【机器学习项目实战】随机森林(random forest)回归(RandomForestRegressor)模型Python实现
说明:这是一个机器学习实战项目(附带数据+代码),如需数据+完整代码可以直接到文章最后获取。1.定义问题在电子商务领域,现在越来越多的基于历史采购数据、订单数据等,进行销量的预测;本模型也是基于电商的一些历史数据进行销量的建模、预测。2.获取数据本数据是模拟数据,分为两部分数据:训练数据集:data_train.xlsx测试数据集:data_test.xlsx在实际应用中,根据自己的数据进行替换即
说明:这是一个机器学习实战项目(附带数据+代码),如需数据+完整代码可以直接到文章最后获取。
1.定义问题
在电子商务领域,现在越来越多的基于历史采购数据、订单数据等,进行销量的预测;本模型也是基于电商的一些历史数据进行销量的建模、预测。
2.获取数据
本数据是模拟数据,分为两部分数据:
训练数据集:data_train.xlsx
测试数据集:data_test.xlsx
在实际应用中,根据自己的数据进行替换即可。
特征数据:x1、x2、x3、x4、x5、x6、x7、x8、x9、x10
标签数据:y
3.数据预处理
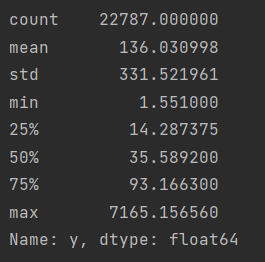
1)数据描述性分析:
data_train.describe()
2)数据完整性、数据类型查看:
data_train.info()
3)数据缺失值个数:
4)缺失值数据比例:
5)缺失值填充:这里通过业务上分析:填充0比较合适:
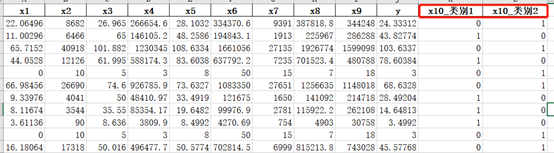
6)哑变量处理
data_train.loc[data_train['x10'] == '类别1', 'x10'] = 1 data_train.loc[data_train['x10'] == '类别2', 'x10'] = 2 a = pd.get_dummies(data_train['x10'], prefix="x10") frames = [data_train, a] data_train = pd.concat(frames, axis=1)特征变量中x10的数值为文本类型:类型1、类型2,不符合机器学习数据要求,需要进行哑特征处理,变为0 1数值。
处理后,数据如下:
4.探索性数据分析
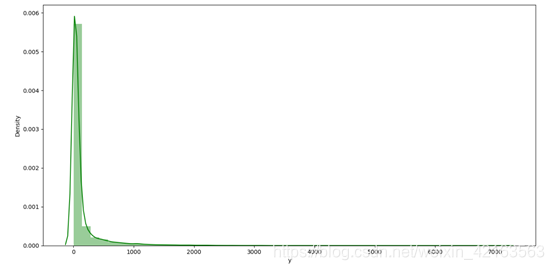
1)目标数据销量分析:
print(data_train['y'].describe())
2)特征变量x1和标签变量y关系的散点图:
var = 'x1' data = pd.concat([data_train['y'], data_train[var]], axis=1) data.plot.scatter(x=var, y='y')
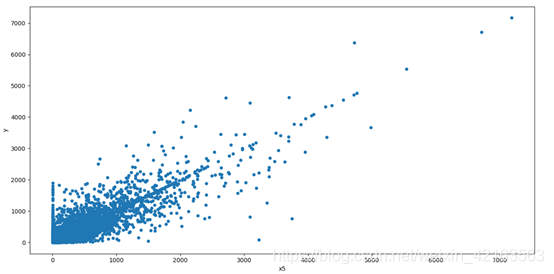
3)特征变量x5和标签变量y关系的散点图:
var0 = 'x5' data0 = pd.concat([data_train['y'], data_train[var0]], axis=1) data0.plot.scatter(x=var0, y='y')
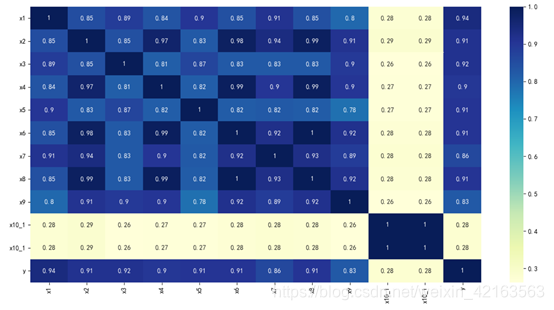
4)相关性分析
5.特征工程
1)特征数据和标签数据拆分,y为标签数据,除y之外的为特征数据;
2)训练集拆分,分为训练集和验证集,80%训练集和20%验证集;
特征工程还有很多其他内容,例如数据标准化、降维等等,这个根据实际情况来,本次建模不需要。
6.机器建模
1)建立随机森林回归模型,模型参数如下:
编号
参数
1
n_estimators=100
2
random_state=1
3
n_jobs=-1
其它参数根据具体数据,具体设置。
forest = RandomForestRegressor( n_estimators=100, random_state=1, n_jobs=-1) forest.fit(X_train, Y_train)2)验证集结果输出与比对:一方面是生成excel表格数据;一方面是生成折线图。
plt.figure() plt.plot(np.arange(1000), Y_validation[:1000], "go-", label="True value") plt.plot(np.arange(1000), y_validation_pred[:1000], "ro-", label="Predict value") plt.title("True value And Predict value") plt.legend()
3)生成决策树
with open('./wine.dot','w',encoding='utf-8') as f: f=export_graphviz(pipe.named_steps['regressor'].estimators_[0], out_file=f)由于树比较多 一下子全部转为图片 导致图片看不清晰,所以生成的格式为.dot格式,大家可以根据具体需要把dot转为图片。
不分展示:总共200多页。
7.模型评估
1)评估指标主要采用准确率分值、MAE、MSE、RMSE
score = forest.score(X_validation, Y_validation) print('随机森林模型得分: ', score) print('Mean Absolute Error:', metrics.mean_absolute_error(Y_validation, y_validation_pred)) print('Mean Squared Error:', metrics.mean_squared_error(Y_validation, y_validation_pred)) print('Root Mean Squared Error:', np.sqrt(metrics.mean_squared_error(Y_validation, y_validation_pred)))
编号
评估指标名称
评估指标值
1
准确率分值
0.9769
2
MAE
9.9431
3
MSE
2625.5679
4
RMSE
51.2402
通过上述表格可以看出,此随机森林模型效果良好。
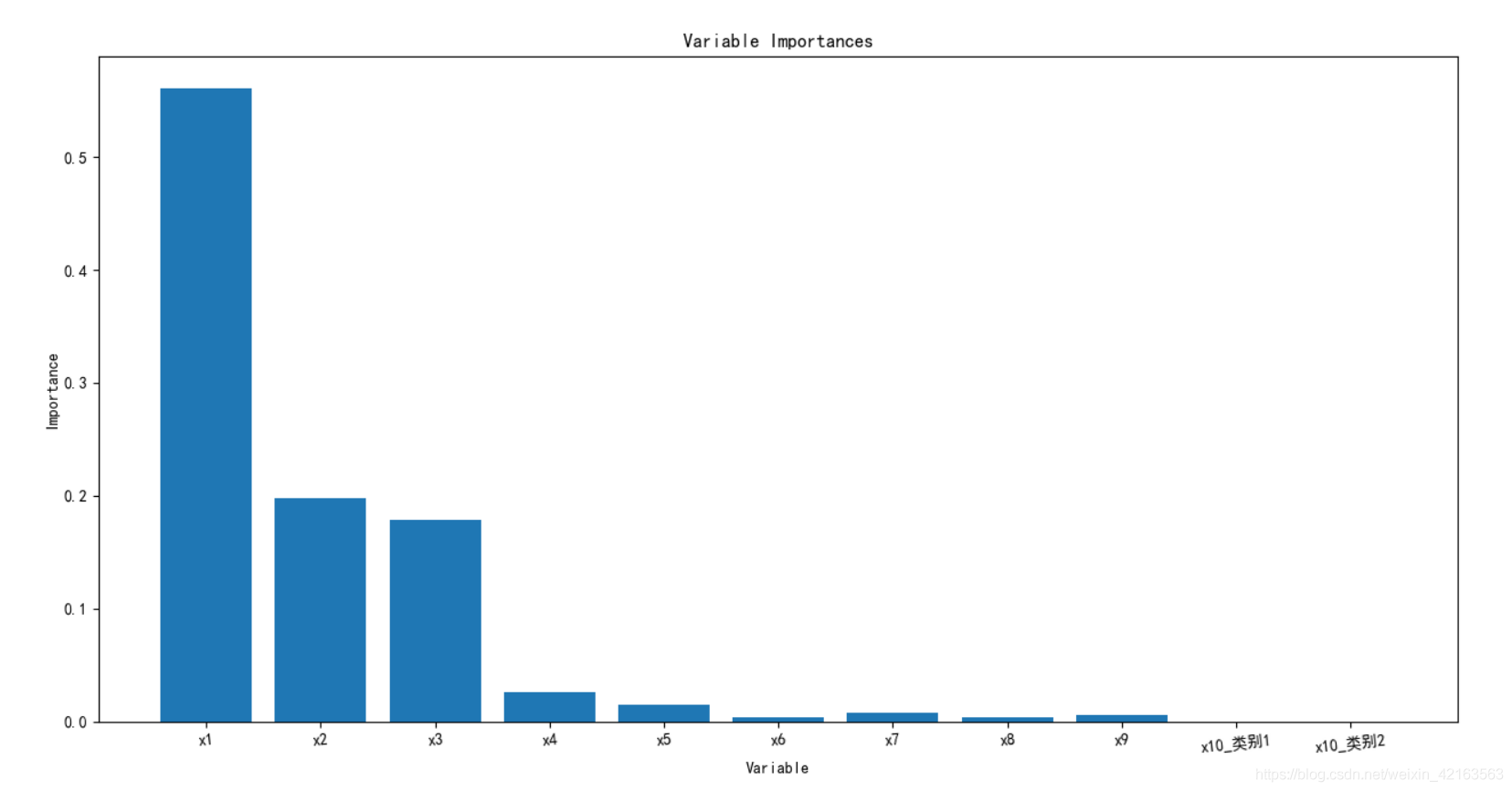
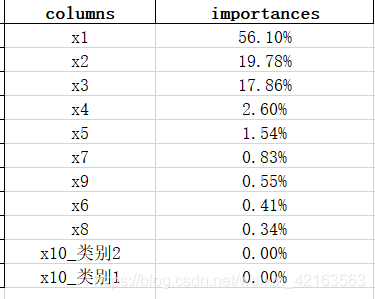
2)模型特征重要性:一方面是输出到excel;一方面是生成柱状图。
col = list(X_train.columns.values) importances = forest.feature_importances_ x_columns = ['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x9', 'x10_类别1', 'x10_类别2'] # print("重要性:", importances) # 返回数组从大到小的索引值 indices = np.argsort(importances)[::-1] list01 = [] list02 = [] for f in range(X_train.shape[1]): # 对于最后需要逆序排序,我认为是做了类似决策树回溯的取值,从叶子收敛 # 到根,根部重要程度高于叶子。 print("%2d) %-*s %f" % (f + 1, 30, col[indices[f]], importances[indices[f]])) list01.append(col[indices[f]]) list02.append(importances[indices[f]]) from pandas.core.frame import DataFrame c = {"columns": list01, "importances": list02} data_impts = DataFrame(c) data_impts.to_excel('data_importances.xlsx') importances = list(forest.feature_importances_) feature_list = list(X_train.columns) feature_importances = [(feature, round(importance, 2)) for feature, importance in zip(feature_list, importances)] feature_importances = sorted(feature_importances, key=lambda x: x[1], reverse=True) import matplotlib.pyplot as plt x_values = list(range(len(importances))) print(x_values) plt.bar(x_values, importances, orientation='vertical') plt.xticks(x_values, feature_list, rotation=6) plt.ylabel('Importance') plt.xlabel('Variable') plt.title('Variable Importances')
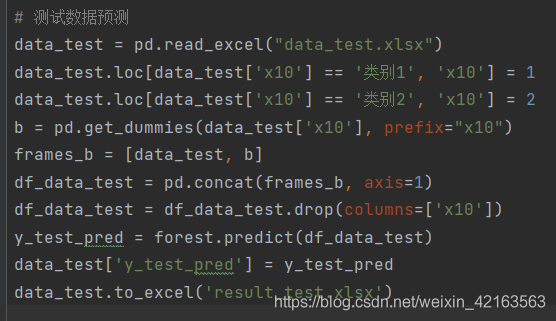
8.实际应用
根据最近一周的特征数据,来预测销量(这里的数据,是提前准备好的没有标签的数据)。预测结果如下;
可以根据预测的销量进行备货。




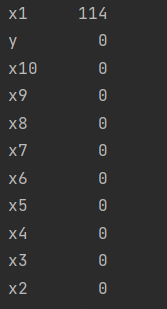
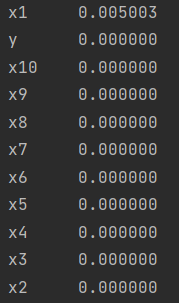






# 数据缺失值个数 total = data_train.isnull().sum().sort_values(ascending=False) # 缺失值数据比例 percent = (data_train.isnull().sum() / data_train.isnull().count()).sort_values(ascending=False) print(total) print(percent) # 本次机器学习项目实战所需的资料,项目资源如下: 链接:https://pan.baidu.com/s/1_u0XJKK1RTYLJf82WugmAA 提取码:bx3h # 缺失值填充 data_train['x1'] = data_train['x1'].fillna(0) print(data_train.isnull().sum().max()) # 哑变量处理 data_train.loc[data_train['x10'] == '类别1', 'x10'] = 1 data_train.loc[data_train['x10'] == '类别2', 'x10'] = 2 a = pd.get_dummies(data_train['x10'], prefix="x10") frames = [data_train, a] data_train = pd.concat(frames, axis=1) data_train = data_train.drop(columns=['x10']) data_train.to_excel('data_train_yucl.xlsx')

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 59
59 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)