python中jieba库使用教程
jieba是python的一个中文分词库,下面介绍它的使用方法。安装方式1:pip install jieba方式2:先下载 http://pypi.python.org/pypi/jieba/然后解压,运行 python setup.py install功能下面介绍下jieba的主要功能,具体信息可参考github文档:https://github.com/fxsjy/jieba分词jieba常
jieba是python的一个中文分词库,下面介绍它的使用方法。
安装
方式1:
pip install jieba
方式2:
先下载 http://pypi.python.org/pypi/jieba/
然后解压,运行 python setup.py install功能
下面介绍下jieba的主要功能,具体信息可参考github文档:https://github.com/fxsjy/jieba
分词
jieba常用的三种模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
可使用 jieba.cut 和 jieba.cut_for_search 方法进行分词,两者所返回的结构都是一个可迭代的 generator,可使用 for 循环来获得分词后得到的每一个词语(unicode),或者直接使用 jieba.lcut 以及 jieba.lcut_for_search 返回 list。
jieba.Tokenizer(dictionary=DEFAULT_DICT) :使用该方法可以自定义分词器,可以同时使用不同的词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
jieba.cut 和 jieba.lcut 可接受的参数如下:
- 需要分词的字符串(unicode 或 UTF-8 字符串、GBK 字符串)
- cut_all:是否使用全模式,默认值为
False - HMM:用来控制是否使用 HMM 模型,默认值为
True
jieba.cut_for_search 和 jieba.lcut_for_search 接受 2 个参数:
- 需要分词的字符串(unicode 或 UTF-8 字符串、GBK 字符串)
- HMM:用来控制是否使用 HMM 模型,默认值为
True
需要注意的是,尽量不要使用 GBK 字符串,可能无法预料地错误解码成 UTF-8。
三种分词模式的比较:
# 全匹配
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=True)
print(list(seg_list)) # ['今天', '哪里', '都', '没去', '', '', '在家', '家里', '睡', '了', '一天']
# 精确匹配 默认模式
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=False)
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']
# 精确匹配
seg_list = jieba.cut_for_search("今天哪里都没去,在家里睡了一天")
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']自定义词典
开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。
用法: jieba.load_userdict(dict_path)
dict_path:为自定义词典文件的路径
词典格式如下:
一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。
下面使用一个例子说明一下:
自定义字典 user_dict.txt:
大学课程
深度学习下面比较下精确匹配、全匹配和使用自定义词典的区别:
import jieba
test_sent = """
数学是一门基础性的大学课程,深度学习是基于数学的,尤其是线性代数课程
"""
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学', '课程', ',', '深度',
# '学习', '是', '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n']
words = jieba.cut(test_sent, cut_all=True)
print(list(words))
# ['\n', '数学', '是', '一门', '基础', '基础性', '的', '大学', '课程', '', '', '深度',
# '学习', '是', '基于', '数学', '的', '', '', '尤其', '是', '线性', '线性代数', '代数', '课程', '\n']
jieba.load_userdict("userdict.txt")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是',
# '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n']
jieba.add_word("尤其是")
jieba.add_word("线性代数课程")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是',
# '基于', '数学', '的', ',', '尤其是', '线性代数课程', '\n']从上面的例子中可以看出,使用自定义词典与使用默认词典的区别。
jieba.add_word():向自定义字典中添加词语
关键词提取
可以基于 TF-IDF 算法进行关键词提取,也可以基于TextRank 算法。 TF-IDF 算法与 elasticsearch 中使用的算法是一样的。
使用 jieba.analyse.extract_tags() 函数进行关键词提取,其参数如下:
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本
- topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight 为是否一并返回关键词权重值,默认值为 False
- allowPOS 仅包括指定词性的词,默认值为空,即不筛选
- jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
也可以使用 jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件。
基于 TF-IDF 算法和TextRank算法的关键词抽取:
import jieba.analyse
file = "sanguo.txt"
topK = 12
content = open(file, 'rb').read()
# 使用tf-idf算法提取关键词
tags = jieba.analyse.extract_tags(content, topK=topK)
print(tags)
# ['玄德', '程远志', '张角', '云长', '张飞', '黄巾', '封谞', '刘焉', '邓茂', '邹靖', '姓名', '招军']
# 使用textrank算法提取关键词
tags2 = jieba.analyse.textrank(content, topK=topK)
# withWeight=True:将权重值一起返回
tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=True)
print(tags)
# [('玄德', 0.1038549799467099), ('程远志', 0.07787459004363208), ('张角', 0.0722532891360849),
# ('云长', 0.07048801593691037), ('张飞', 0.060972692853113214), ('黄巾', 0.058227157790330185),
# ('封谞', 0.0563904127495283), ('刘焉', 0.05470798376886792), ('邓茂', 0.04917692565566038),
# ('邹靖', 0.04427258239705188), ('姓名', 0.04219704283997642), ('招军', 0.04182041076757075)]上面的代码是读取文件,提取出现频率最高的前12个词。
词性标注
词性标注主要是标记文本分词后每个词的词性,使用例子如下:
import jieba
import jieba.posseg as pseg
# 默认模式
seg_list = pseg.cut("今天哪里都没去,在家里睡了一天")
for word, flag in seg_list:
print(word + " " + flag)
"""
使用 jieba 默认模式的输出结果是:
我 r
Prefix dict has been built successfully.
今天 t
吃 v
早饭 n
了 ul
"""
# paddle 模式
words = pseg.cut("我今天吃早饭了",use_paddle=True)
"""
使用 paddle 模式的输出结果是:
我 r
今天 TIME
吃 v
早饭 n
了 xc
"""paddle模式的词性对照表如下:
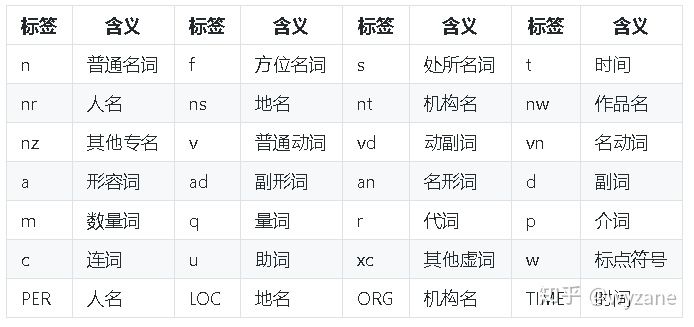

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)