python pandas 把数据保存成csv文件,以及读取csv文件获取指定行、指定列数据
文章目录:1 数据说明2 把数据集文件信息使用python pandas保存成csv文件3 使用python pandas 读取csv的每行、每列数据1 数据说明1、在test_data目录下是我们的数据集(我虚构的,只是为了说明下面的处理过程)图片来源这里,不要问,没有联系方式!每张图片名中的数字是样本数据的标签label这里我们的数据规模大小是5张数据2、数据保存成csv文件要求每一行代表一个
·
1 数据说明
1、在test_data目录下是我们的数据集(我虚构的,只是为了说明下面的处理过程)
图片来源这里,不要问,没有联系方式!
- 每张图片名中的数字是样本
数据的标签label - 这里我们的数据规模大小是5张数据
2、数据保存成csv文件要求
- 每一行代表一个样本
- 每一行的第一列表示文件的路径,每一行的第二列表示样本的标签
2 把数据集文件信息使用python pandas保存成csv文件
1、根据上面保存成csv文件的要求,把数据集相关信息保存到csv文件中:
# coding=utf-8
"""
Copyright (c) 2018-2022. All Rights Reserved.
@author: shliang
@email: shliang0603@gmail.com
创建和导入csv文件
"""
import pandas as pd
import glob
import os
import numpy as np
# 创建csv文件
def create_csv_file():
'''
把test_data目录下的文件绝对路径保存到csv文件中,同时把文件名中的label也保存下来
保存两列 filename, label
:return:
'''
img_paths_list = glob.glob("../test_data/*.png")
labes_list = []
img_label_list = []
for path in img_paths_list:
img_name = os.path.split(path)[-1]
prefix = os.path.splitext(img_name)[0]
label = prefix.split('_')[-1]
labes_list.append(str(label))
# abspath = os.path.abspath(path)
img_label_list.append([path, label])
# 通过zip函数组合每一个样本的path和label: (path, label)
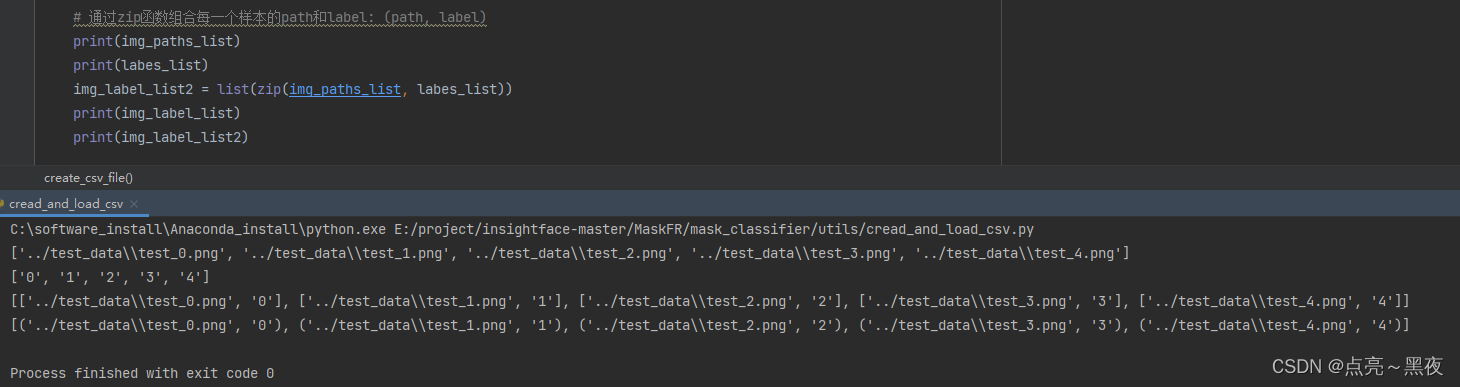
print(img_paths_list)
print(labes_list)
img_label_list2 = list(zip(img_paths_list, labes_list))
print(img_label_list)
print(img_label_list2)
# 保存数据data格式,嵌套列表,每个子列表中表示每一行数据
# df = pd.DataFrame(data=np.array([[img0, label0],[img1, label1],...,[img4, label4]]),
# columns=['filepath', 'label'])
df1 = pd.DataFrame(data=img_label_list,
columns=['filepath', 'label'])
df1.to_csv('../test_data/filename1.csv')
df1.to_csv('../test_data/filename2.csv', index=False)
# 保存数据data格式,列表中嵌套元组,每个元组中表示每一行数据
df3 = pd.DataFrame(data=img_label_list2,
columns=['filepath', 'label'])
df3.to_csv('../test_data/filename3.csv')
# 保存数据data格式,字典格式,key表示列名,value是列表,表示每一列数据
df4 = pd.DataFrame({"filename": img_paths_list, "label": labes_list})
df4.to_csv('../test_data/filename4.csv')
if __name__ == '__main__':
create_csv_file()
输出结果:
2、pd.DataFrame(data, columns)的参数
data参数:是输入要保存的数据
该参数的值有几种输入格式,都是可以的:
- 1)
numpy格式:data=np.array([[img0, label0],[img1, label1],...,[img4, label4]] - 2)
列表嵌套列表格式:保存数据data格式,嵌套列表,每个子列表中表示每一行数据:data=[[img0, label0],[img1, label1],...,[img4, label4]] - 3)
列表嵌套元组格式:保存数据data格式,列表中嵌套元组,每个元组中表示每一行数据:data=[(img0, label0),(img1, label1),...,(img4, label4)] - 4)
字典格式:保存数据data格式,字典格式,key表示列名,value是列表,表示每一列数据:data={'columns_name1':[img0, img1,...,img4], 'columns_name2': [label0, label1,...,label4]}
columns参数是每一列的列名,值是列名的列表!
3、df1.to_csv('../test_data/filename1.csv')的参数,这里只说两个比较常用的参数
path_or_buf参数:保存csv文件名index参数:默认值是True,表示保存每行的行索引,如果设置位False表示不保存行索引!
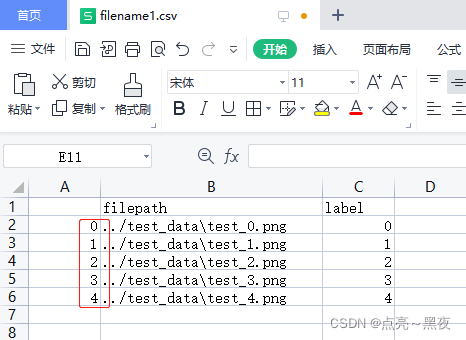
filename1.csv:默认是保存了行索引(filename3.csv和filename4.csv的内容也是如下,一样的!)
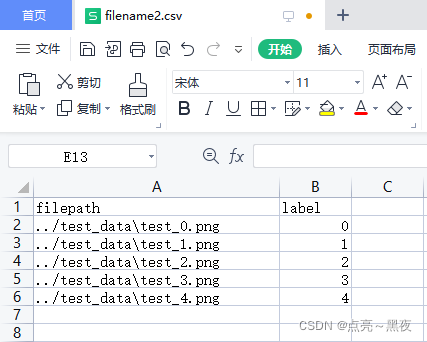
filename2.csv:没有保存行索引
注意:
我们一般保存的CSV文件是不需要保存索引的,直接设置为False吧,否则这个索引也会作为单独的一列数据
3 使用python pandas 读取csv的每行、每列数据
1、直接上代码,我打印出了每一步的结果,方便大家理解!
# coding=utf-8
"""
Copyright (c) 2018-2022. All Rights Reserved.
@author: shliang
@email: shliang0603@gmail.com
创建和导入csv文件
"""
import pandas as pd
import glob
import os
import numpy as np
# 读取csv文件
def read_csv_file():
'''
下面我们来读取数据拿到上面创建的csv文件,主要操作:
- 读取每一行数据:一行代表一个样本
- 读取每一列数据:一列表示所有样本的一个属性
:return:
'''
data_info1 = pd.read_csv('../test_data/filename1.csv')
data_info2 = pd.read_csv('../test_data/filename2.csv')
print(type(data_info1)) # <class 'pandas.core.frame.DataFrame'>
# 查看前几行数据
print(data_info1.head()) # 默认查看前5行数据
print(data_info1.head(3)) # 指定查看的数据行数
print(data_info2.head())
'''
Unnamed: 0 filepath label
0 0 ../test_data\test_0.png 0
1 1 ../test_data\test_1.png 1
2 2 ../test_data\test_2.png 2
3 3 ../test_data\test_3.png 3
4 4 ../test_data\test_4.png 4
Unnamed: 0 filepath label
0 0 ../test_data\test_0.png 0
1 1 ../test_data\test_1.png 1
2 2 ../test_data\test_2.png 2
filepath label
0 ../test_data\test_0.png 0
1 ../test_data\test_1.png 1
2 ../test_data\test_2.png 2
3 ../test_data\test_3.png 3
4 ../test_data\test_4.png 4
'''
# 获取数据的行和列数据
print(data_info1.shape) # (5, 3) # 5行、3列数据,每一行表示一个样本数据,这里的第一列是行索引
print(data_info2.shape) # (5, 2)
# 获取每一列的数据类型
print(data_info1.dtypes)
print(data_info2.dtypes)
'''
Unnamed: 0 int64
filepath object
label int64
dtype: object
filepath object
label int64
dtype: object
'''
################################################################################################
# 获取列名
columns1 = data_info1.columns
columns2 = data_info2.columns
print('coloumns1:', columns1)
print('coloumns2:', columns2)
# 把列名转换成列表 to_list() 或 tolist() 两种方法是一样的,源码中有赋值to_list = tolist
columns1_list = data_info1.columns.tolist()
columns2_list = data_info2.columns.to_list()
print('coloumns1 list:', columns1_list)
print('coloumns2 list:', columns2_list)
'''
coloumns1: Index(['Unnamed: 0', 'filepath', 'label'], dtype='object')
coloumns2: Index(['filepath', 'label'], dtype='object')
coloumns1 list: ['Unnamed: 0', 'filepath', 'label']
coloumns2 list: ['filepath', 'label']
'''
# 获取指定列数据
filenames1 = data_info1['filepath']
filenames2 = data_info1[['filepath']]
# 获取指定多列数据,把要获取的列名放到一个列表中,确保你的列名正确并存在,否则报KeyError
filenames3 = data_info1[['filepath', 'label']]
print('filenames1:', filenames1)
print('filenames2:', filenames2)
print('filenames3:', filenames3)
# 把获取的某一列数转换成列表
filename1_list = data_info1['filepath'].tolist()
print('filenames1 list:', filename1_list)
'''
filenames1: 0 ../test_data\test_0.png
1 ../test_data\test_1.png
2 ../test_data\test_2.png
3 ../test_data\test_3.png
4 ../test_data\test_4.png
Name: filepath, dtype: object
filenames2: filepath
0 ../test_data\test_0.png
1 ../test_data\test_1.png
2 ../test_data\test_2.png
3 ../test_data\test_3.png
4 ../test_data\test_4.png
filenames3: filepath label
0 ../test_data\test_0.png 0
1 ../test_data\test_1.png 1
2 ../test_data\test_2.png 2
3 ../test_data\test_3.png 3
4 ../test_data\test_4.png 4
filenames1 list: ['../test_data\\test_0.png', '../test_data\\test_1.png', '../test_data\\test_2.png', '../test_data\\test_3.png', '../test_data\\test_4.png']
'''
################################################################################################
# 获取某些行数据
# 去除指定的某一行数据,索引是从0开始的,如下是取出第3行数据。(如果超过行索引会报KeyError)
# object 表示字符串类型的值
line3 = data_info2.loc[2]
print(line3)
'''
filepath ../test_data\test_2.png
label 2
Name: 2, dtype: object
'''
# 取出指定的某一行数据,并转换成列表
line3_list = data_info2.loc[2].tolist()
print('line3 list:', line3_list) # line3 list: ['../test_data\\test_2.png', 2]
# 取出指定的多行数据,如下取出第2行和第4行数据
multi_line_data = data_info2.loc[[1, 3]]
print(multi_line_data) # 得到的对象是DateFrame,还可以对齐进行行列等操作
'''
filepath label
1 ../test_data\test_1.png 1
3 ../test_data\test_3.png 3
'''
# 取出连续多行数据,如下取出第2到第5行数据
mulut_conti_line_data = data_info2.loc[1:5]
print(mulut_conti_line_data) # 得到的对象是DateFrame,还可以对齐进行行列等操作
'''
filepath label
1 ../test_data\test_1.png 1
2 ../test_data\test_2.png 2
3 ../test_data\test_3.png 3
4 ../test_data\test_4.png 4
'''
# 对DataFrame的每一行进行循环
for index, row in data_info2.iterrows():
# print(row)
'''
filepath ../test_data\test_0.png
label 0
Name: 0, dtype: object
'''
# 然后根据列名,获取指定的行对应指定列的数据
filepath = row['filepath']
label = row['label']
print(filepath, label) # ../test_data\test_0.png 0
if __name__ == '__main__':
read_csv_file()

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 16
16 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)