相关性分析,嘿嘿。1、计算相关性系数判断:r值代表相关性强度,取值范围为[-1,1],>0 ,为正相关。<0,为负相关。|r|相关性>0.95显著性相关>=0.8&<0.95高度相关>=0.5&<0.8中度相关>=
目录
2、三个相关性系数(pearson, spearman, kendall)
①T检验——单样本T检验、配对样本T检验、独立样本均数T检验
步骤一:可视化-图表展示
折线图、散点图……
1、单个数据展示,看数据分布、异常值、缺失值……
2、多数据展示,看数据间关系
步骤二:相关系数计算
1、协方差及协方差矩阵
当两个变量变化趋势相同,协方差为正值,说明两变量正相关;
当两个变量变化趋势相反,协方差为负值,说明两变量负相关;
当两个变量相互独立,协方差为0,说明两变量不相关;
两个变量的协方差:
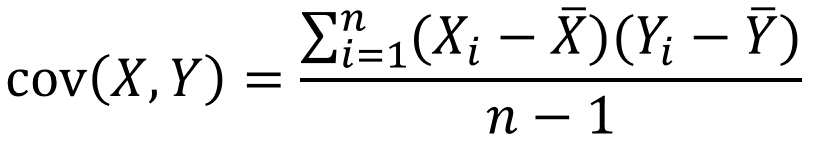
三个变量的协方差:
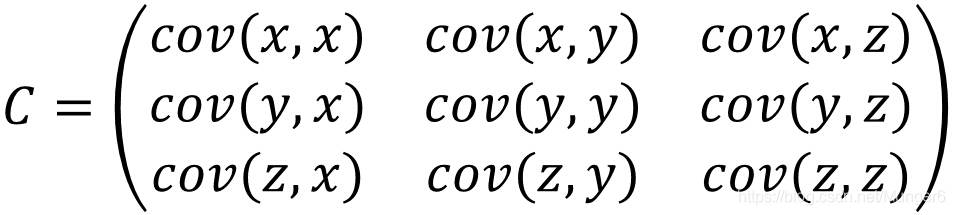
2、三个相关性系数(pearson, spearman, kendall)
反应的都是两个变量之间变化趋势的方向以及程度。
Pearson系数(不是p值):皮尔逊相关系数,线性相关系数,协方差与标准差的比值,对数据质量要求较高:
①数据是正态分布时,因为求皮尔森相关性系数以后,通常还会用t检验之类的方法来进行皮尔森相关性系数检验,而 t检验是基于数据呈正态分布的假设的。
②实验数据之间的差距不能太大,不能有离散点,异常值。
③连续性变量

Spearman系数:斯皮尔曼相关性系数,没有很多数据条件要求,当数据不是正太分布,用这个,适用范围广,适合于定序变量或不满足正态分布假设的等间隔数据。
数学建模方法——斯皮尔曼相关系数及其显著性检验 (Spearman’s correlation coefficient for ranked data)_Liu-Kevin的博客-CSDN博客_斯皮尔曼相关性分析 当样本量小于100,相关系数大于等于表中的临界值的时候。我们认为相关系数是有相关性。
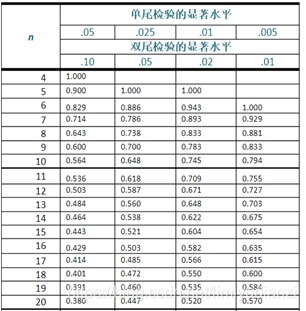
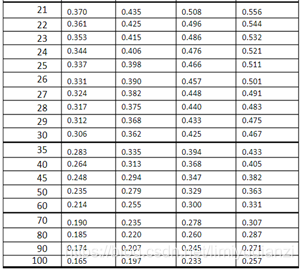
Kendall系数:肯德尔相关性系数,又称肯德尔秩相关系数,应用于 分类变量,适合于定序变量或不满足正态分布假设的等间隔数据
【统计学】区分定类、定序、定距、定比变量!! https://blog.csdn.net/YYIverson/article/details/100068865?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164700775216780255276714%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=164700775216780255276714&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-100068865.pc_search_result_control_group&utm_term=%E5%AE%9A%E5%BA%8F%E5%8F%98%E9%87%8F&spm=1018.2226.3001.4187
https://blog.csdn.net/YYIverson/article/details/100068865?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164700775216780255276714%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=164700775216780255276714&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-100068865.pc_search_result_control_group&utm_term=%E5%AE%9A%E5%BA%8F%E5%8F%98%E9%87%8F&spm=1018.2226.3001.4187
分类变量可以理解成有类别的变量,可以分为
无序的,比如性别(男、女)、血型(A、B、O、AB);
有序的,比如肥胖等级(重度肥胖,中度肥胖、轻度肥胖、不肥胖)。
通常需要求相关性系数的都是有序分类变量。
import pandas as pd
draw = pd.DataFrame()
print('*Pearson\n',draw.corr())
print('*Spearman\n',draw.corr('spearman'))
print('*kendall',draw.corr('kendall'))r值代表相关性强度,取值范围为[-1,1],>0 ,为正相关。<0,为负相关。
| |r| | 相关性 |
| >0.95 | 显著性相关 |
| >=0.8&<0.95 | 高度相关 |
| >=0.5&<0.8 | 中度相关 |
| >=0.3&<0.5 | 低度相关 |
| <=0.3 | 弱相关 |
3、不同类型变量适用检验方式
①均为连续变量
Pearson
简单线性回归——最小二乘法拟合
散点图
②均为有序分类变量
1、可以认为是定距变量,例:测量满意度(从“完全同意”到“完全不同意”5个类别)就是一个定距变量,可以用1-5为各类别赋值,即1 =完全同意、2 =同意、3 =一般、4 =不同意、5 =完全不同意。
Mantel-Haenszel 趋势检验-判断两个有序分类变量之间的线性趋势
2、不可以认为是定距变量,例:军衔的类别(少将、中将、上将、大将等)之间就不是等距的。
Spearman
Kendall
③均为无序分类变量
卡方检验(分析统计学意义)+Cramer`s V检验(关联强度)
卡方检验-chi2_contingency(observed,correction=True,lambda_=None)
返回:chi2卡方值、p值、dof自由程度、expected预期频率
Cramer`s V检验
Fisher精确检验(检验R*C数据之间的相关关系,分析精确分析,更适合分析小样本数据)
④均为二分类变量
1、需要区分自变量和因变量
相对风险(RR值)
比值比(OR值)
2、不需要区分自变量和因变量
卡方检验和Phiφ系数
Fisher精确检验
⑤一个是二分类变量,一个是连续变量
Point-biserial 适用于分析二分类变量和连续变量之间的相关性
⑥一个是二分类变量,一个是有序分类变量
1、需要区分自变量和因变量
有序分类变量是因变量
有序Logistic回归及其对应的OR值判断两类变量的统计学关联
二分类变量是因变量
Cochran-Armitage检验,常用于分析有序分类自变量和二分类因变量之间的线性趋势-要求一个变量是有序分类变量,另一个变量是二分类变量。
Mantel-Haenszel-要求一个变量是有序分类变量,另一个变量可以是二分类变量,也可以是有序多分类变量。
2、不需要区分自变量和因变量
Biserial秩相关,Mann-Whitney U检验也可以输出Biserial秩相关结果
⑦一个是有序分类变量,一个是连续变量
Spearman
步骤三:假设检验
假设检验的基本思想是“小概率事件”原理,其统计推断方法是带有某种概率性质的反证法。小概率思想是指小概率事件在一次试验中基本上不会发生。反证法思想是先提出检验假设,再用适当的统计方法,利用小概率原理,确定假设是否成立。即为了检验一个假设H0是否正确,首先假定该假设H0正确,然后根据样本对假设H0做出接受或拒绝的决策。
相关性的统计结果可能存在偶然情况,所以需要做显著性检验。
显著性表示的是他们之间是否有关系,说明得到的结果不是偶然因素导致的(具有统计学意义)
相关系数表示的是相关程度强弱
在《赤裸裸的统计学》中,把两个假设称为 零假设 和 对立假设,感觉这种好理解点 。
零假设:这两没有相关性、这跟之前没差异……
对立假设:有相关性,有差异

P值
是用来进行显著性检验的,用来检验变量之间是否有差异以及差异是否显著。
P值是根据各种检验所得值查表得是否大于小于0.05、0.01
P值>0.05代表数据之间不存在显著性差异,差别无统计学意义;
P值≤0.05,代表数据之间存在显著性的差异,即有相关性,差别有统计学意义。
在《赤裸裸的统计学》书中,讲概率<5%,则推翻零假设——这两没有相关性,也就是说这相关。

卡方检验
参数检验——样本符合正态分布:
①T检验——单样本T检验、配对样本T检验、独立样本均数T检验
单样本T检验
当样本量<50时,查T分布表。
当样本量>50时
| t<1.96 | 1.96≤t<2.58 | t≥2.58 |
| p>0.05 | 0.05≥P>0.01 | P≤0.01 |
| 差别无统计学意义 | 差别有统计学意义 | 差别有高度统计学意义 |
比较一组数据的平均值和一个数值有无差异,一个数值可以是已知总体均数

配对样本T检验
比较一组数据在处理前后的平均值有无差异

两独立样本均数T检验
比较两组数据平均值有无差异
import numpy as np
from scipy import stats
t, p = stats.ttest_1samp(data,1) #单样本T检验
t, p = stats.ttest_ind(data1,data2) #双侧检验
t, p = stats.ttest_rel(data1,data2) #配对T检验②Z检验
相对于T检验,适用于样本量超过20的,也是比较均值有无差异
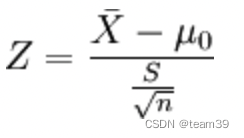
import statsmodels.stats.weightstats as sw
sw.ztest(x)③方差分析ANOVA(F检验)——样本特征大于2
需要数据满足以下两个基本前提:
- 数据独立
- 各观测变量总体要服从正态分布
- 各观测变量的总体满足方差齐——方差齐性检验是用于判断不同组别下的数据波动情况是否一致,即方差齐。若P值呈现出显著性(p <0.05)则说明,不同组别数据波动不一致,即说明方差不齐;反之p值没有呈现出显著性(p>0.05)则说明方差齐。
- 方差分析的结果(p <0.05),则说明处理间存在显著差异,具体哪个处理间存在差异还需要通过多重检验来看。
数据必须满足以上两个条件才能进行方差分析,如不满足,则使用非参数检验。
- 如果X是定类数据,Y是定类数据,则应该使用卡方分析。
- 如果X是定类数据,Y是定量数据,且X组别仅为两组,则应该使用T检验。
按照自变量的数量可以把方差分析分为:
- 单因素方差分析:方差分析中的自变量只有一个定类变量。
- 二因素方差分析:方差分析中的自变量有两个定类变量。
- 三因素方差分析:方差分析中的自变量有三个定类变量。
- 多因素方差分析:方差分析中的自变量有多个定类变量。
f, p = stats.f_oneway(x)④多重检验
邓肯多重检验Tukey HSD test
是指方差分析后对各样本平均数间是否有显著差异的假设检验的统称。
方差分析只能判断各总体平均数间是否有差异,多重比较可用来进一步确定哪两个平均数间有差异,哪两个平均数间没有差异。
from statsmodels.stats.multicomp import pairwise_tukeyhsd
from statsmodels.stats.multicomp import MultiComparison
mc = MultiComparison(data['无序分类变量'], data['连续变量'])
result = mc.tukeyhsd()reject这一列为True,表明各个组间均存在显著差异。
非参数检验
①Mann-Whitney——U检验
两独立样本秩和检验,检验两分布是否相等。
零假设(H0)是两样本同分布,可以对每个样本中的观察进行排序
stats.mannwhitneyu(x, y)②Kruskal-Wallis——H检验
检验两个或多个独立样本的分布是否相等
零假设(H0)是每个样本中的观察是独立同分布的,可以对每个样本中的观察进行排序
stats.kruskal(x, y)③Wilcoxon有符号秩检验
检验两个配对样本的分布是否均等
零假设(H0)是两个样本的中位数相等
R2


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)