Python中的strip().split(‘\t‘)的用法和解释
目录(一)、strip()的用法(二)、split的用法(三)、strip().split()的用法(一)、strip()的用法strip()主要是对字符串进行操作,主要是删除当前你得到的这个字符串的首尾字符,如果在strip()这个括号里面你没有指定字符,也就是如果括号里面为空的话,那么会默认删除当前字符串的首尾的空格和换行符。示例如下:1、删除前面的空格2、删除首尾的空格和换行3、删除首尾指定
目录
(一)、strip()的用法
strip()主要是对字符串进行操作,主要是删除当前你得到的这个字符串的首尾字符,如果在strip()这个括号里面你没有指定字符,也就是如果括号里面为空的话,那么会默认删除当前字符串的首尾的空格和换行符。
示例如下:
1、删除前面的空格
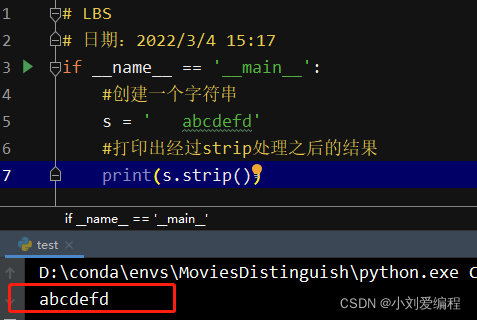
2、删除首尾的空格和换行
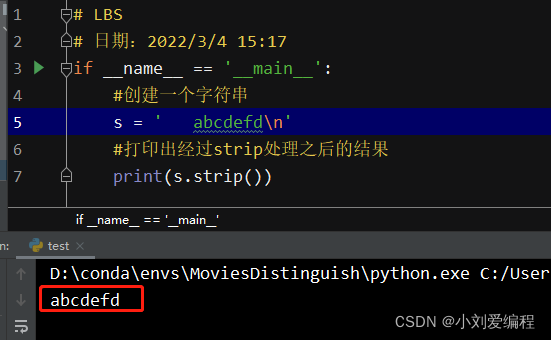
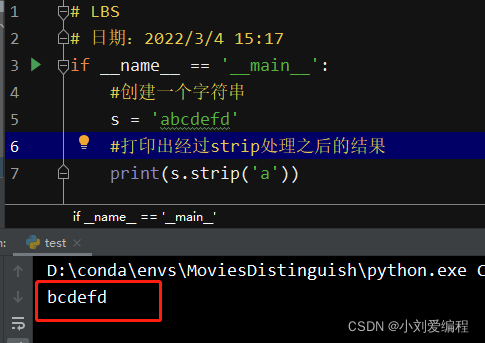
3、删除首尾指定的字符
(二)、split的用法
split函数通常是对字符串进行操作,操作完之后的结果,变成了一个字符串列表。split函数按照括号内给定的字符进行分割,如果括号内是空的,也就是没有指定具体的分割内容的话,那么就默认的按照空格进行分割。
split()的具体用法如下:
1、按照默认的方式进行划分(默认是按照空格进行分割)

2、按照指定的某一个字符进行分割,分割之后返回字符串列表,字符串列表中不包括你指定的分隔符,例如下面这个例子中,不包含d这个字母

3、也可以是按照‘\n’,'\t'进行划分

(三)、strip().split()的用法
经过前面两个的演示,我们应该能大致明白这个联合用法通常用在文件的读取划分上。即按照一定的格式进行读取之后,进行划分,在进行首尾多余字符的删除。我们来看一个例子。
假定给你一个文档(.txt格式),内容如下,九行数据,每一行之间有若干个空格。
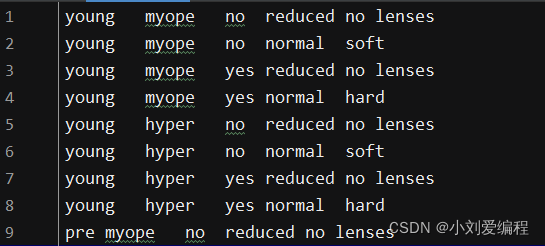
我们先打开这个文档然后进行读取,之后再调用这个联合函数,我们看一下效果。
1、首先我们先按行读取一下文件,代码如下。
if __name__ == '__main__':
fr = open('lenses.txt') #文件名为:lenses.txt
fp = fr.readlines() #按行读取
print(fp)
#fp打印的结果格式如下:我展示的只是前三行的数据
#['young\tmyope\tno\treduced\tno lenses\n', 'young\tmyope\tno\tnormal\tsoft\n', 'young\tmyope\tyes\treduced\tno lenses\n']
2、观察文件按行读取之后的结果,我们看到每一行被读取之后都是一个字符串,这个字符串里面包含空格符‘\t’还有换行符'\n',所以我们这一步的目标是要把空格符‘\t’给去掉,调用split()函数。
代码如下:
# LBS
# 日期:2022/3/4 11:01
from sklearn import tree
if __name__ == '__main__':
fr = open('lenses.txt')
fp = fr.readlines()
print(fp[0].split('\t'))
#打印出第一行经过处理的结果为:['young', 'myope', 'no', 'reduced', 'no lenses\n']
3、我们看到经过split处理之后,在第一行的末尾处还有一个换行符'\n',我们刚才所说的strip()的作用就是能够删除字符串前后的空格和换行符。
代码如下:
# LBS
# 日期:2022/3/4 11:01
from sklearn import tree
if __name__ == '__main__':
fr = open('lenses.txt')
fp = fr.readlines()
print(fp[0].strip().split('\t'))
#打印出第一行经过处理的结果为:['young', 'myope', 'no', 'reduced', 'no lenses']
这时我们看到第一行的数据经过联合函数strip().split()处理后,删除了空格和换行符,用起来还是比较方便的。如果有多行数据一起处理的话,那就需要用到for循环
比如:
fp.strip().split('\t') for fp in fr.readlines()
如有更好的理解,欢迎留言进行交流,相互学习。
如果转载。请声明出处,整理不易,点个赞吧。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 97
97 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容
 免费领云主机
免费领云主机



 华为云 x DeepSeek:AI驱动云上应用创新
华为云 x DeepSeek:AI驱动云上应用创新

 DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
 华为云数字人,助力行业数字化业务创新
华为云数字人,助力行业数字化业务创新
 企业数据治理一站式解决方案及应用实践
企业数据治理一站式解决方案及应用实践
 轻松构建AIoT智能场景应用
轻松构建AIoT智能场景应用


所有评论(0)