机器学习实战之朴素贝叶斯与垃圾邮件分类
文章目录一、实现原理1. 贝叶斯理论与公式2.朴素贝叶斯分类器3.拉普拉斯修正4.分类小案例二、代码实现一、实现原理1. 贝叶斯理论与公式朴素贝叶斯是基于概率的一种推断,先展示公式:其中,P(A)是先验概率,就是在事件B发生之前,我们对A事件概率的一个判断;P(A|B)是后验概率,是在B事件发生之后,我们对A事件概率的重新评估;P(B|A)/P(B)是可能性函数,这是一个调整因子,使得预估概率更接
文章目录
一、实现原理
1.1 贝叶斯理论与公式
朴素贝叶斯是基于概率的一种推断,先展示公式:

其中,P(A)是先验概率,就是在事件B发生之前,我们对A事件概率的一个判断;
P(A|B)是后验概率,是在B事件发生之后,我们对A事件概率的重新评估;
P(B|A)/P(B)是可能性函数,这是一个调整因子,使得预估概率更接近真实概率。
于是条件概率就是:后验概率 = 先验概率 x 调整因子
根据一个样本的多种属性,判断它是正例还是负例,只要计算在这两个情况下的概率就行。即:p(y=1|x), p(y=0|x),比较他们的大小来确定样本类别。

因为要计算两次概率,关于它们的分母,是这个样本的属性在全部样本中的概率。而这两次计算,它们的分母是不变的,所以我们只要计算分子就行。于是有了下面的结论:

即:
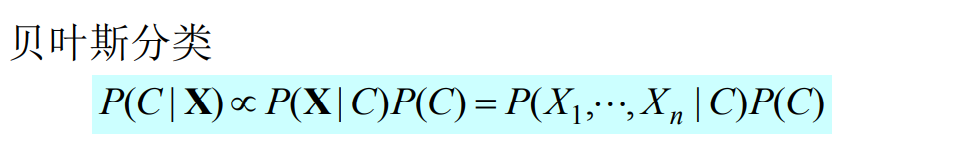
1.2 朴素贝叶斯分类器
朴素贝叶斯分类器的训练器的训练过程就是基于训练集D估计类
先验概率P ( c ),并为每个属性估计条件概率 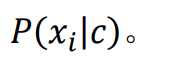

样本的属性分为离散与连续,先给出两个公式:


后面重点还是在于讲述离散属性的朴素贝叶斯分类。
朴素贝叶斯分类器(Naïve Bayes Classifier)采用了“属性条件独立性
假设”,即每个属性独立地对分类结果发生影响。
为方便公式标记,不妨记P(C=c|X=x)为P(c|x)。在假设每个属性都独立的情况下,贝叶斯公式可以修改为:

因为在1.1中,已经说明过,分母是相同的,于是去掉分母,得:

最终我们利用这个公式,在代码中实现概率的计算来对样本进行分类。
1.3 拉普拉斯修正
在用朴素贝叶斯分类判断文本类别的时候,要计算多个概率的乘积。如果样本中的某些单词不在词汇表中出现,则连乘后概率为0,无法进行判断。因此我们在计算概率的时要用拉普拉斯修正,公式如下:

1.4 分类小案例
在写代码前,先用一个小案例,通过贝叶斯分类器来判断文档类别。
我们已知训练集如下,每条文本都已经打上标签

经过处理,变成下面这样(顺带说一下,这里用到的是词袋模型,还有一种词集模型将在代码实现中细说):

问题:I love song是哪种类别?


省略单词 I

最终得到结果

二、代码实现
2.1 数据准备与处理
分别有25条被标记上ham与spam的邮件如下:

共50条邮件。将随机选择40条做训练,剩下10条用于测试。
在这些邮件中,要将符号去除,并且把单词一个个分割开,变成字符串列表
def textParse(bigString): # 将字符串转换为字符列表
# * 会匹配0个或多个规则,split会将字符串分割成单个字符【python3.5+】; 这里使用\W 或者\W+ 都可以将字符数字串分割开,产生的空字符将会在后面的列表推导式中过滤掉
listOfTokens = re.split(r'\W+', bigString) # 将特殊符号作为切分标志进行字符串切分,即非字母、非数字
return [tok.lower() for tok in listOfTokens if len(tok) > 2] # 除了单个字母,例如大写的I,其它单词变成小写
效果如下:

2.2 创建词汇表
将ham与spam里的单词全部拿出,创建一个不重复的词汇表,将来计算单词概率就是以这个词汇表为基准
def createVocabList(dataSet):
vocabSet = set([]) # 创建一个空的不重复列表
for document in dataSet:
vocabSet = vocabSet | set(document) # 取并集
return list(vocabSet)
这样就得到了一个字符串列表

2.3 构建词袋/词集模型
词袋模型和词集模型的区别在于,在统计一个文本里单词是否出现在词汇表里时,前者是统计个数,后者则是出现置1。而接下来用的方法是利用词袋模型计算。
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0] * len(vocabList) # 创建一个其中所含元素都为0的向量
# print(inputSet)
# print(inputSet)
for word in inputSet: # 遍历每个词条
if word in vocabList: # 如果词条存在于词汇表中,则计数加一
returnVec[vocabList.index(word)] += 1
return returnVec # 返回词袋模型
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList) # 创建一个其中所含元素都为0的向量
for word in inputSet: # 遍历每个词条
if word in vocabList: # 如果词条存在于词汇表中,则置1
returnVec[vocabList.index(word)] = 1
else:
print("the word: %s is not in my Vocabulary!" % word)
return returnVec # 返回文档向量
每一个训练集样本的文档向量都是长度为词汇表长度的列表,里面包含的是该邮件单词出现在词汇表的次数。

2.4 朴素贝叶斯分类器实现及结果
首先要做的是拉普拉斯平滑。在这里令分母等于2,分子为1。然后遍历训练集,统计侮辱类与非侮辱类的分子。

这是侮辱类的分子,长度是词汇表长度。它的含义是:在训练集中,这些单词在对应的词汇表里出现的次数。
因此可以根据这个算概率:如,在侮辱类的情况下,每个单词在总侮辱类样本的单词数的比例。得到不取对数得结果:

可以看到数字太小。取对数的目的是防止下溢出。取完对数结果如下:

贴上代码
def trainNB0(trainMatrix, trainCategory):
numTrainDocs = len(trainMatrix) # 计算训练的文档数目
# trainCategory 文本类别
# print(numTrainDocs)
# print(trainCategory)
numWords = len(trainMatrix[0]) # 计算每篇文档的词条数
pAbusive = sum(trainCategory) / float(numTrainDocs) # 文档属于侮辱类的概率
# print((pAbusive))
p0Num = np.ones(numWords)
p1Num = np.ones(numWords) # 创建numpy.ones数组,词条出现数初始化为1,拉普拉斯平滑
p0Denom = 2.0
p1Denom = 2.0 # 分母初始化为2,拉普拉斯平滑
for i in range(numTrainDocs):
if trainCategory[i] == 1: # 统计属于侮辱类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)···
p1Num += trainMatrix[i]
# print(trainMatrix[i])
# print(i, sum(trainMatrix[i]), p1Denom)
p1Denom += sum(trainMatrix[i])
# print(i, p1Denom)
else: # 统计属于非侮辱类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)···
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
# print(p1Num / p1Denom)
# 分母:一共有多少词
# 分子:是个数组,表示每个索引下对应的词出现次数
# np.log 默认以e为底
# print(p1Num)
# print(p1Denom, p0Denom)
# print(p1Num)
# print('不取对数:\n', p1Num / p1Denom)
# p1Num / p1Denom 就是每个单词在总单词出现数中的概率
p1Vect = np.log(p1Num / p1Denom) # 取对数,防止下溢出(数字太小导致)
p0Vect = np.log(p0Num / p0Denom)
# print(p1Vect == np.log(p1Num / p1Denom))
# print("侮辱类:", p0Vect)
# print("非侮辱类:", p1Vect)
# print("文档属于侮辱类的概率:", pAbusive)
return p0Vect, p1Vect, pAbusive # 返回属于侮辱类的条件概率数组,属于非侮辱类的条件概率数组,文档属于侮辱类的概率
然后根据得到的数据计算两种情况下的概率,比较大小,实现分类。
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
# print(p1Vec)
# print(vec2Classify * p1Vec)
# print(len(vec2Classify))
# print(pClass1)
# print('class:')
# print(np.log((pClass1)))
# vec2Classify * p1Vec 表示待判断的文本在这个概率下的数组,其中vec2Classify是0,1组成的,结果就是0,或是对应的p1Vec的值
# print(vec2Classify)
# print(p1Vec)
# print(vec2Classify * p1Vec)
# print(sum(vec2Classify * p1Vec)) 统计这个数组里所有值
# p1Vect = np.log(p1Num / p1Denom)已经取过一次对数,这里的sum(vec2Classify * p1Vec)就表示是对数
p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) # 对应元素相乘。logA * B = logA + logB,所以这里加上log(pClass1)
p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)
# print(p1)
# print(p0)
# print('----------------------------------------------------------------------------------------------------------')
if p1 > p0:
return 1
else:
return 0
多次运行,得到以下结果:



错误率并不算高。
三、总结
这次实验相比于逻辑斯蒂回归在数学上没那么难,代码实现也挺容易。但是对于连续型的变量在该实例里并没有体现,要深入研究的话在课后还是要多花时间的。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)