Matplotlib之散点图绘制
文章目录1. 散点图简介2. 散点图的应用场景:3. 绘制散点图4. 回归分析1. 散点图简介散点图也叫 X-Y 图,它将所有的数据以点的形式展现在直角坐标系上,以显示变量之间的相互影响程度,点的位置由变量的数值决定。通过观察散点图上数据点的分布情况,我们可以推断出变量间的相关性。如果变量之间不存在相互关系,那么在散点图上就会表现为随机分布的离散的点,如果存在某种相关性,那么大部分的数据点就会相对
1. 散点图简介
散点图也叫 X-Y 图,它将所有的数据以点的形式展现在直角坐标系上,以显示变量之间的相互影响程度,点的位置由变量的数值决定。
通过观察散点图上数据点的分布情况,我们可以推断出变量间的相关性。如果变量之间不存在相互
关系,那么在散点图上就会表现为随机分布的离散的点,如果存在某种相关性,那么大部分的数据
点就会相对密集并以某种趋势呈现。
数据的相关关系主要分为:正相关(两个变量值同时增长)、负相关(一个变量值增加另一个变量值下降)、不相关、线性相关、指数相关等,表现在散点图上的大致分布如下图所示。那些离点集群较远的点我们称为离群点或者异常点。

2. 散点图的应用场景:
- 观察数据集的分布情况。
- 通过分析规律,根据样本数据特征计算出回归方程。
3. 绘制散点图
散点图的绘制,使用的是 plt.scatter 方法,这个方法有以下参数:
- x,y :分别是x轴和y轴的数据集。两者的数据长度必须一致。
- s :点的尺寸。如果是一个具体的数字,那么散点图的所有点都是一样大小,如果是一个序
列,那么这个序列的长度应该和x轴数据量一致,序列中的每个元素代表每个点的尺寸。 - c :点的颜色。可以为具体的颜色,也可以为一个序列或者是一个 cmap 对象。
- marker :标记点,默认是圆点,也可以换成其他的。
- 其他参数参考:matplotlib.pyplot.scatter官方文档。
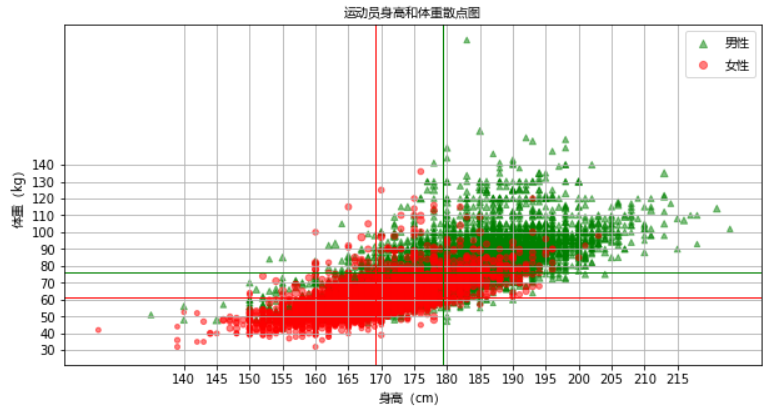
比如我们有一组两万条左右得运动员身高和体重以及年龄的数据表格 new_athlete.csv :


那么可以通过以下代码来绘制散点图:
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import font_manager
font = font_manager.FontProperties(fname="C:\Windows\Fonts\msyh.ttc")
athletes = pd.read_csv('new_athlete.csv').dropna()
athletes.head()
male_athletes = athletes[athletes['Sex'] == 'M']
female_athletes = athletes[athletes['Sex'] == 'F']
male_mean_height = male_athletes['Height'].mean()
female_mean_height = female_athletes['Height'].mean()
male_mean_weight = male_athletes['Weight'].mean()
female_mean_weight = female_athletes['Weight'].mean()
plt.figure(figsize=(10,5))
plt.scatter(male_athletes['Height'],male_athletes['Weight'],s=male_athletes['Age'],marker='^',color='g',label='男性',alpha=0.5)
plt.scatter(female_athletes['Height'],female_athletes['Weight'],color='r',alpha=0.5,s=female_athletes['Age'],label='女性')
plt.axvline(male_mean_height,color="g",linewidth=1)
plt.axhline(male_mean_weight,color="g",linewidth=1)
plt.axvline(female_mean_height,color="r",linewidth=1)
plt.axhline(female_mean_weight,color="r",linewidth=1)
plt.xticks(np.arange(140,220,5))
plt.yticks(np.arange(30,150,10))
plt.legend(prop=font)
plt.xlabel("身高(cm)",fontproperties=font)
plt.ylabel("体重(kg)",fontproperties=font)
plt.title("运动员身高和体重散点图",fontproperties=font)
plt.grid()
plt.show()

4. 回归分析
有一组数据后,我们可以对这组数据进行回归分析,回归分析可以帮助我们了解这组数据的大体走
向。
回归分析按照涉及的变量的多少,分为一元回归和多元回归分析;
按照自变量的多少,可分为简单回归分析和多重回归分析;
按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。
如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。
如果回归分析中包括两个或两个以上的自变量,且自变量之间存在线性相关,则称为多重线性回归分析。

通过以上运动员散点图的分析,我们总体上可以看出来是满足线性回归的,因此可以在图上绘制一个线性回归的线条。想要绘制线性回归的线条,需要先按照之前的数据计算出线性方程,假如 x 是自变量, y 是因变量,那么线性回归的方程可以用以下几个来表示:
y = 截距+斜率*x+误差
只要把这个方程计算出来了,那么后续我们就可以根据 x 的值,大概的估计出 y 的取值范围,也就是预测。
如果我们针对以上运动员的身高和体重的关系,只要有身高,那么就可以大概的估计出体重的值。
回归方程的绘制我们需要借助 scikit-learn 库,这个库是专门做机器学习用的,我们需要使用里面的线性回归类 sklearn.liear_regression.LinearRegression 。示例代码如下:
# from sklearn.linear_model import LinearRegression
# male_athletes = athletes[athletes['Sex'] == 'M'].dropna()
# female_athletes = athletes[athletes['Sex'] == 'F'].dropna()
# xtrain = male_athletes['Height']
# ytrain = male_athletes['Weight']
# # 生成线性回归对象
# model = LinearRegression()
# # 喂训练数据进去,但是需要把因变量转换成1列多行的数据
# model.fit(xtrain[:,np.newaxis],ytrain)
# # 打印斜率
# print(model.coef_)
# # 打印截距
# print(model.intercept_)
# line_xticks = xtrain
# # 根据回归方程计算出的y轴坐标
# line_yticks = model.predict(xtrain[:,np.newaxis])
plt.figure(figsize=(15,5))
male_athletes = athletes[athletes['Sex'] == 'M']
male_heights = male_athletes['Height']
male_weights = male_athletes['Weight']
male_height_mean = male_heights.mean()
male_weight_mean = male_weights.mean()
female_athletes = athletes[athletes['Sex'] == 'F']
female_heights = female_athletes['Height']
female_weights = female_athletes['Weight']
female_height_mean = female_heights.mean()
female_weight_mean = female_weights.mean()
plt.scatter(male_heights,male_weights,s=male_athletes['Age'],marker='^')
plt.scatter(female_heights,female_weights,s=female_athletes['Age'],alpha=0.5)
plt.axvline(male_height_mean,linewidth=1,c='r')
plt.axhline(male_weight_mean,linewidth=1,c='y')
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(male_heights.values[:,np.newaxis],male_weights)
predict_male_weight = model.predict(male_heights.values[:,np.newaxis])
plt.plot(male_heights,predict_male_weight)

为便于学习交流草创了一个q群: Python炼丹大师交流群
后端 爬虫 数据分析 机器学习等和python相关的都可以在此畅所欲言
编程资源:编程学习资源传送门
文章到此结束,但愿本文能对你有一点点帮助,欢迎三连,点个赞,收个藏啥的,有问题的尽管砸来,我有故事你有酒,好好交流不分手!下次见!

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)