python之时间序列算法(ARMA)
关于时间序列的算法,我想把它们分成两类:基于统计学的方法。基于人工智能的方法。传统的统计学的方法:从最初的随机游走模型(RW)、历史均值(HA)、马尔科夫模型、时间序列模型和卡尔曼滤波模型。RW和HA依赖与理论假设,并未考虑交通流的波动性,以致预测结果与现实存在很大差异;而马尔科夫模型、时间序列模型和卡尔曼滤波模型则根据现有道路的历史交通流数据假定交通流符合某种概率分布,从而进行训练,估计出模型参
关于时间序列的算法,我想把它们分成两类:
- 基于统计学的方法。
- 基于人工智能的方法。
传统的统计学的方法:从最初的随机游走模型(RW)、历史均值(HA)、马尔科夫模型、时间序列模型和卡尔曼滤波模型。RW和HA依赖与理论假设,并未考虑交通流的波动性,以致预测结果与现实存在很大差异;而马尔科夫模型、时间序列模型和卡尔曼滤波模型则根据现有道路的历史交通流数据假定交通流符合某种概率分布,从而进行训练,估计出模型参数。今天我们介绍最经典的统计学算法——自回归滑动平均模型(ARMA)。
1.介绍ARMA
大家都知道,统计学处理数据,对数据的要求极为严格,需要在做分析之前,对数据进行假设检验,参数估计等等,ARMA模型也不例外。需要对时间序列的随机性和平稳性进行检验,根据检验的结果,可将序列分为不同的类型:
- 纯随机序列(白噪声序列):序列的各项之间没有任何的相关关系,序列在进行完全无序的波动,对于这样的序列,ARMA选择放弃分析。
- 平稳非白噪声序列:平稳的意思指该序列的均值和方差是常数,对于该类型的数据,我们通常建立一个线性拟合该序列的发展,比如使用ARMA。
- 非平稳序列:它的均值和方差不稳定,处理方法一般是将其转化为平稳性数据,然后再使用ARMA算法。
2.平稳性检验
2.1 平稳时间序列的定义
这里我们主要记住时间序列的任何一个时刻的序列值都是一个随机变量,然后求他们的均值和方差。

2.2 平稳性检验的方法
关于平稳性检验,画图是较为简单的方法,一般情况下,先画个图再再觉得要不要进行下一步的检验。


3.ARMA模型介绍
ARMA模型可以分为两个部分,AR模型和MA模型部分。
-
AR模型:在t时刻的随机变量 X ( t ) X_{(t)} X(t)的取值 x ( t ) x_{(t)} x(t)是关于过去p期 x ( t − 1 ) x_{(t-1)} x(t−1), x ( t − 2 ) x_{(t-2)} x(t−2), x ( t − 3 ) x_{(t-3)} x(t−3),… 多元线性回归。认为 x ( t ) x_{(t)} x(t)主要受到过去p时间的影响。误差项 ε ( t ) \varepsilon_{(t)} ε(t)是当期的随机扰动。
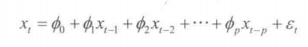
-
MA模型:在t时刻的随机变量 X ( t ) X_{(t)} X(t)的取值 x ( t ) x_{(t)} x(t)是关于过去q期随机扰动项 ε ( t − 1 ) \varepsilon_{(t-1)} ε(t−1), ε ( t − 2 ) \varepsilon_{(t-2)} ε(t−2), ε ( t − 3 ) \varepsilon_{(t-3)} ε(t−3),… 多元线性回归。认为 x ( t ) x_{(t)} x(t)主要受到过去q时间随机扰动的影响。 μ \mu μ是 X t X_{t} Xt的均值。(有限阶的MA模型一定是平稳的)
在这里解释一下随机扰动:是指 X ( t ) X_{(t)} X(t)的波动不确定的部分,我们就用无穷阶的AR模型来表示。
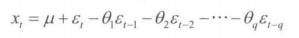
-
ARMA模型:在t时刻的随机变量 X ( t ) X_{(t)} X(t)的取值 x ( t ) x_{(t)} x(t)是关于过去p期 x ( t − 1 ) x_{(t-1)} x(t−1), x ( t − 2 ) x_{(t-2)} x(t−2), x ( t − 3 ) x_{(t-3)} x(t−3),…和过去q期随机扰动项 ε ( t − 1 ) \varepsilon_{(t-1)} ε(t−1), ε ( t − 2 ) \varepsilon_{(t-2)} ε(t−2), ε ( t − 3 ) \varepsilon_{(t-3)} ε(t−3),… 的多元线性回归。
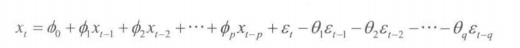
某个时间序列经过预处理,被判定为平稳非白噪声序列,就可以利用ARMA模型进行建模。
4.非平稳时间序列分析
其实我们获取的数据多情况下是非平稳的数据,因而学会对非平稳数据的分析才更加重要。我们把非平稳的时间序列的分析主要分为两类:
- 确定性因素分析:把所有的序列的变化都归结于4个因素(长期趋势、季节变动、循环变动和随机波动)的综合影响。其中前两个因素规律较为明显,容易分析,而后两个因素的随机性较大,难以确定和分析。拟合的模型经常不够理想。
- 随机时序分析:为了弥补确定性因素分析的不足,我们使用随机序列模型来进行分析。可以建立的模型有ARIMA、残差自回归模型、季节模型、异方差模型等。这里我们主要介绍ARIMA,记得多了个I。
对非平稳的时间序列进行分析主要是将非平稳的序列转化为平稳的序列,然后再进行时间序列的建模。差分运算就是最常用的方法,通过将相距一定距离的两个序列的值进行减法运算后,许多非平稳序列就会显示出平稳数据的特征。这时称这个序列为差分平稳序列。然后就可用ARMA模型进行拟合。而ARIMA就是差分运算和ARMA模型的组合。会了ARMA就会了ARIMA!
5.ARMA案例
先介绍一下python中数理统计的库==StatModels ==这里面主要包含了统计学的一些计算方法。

开始啦!我们这里以非平稳数据为例,先看看数据,只有日期和销量标签。

1.获取数据,画图,发现有递增的趋势,所以不是平稳时间序列数据。
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf
discfile = 'C:\\Users\\Administrator\\Desktop\\python-code\\《Python数据分析与挖掘实战(第2版)》源数据和代码\\《Python数据分析与挖掘实战(第2版)》源数据和代码-各章节\\chapter5\\demo\\data\\arima_data.xls'
#forecastnum = 5
#读取文件
data = pd.read_excel(discfile, index_col = u'日期')
#补全中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data.plot()
plt.show()

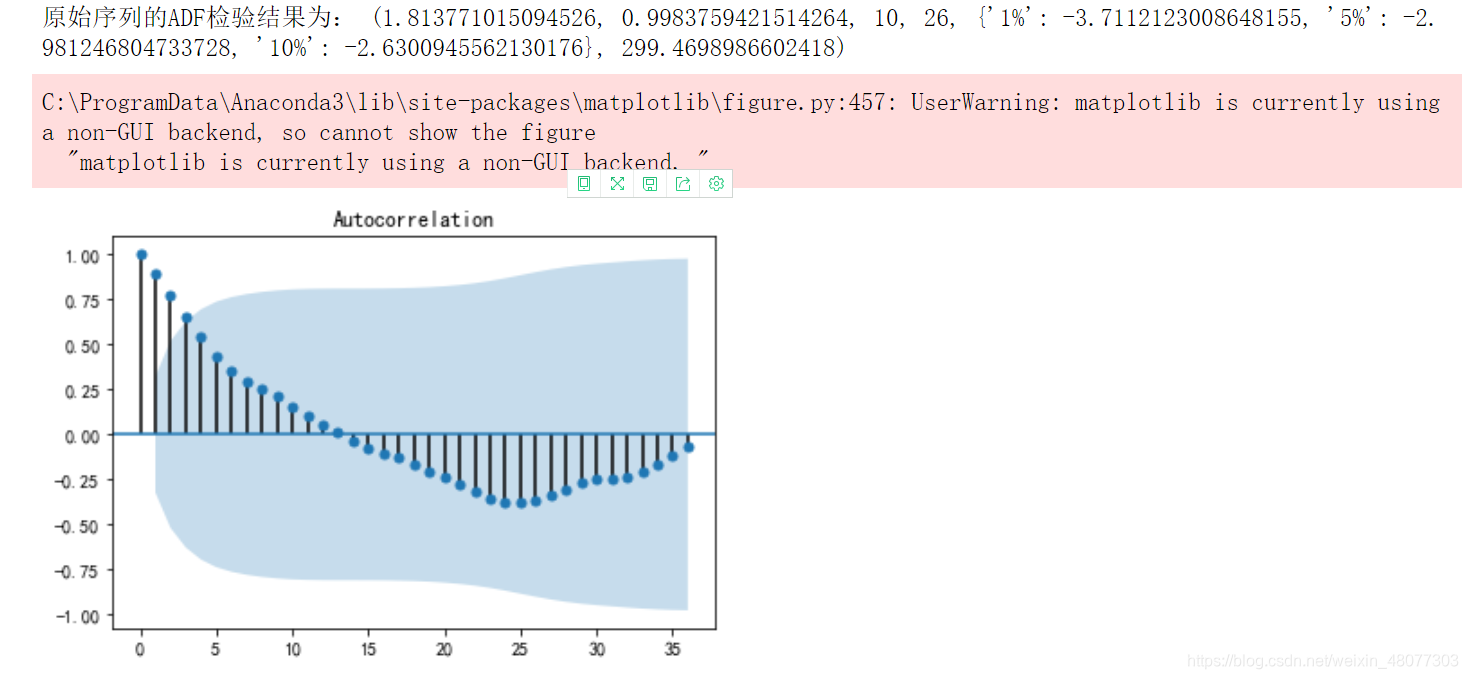
2.自相关图和平稳性检验发现真的是非平稳序列,自相关图有一半大于0,说明有很强的长期相关性。
# 平稳性检测
# 自相关图
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(data).show()
# 平稳性检测
from statsmodels.tsa.stattools import adfuller as ADF
print(u'原始序列的ADF检验结果为:', ADF(data[u'销量']))
# 返回值依次为adf、pvalue、usedlag、nobs、critical values、icbest、regresults、resstore
3.一阶差分、平稳性和白噪声检验
# 差分后的结果
D_data = data.diff().dropna()
D_data.columns = [u'销量差分']
D_data.plot() # 时序图
plt.show()
plot_acf(D_data).show() # 自相关图
from statsmodels.graphics.tsaplots import plot_pacf
plot_pacf(D_data).show() # 偏自相关图
print(u'差分序列的ADF检验结果为:', ADF(D_data[u'销量差分'])) # 平稳性检测
# 白噪声检验
from statsmodels.stats.diagnostic import acorr_ljungbox
print(u'差分序列的白噪声检验结果为:', acorr_ljungbox(D_data, lags=1)) # 返回统计量和p值
一阶差分:感觉有点像平稳的序列

平稳性和白噪声检验

放在表里好看点:p值为0.0227,小于0.05,接受原假设,不能否定原序列不是平稳序列。

自相关图:
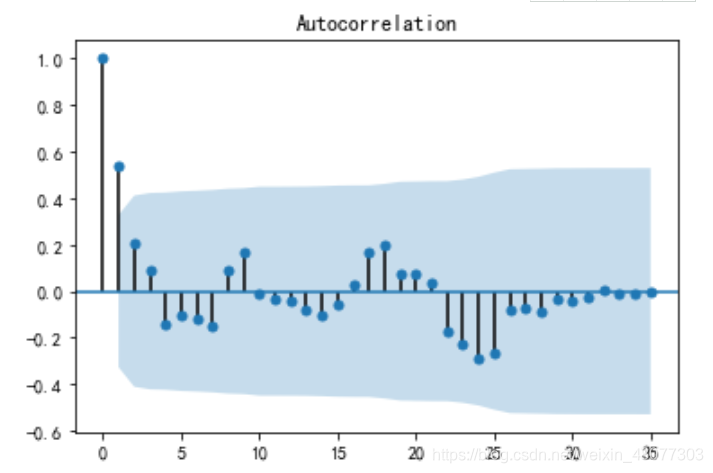
偏自相关图:

白噪声检验:p值小于0.05,接受原假设,是非白噪声数据。

4.ARMA模型定阶
定阶就是选择p和q的范围,这里我们选用BIC检验,组合各种p和q,获取最小BIC值的p和q。
# 定阶
data[u'销量'] = data[u'销量'].astype(float)
pmax = int(len(D_data)/10) # 一般阶数不超过length/10
qmax = int(len(D_data)/10) # 一般阶数不超过length/10
bic_matrix = [] # BIC矩阵
for p in range(pmax+1):
tmp = []
for q in range(qmax+1):
try: # 存在部分报错,所以用try来跳过报错。
tmp.append(ARIMA(data, (p,1,q)).fit().bic)
except:
tmp.append(None)
bic_matrix.append(tmp)
bic_matrix = pd.DataFrame(bic_matrix) # 从中可以找出最小值
p,q = bic_matrix.stack().idxmin() # 先用stack展平,然后用idxmin找出最小值位置。
print(u'BIC最小的p值和q值为:%s、%s' %(p,q))
结果:

5.ARMA模型使用
使用AR(1)模型拟合一阶差分后的序列,,即对原始序列建立ARIMA(0,1,1)模型,并对其进行参数检验。
model = ARIMA(data, (p,1,q)).fit() # 建立ARIMA(0, 1, 1)模型
print('模型报告为:\n', model.summary2())
print('预测未来5天,其预测结果、标准误差、置信区间如下:\n', model.forecast(5))
粉红框框的是参数检验的值,然后利用模型对2015年1月1日到2015年2月6日的销售数据进行预测。

做完后,我心里默默想说一句,还是用LSTM,GRU,TCN这些神经网络吧。(传统方法还是要学习)
参考文献:
书籍:《python数据分析与挖掘实战》

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 42
42 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)