机器学习之逻辑回归Logistic Regression(python代码实现)
逻辑回归(Logistic Regression)逻辑回归:是一个非常经典的算法。是一种用于解决二分类(0 or 1)问题的机器学习方法,用于估计某种事物的可能性。注:这里用的是“可能性”,而非数学上的“概率”,logisitc回归的结果并非数学定义中的概率值,不可以直接当做概率值来用。该结果往往用于和其他特征值加权求和,而非直接相乘。逻辑回归与线性回归逻辑回归(Logistic Regressi
逻辑回归(Logistic Regression)
逻辑回归是一个非常经典的算法,用于解决分类问题的机器学习方法,用于估计某种事物的可能性,其有着简单、可并行化、可解释强的特点。逻辑回归虽然被称为回归,实际上是分类模型,并常用于二分类。
注:“可能性”而不是数学上的“概率”,逻辑回归的结果并非数学定义中的概率值,不可以直接当做概率值来用。其结果往往用于和其他特征值加权求和,而不是直接相乘。
逻辑回归的本质是假设数据服从这个分布,然后使用极大似然估计做参数的估计。其分布是由位置和尺度参数定义的连续分布。分布的形状与正态分布的形状相似,但是其分布的尾部更长,所以可以使用逻辑分布来建模比正态分布具有更长尾部和更高波峰的数据分布。
1)找到分类边界(曲线)
2)拟合曲线+Sigmoid压缩函数分类
假设函数(Hypothesis function)
模型是把决策函数限定在某一组条件下,这组限定条件就决定了模型的假设空间。
Sigmoid函数(取值[0,1]):
一般选择0.5作为阈值,特定的情况可以选择不同阈值(对正例的判别准确性要求高,可以选择更大的阈值,对正例的召回要求高,可以选择更小的阈值)。
决策边界(Decision Boundary)
决策边界,也称为决策面,是用于在N维空间,将不同类别样本分开的平面或曲面。决策边界就是一个方程。
- 线性决策边界
- 非线性决策边界
注:决策边界是假设函数的属性,由参数决定,不是由数据集的特征决定。
代价函数
代价函数(损失函数)就是能够衡量模型预测值与真实值之间差异的函数,如果有多个样本,则可以将所有代价函数的值求平均或者求和。
逻辑回归与线性回归
相同点:
逻辑回归与线性回归都是一种广义线性模型(generalized linear model)。
不同点:
1)逻辑回归假设因变量 y 服从伯努利分布,而线性回归假设因变量 y 服从高斯分布。
2)逻辑回归用于分类问题,线性回归用于拟合回归问题。
注:逻辑回归算法去除Sigmoid映射函数就是一个线性回归。也就是说,逻辑回归以线性回归为理论支持,并通过Sigmoid函数引入了非线性因素,可以轻松处理0/1分类问题。
python代码实现
自定义实现
import numpy as np
import matplotlib.pyplot as plt
# sigmod函数,即得分函数,计算数据的概率是0还是1;得到y大于等于0.5是1,y小于等于0.5为0。
def sigmod(x):
return 1 / (1 + np.exp(-x))
# 损失函数
# hx是概率估计值,是sigmod(x)得来的值,y是样本真值
def cost(hx, y):
return -y * np.log(hx) - (1 - y) * np.log(1 - hx)
# 梯度下降
def gradient(current_para, x, y, learning_rate):
m = len(y)
matrix_gradient = np.zeros(len(x[0]))
for i in range(m):
current_x = x[i]
current_y = y[i]
current_x = np.asarray(current_x)
matrix_gradient += (sigmod(np.dot(current_para, current_x)) - current_y) * current_x
new_para = current_para - learning_rate * matrix_gradient
return new_para
# 误差计算
def error(para, x, y):
total = len(y)
error_num = 0
for i in range(total):
current_x = x[i]
current_y = y[i]
hx = sigmod(np.dot(para, current_x)) # LR算法
if cost(hx, current_y) > 0.5: # 进一步计算损失
error_num += 1
return error_num / total
# 训练
def train(initial_para, x, y, learning_rate, num_iter):
dataMat = np.asarray(x)
labelMat = np.asarray(y)
para = initial_para
for i in range(num_iter + 1):
para = gradient(para, dataMat, labelMat, learning_rate) # 梯度下降法
if i % 100 == 0:
err = error(para, dataMat, labelMat)
print("iter:" + str(i) + " ; error:" + str(err))
return para
# 数据集加载
def load_dataset():
dataMat = []
labelMat = []
with open("logistic_regression_binary.csv", "r+") as file_object:
lines = file_object.readlines()
for line in lines:
line_array = line.strip().split()
dataMat.append([1.0, float(line_array[0]), float(line_array[1])]) # 数据
labelMat.append(int(line_array[2])) # 标签
return dataMat, labelMat
# 绘制图形
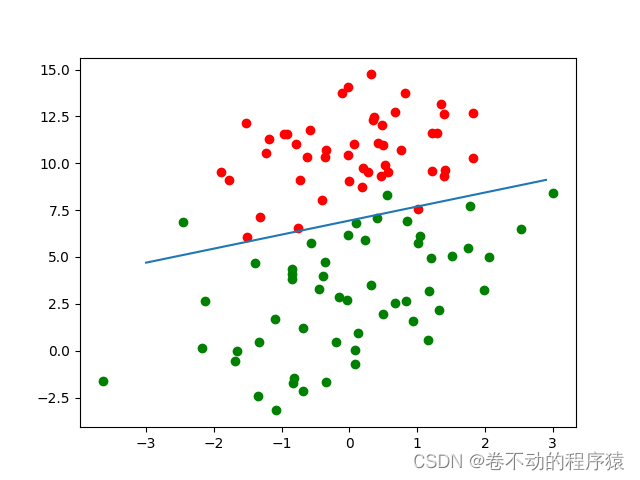
def plotBestFit(wei, data, label):
if type(wei).__name__ == 'ndarray':
weights = wei
else:
weights = wei.getA()
fig = plt.figure(0)
ax = fig.add_subplot(111)
xxx = np.arange(-3, 3, 0.1)
yyy = - weights[0] / weights[2] - weights[1] / weights[2] * xxx
ax.plot(xxx, yyy)
cord1 = []
cord0 = []
for i in range(len(label)):
if label[i] == 1:
cord1.append(data[i][1:3])
else:
cord0.append(data[i][1:3])
cord1 = np.array(cord1)
cord0 = np.array(cord0)
ax.scatter(cord1[:, 0], cord1[:, 1], c='g')
ax.scatter(cord0[:, 0], cord0[:, 1], c='r')
plt.show()
def logistic_regression():
x, y = load_dataset()
n = len(x[0])
initial_para = np.ones(n)
learning_rate = 0.001
num_iter = 1000
print("初始参数:", initial_para)
para = train(initial_para, x, y, learning_rate, num_iter)
print("训练所得参数:", para)
plotBestFit(para, x, y)
if __name__=="__main__":
logistic_regression()sklearn库实现
import numpy as np
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
import matplotlib as mpl # 绘图地图包
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn import datasets
from sklearn.model_selection import train_test_split
def iris_type(s):
it = {b'Iris-setosa': 0, b'Iris-versicolor': 1, b'Iris-virginica': 2}
return it[s]
# 数据预处理
if __name__ == "__main__":
path = u'iris.data'
# sklearn的数据集, 鸢尾花
iris = datasets.load_iris()
x = iris.data[:, :2]
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(x, y, random_state=666)
# 用pipline建立模型
# StandardScaler()作用:去均值和方差归一化。且是针对每一个特征维度来做的,而不是针对样本。 StandardScaler对每列分别标准化。
# LogisticRegression()建立逻辑回归模型
lr = Pipeline([('sc', StandardScaler()), ('clf', LogisticRegression(multi_class="multinomial", solver="newton-cg"))])
lr.fit(X_train, y_train)
# 画图准备
N, M = 500, 500
x1_min, x1_max = x[:, 0].min(), x[:, 0].max()
x2_min, x2_max = x[:, 1].min(), x[:, 1].max()
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, M)
x1, x2 = np.meshgrid(t1, t2)
x_test = np.stack((x1.flat, x2.flat), axis=1)
# 开始画图
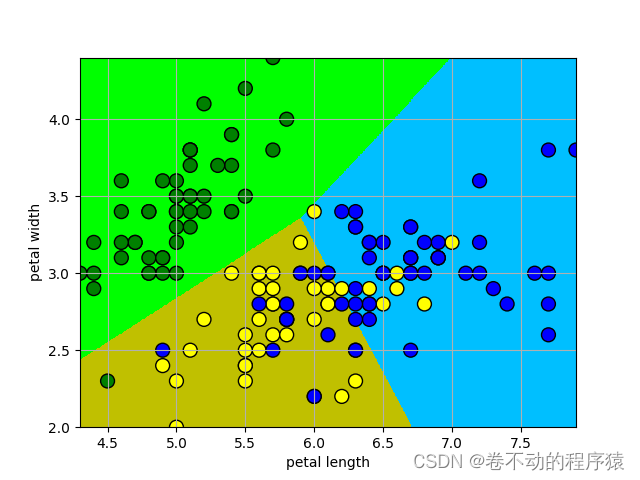
cm_light = mpl.colors.ListedColormap(['#00FF00', '#C0C000', '#00BFFF'])
cm_dark = mpl.colors.ListedColormap(['g', 'yellow', 'b'])
y_hat = lr.predict(x_test) # 预测值
y_hat = y_hat.reshape(x1.shape) # 使之与输入的形状相同
plt.pcolormesh(x1, x2, y_hat, shading='auto', cmap=cm_light) # 预测值的显示 其实就是背景
plt.scatter(x[:, 0], x[:, 1], c=y.ravel(), edgecolors='k', s=100, cmap=cm_dark) # 样本的显示
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid()
plt.savefig('2.png')
plt.show()
# 训练集上的预测结果
y_hat = lr.predict(x) # 回归的y
y = y.ravel() # 变一维,ravel将多维数组降位一维
print(y)
result = y_hat == y # 回归的y和真实值y比较
print(y_hat)
print(result)
acc = np.mean(result) # 求平均数
print('准确率: %.2f%%' % (100 * acc))
为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 21
21 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)