
Python之Pandas
Python之pandas环境:jupyter Notebook(Anaconda)1.引入pandas库和numpy库import pandas as pdimport numpy as np2. 读取文件t1=pd.read_excel('D:\scores.xlsx',header=[0,1],index_col=0) #读取文件t1#index_col 接收int、sequence或者Fa
·
Python之pandas
文章目录
环境:jupyter Notebook(Anaconda)
1.引入pandas库和numpy库
import pandas as pd
import numpy as np
2. 读取文件
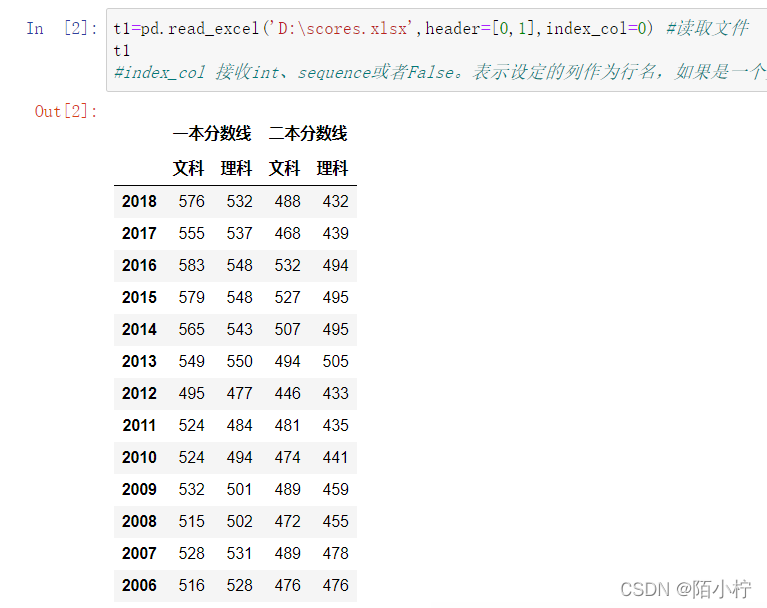
t1=pd.read_excel('D:\scores.xlsx',header=[0,1],index_col=0) #读取文件
t1
#index_col 接收int、sequence或者False。表示设定的列作为行名,如果是一个数列,则是多重索引,默认为None
3. index函数
index 接收boolean。表示是否将行索引作为数据传入数据库。默认为True
index_label 接收string或者sequence.代表是否引用索引名称,如果index参数为true,此参数为None,则使用默认名称。如果为多重索引,则必须使用sequence形式。默认为None
sorted_obj=t1.sort_index(ascending=True)
sorted_obj

4.max与min函数
# In[15]:
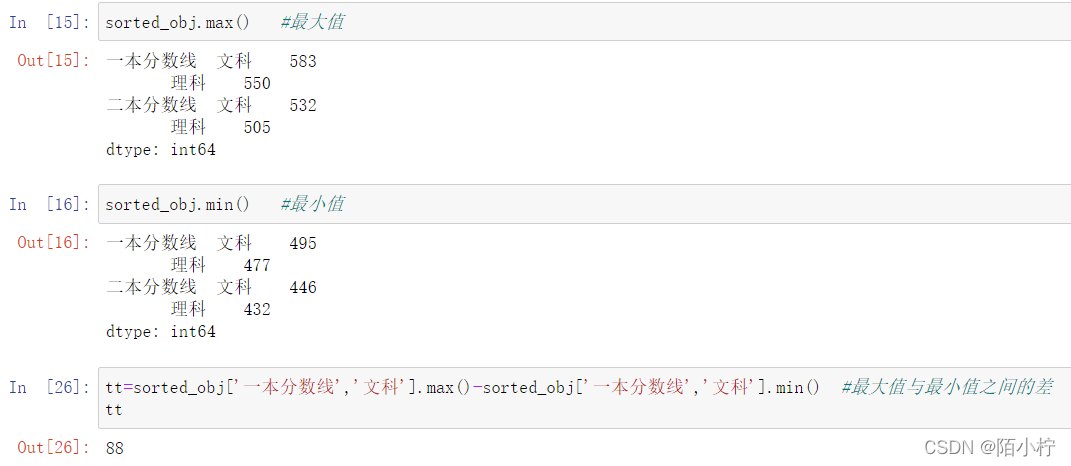
sorted_obj.max() #最大值
# In[16]:
sorted_obj.min() #最小值
# In[26]:
tt=sorted_obj['一本分数线','文科'].max()-sorted_obj['一本分数线','文科'].min() #最大值与最小值之间的差
tt
5. ptp函数
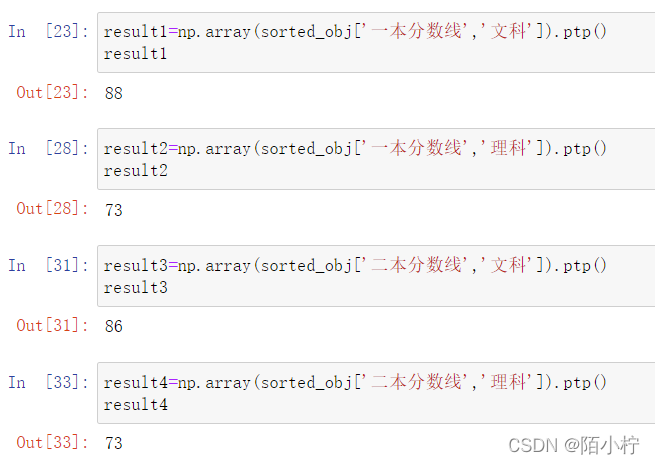
np.ptp()函数实现的功能等同于np.max(array) - np.min(array)
调用ptp()函数计算极差。
# In[23]:
result1=np.array(sorted_obj['一本分数线','文科']).ptp()
result1
# In[28]:
result2=np.array(sorted_obj['一本分数线','理科']).ptp()
result2
# In[31]:
result3=np.array(sorted_obj['二本分数线','文科']).ptp()
result3
# In[33]:
result4=np.array(sorted_obj['二本分数线','理科']).ptp()
result4
6. sorted函数
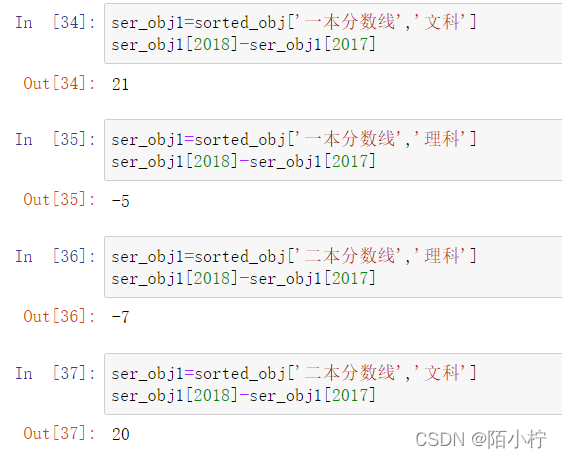
比较2018年一本与二本文理科分数线的差值
# In[34]:
ser_obj1=sorted_obj['一本分数线','文科']
ser_obj1[2018]-ser_obj1[2017]
# In[35]:
ser_obj1=sorted_obj['一本分数线','理科']
ser_obj1[2018]-ser_obj1[2017]
# In[36]:
ser_obj1=sorted_obj['二本分数线','理科']
ser_obj1[2018]-ser_obj1[2017]
# In[37]:
ser_obj1=sorted_obj['二本分数线','文科']
ser_obj1[2018]-ser_obj1[2017]
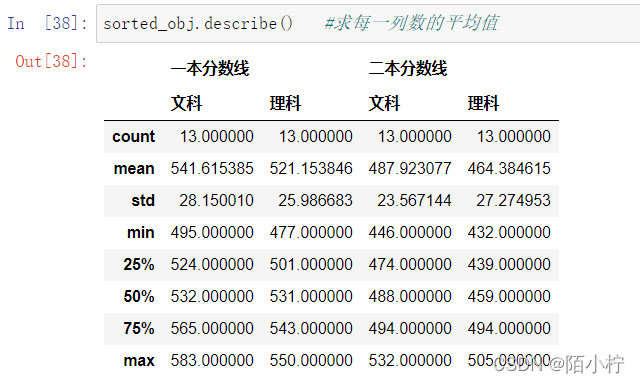
7. describe函数
mean()函数或describe()函数都可以计算出每列的平均数,通过调用describe()方法来查看多个统计指标
计算2006-2018年的平均分数线
# In[38]:
sorted_obj.describe() #求每一列数的平均值

码字不易,觉得内容有帮助的请一键三联哟~
这样我也才有动力和你一起学习

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)