在python中使用SVM
在python 中使用支持向量机
在python 中使用支持向量机
三、在python中使用SVM
参考 OraYang 支持向量机(SVM)的分析及python实现
3.1 scikit-learn库
Scikit-learn(sklearn)是一个开源项目,可以免费使用和分发,任何人都可以轻松获取其源代码来查看其背后的原理。Scikit-learn项目正在不断地开发和改进中,它的用户社区非常活跃。它包含许多目前最先进的机器学习算法,每个算法都有详细的文档 (http:// scikit-learn.org/stable/documentation
scikit-learn是一个非常流行的工具,也是最有名的 Python机器学习库。它广泛应用于工业界和学术界,网上有大量的教程和代码片段。而SVM也可以在scikit-learn库中选择使用。
3.2 SVM在scikit-learn库中的使用
3.2.1 svm.SVC
# Create SVM classification object
sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=None,random_state=None)
参数:
C
C-SVC的惩罚参数C,默认值是1.0。即下图中C权重
C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
kernel
核函数,默认是rbf,可以是‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
– 线性:u’v
– 多项式:(gamma*u’v + coef0)^degree
– RBF函数:exp(-gamma|u-v|^2)
– sigmoid:tanh(gammau’*v + coef0)
degree
多项式poly函数的维度,默认是3,选择其他核函数时会被忽略。
gamma
‘rbf’,‘poly’ 和‘sigmoid’的核函数参数。默认是’auto’,则会选择1/n_features
coef0
核函数的常数项。对于‘poly’和 ‘sigmoid’有用。
probability
是否采用概率估计。默认为False,布尔类型可选。
决定是否启用概率估计。需要在训练fit()模型时加上这个参数,之后才能用相关的方法:predict_proba和predict_log_proba
shrinking
是否采用shrinking heuristic方法(启发式收缩),默认为true
tol
停止训练的误差值大小,默认为1e-3
cache_size
核函数cache缓存大小,默认为200
class_weigh
t类别的权重,字典形式传递。设置第几类的参数C为weight*C(C-SVC中的C)
verbose
允许冗余输出
max_iter
最大迭代次数。-1为无限制。
decision_function_shape
‘ovo’, ‘ovr’ or None, default=None3
random_state
数据洗牌时的种子值,int值
主要调节的参数有:C、kernel、degree、gamma、coef0。
方法:
fit(X, y):训练模型。
predict(X):用模型进行预测,返回预测值。
score(X, y[, sample_weight]):返回在(X, y)上预测的准确率(accuracy)。
predict_log_proba(X): 返回一个数组,数组的元素依次是X预测为各个类别的概率的对数值。
predict_proba(X): 返回一个数组,数组的元素依次是X预测为各个类别的概率值。
3.2.2 datasets
datasets有很多有用的、可以用来训练算法模型的数据库。主要有两种:
1.封装好的经典数据。在代码中以“load”开头。
2.自己设计参数,然后生成的数据。在代码中以“make”开头。
(一) 波士顿房价
统计了波士顿506处房屋的13种不同特征( 包含城镇犯罪率、一氧化氮浓度、住宅平均房间数、到中心区域的加权距离以及自住房平均房价等 )以及房屋的价格,适用于回归任务。
boston = datasets.load_boston() # 导入波士顿房价数据
(二) 鸢尾花
这个数据集包含了150个鸢尾花样本,对应3种鸢尾花,各50个样本,以及它们各自对应的4种关于花外形的数据 ,适用于分类任务。
iris = datasets.load_iris() # 导入鸢尾花数据
(三) 糖尿病
主要包括442个实例,每个实例10个属性值,分别是:Age(年龄)、性别(Sex)、Body mass index(体质指数)、Average Blood Pressure(平均血压)、S1~S6一年后疾病级数指标,Target为一年后患疾病的定量指标, 适用于回归任务。
diabetes = datasets.load_diabetes() # 导入糖尿病数据
(四) 手写数字
共有1797个样本,每个样本有64个元素,对应到一个8x8像素点组成的矩阵,每一个值是其灰度值, target值是0-9,适用于分类任务。
digits = datasets.load_digits() # 导入手写数字数据
3.3 应用实例
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
# 引用 iris 数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 选取前两列作为X参数
y = iris.target # 采集标签作为y参数
C = 1.0 # SVM regularization parameter
# 将所得参数进行模型训练
svc = svm.SVC(kernel='linear', C=1, gamma='auto').fit(X, y)
# 建图
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
plt.subplot(1, 1, 1) # 将显示界面分割成1*1 图形标号为1的网格
Z = svc.predict(np.c_[xx.ravel(), yy.ravel()]) # np.c按行连接两个矩阵,但变量为两个数组,按列连接
Z = Z.reshape(xx.shape)# 重新构造行列
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired, alpha=0.8)# 绘制等高线
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired) # 生成一个scatter散点图。
plt.xlabel('Sepal length') # x轴标签
plt.ylabel('Sepal width') # y轴标签
plt.xlim(xx.min(), xx.max()) # 设置x轴的数值显示范围
plt.title('SVC with linear kernel') # 设置显示图像的名称
plt.savefig('./test1.png') #存储图像
plt.show() # 显示
test1.png如图所示

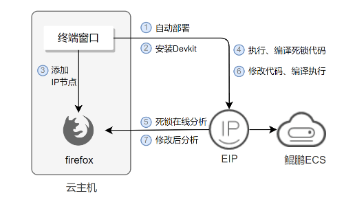
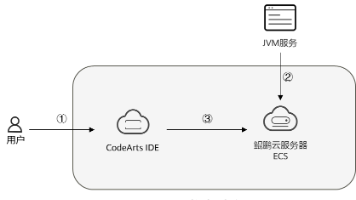
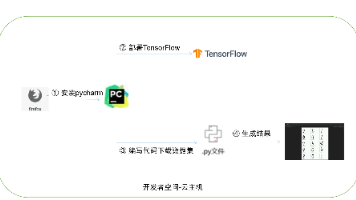
华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)