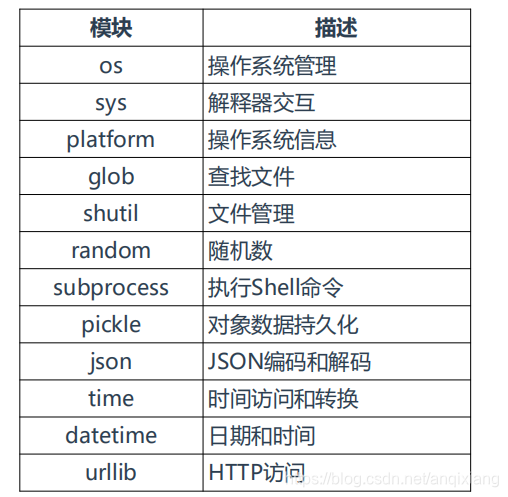
Python常用标准库、模块
文章目录一、常用标准库二、os库`2.1.常用模块方法``2.2.os.path子模块``2.3.遍历目录`三、sys库四、platform五、glob六、random七、subprocess八、pickle九、json`9.1.示例:字典与json互换`十、time十一、datetime`11.1.练习:计算时间差额,如100天零4小时前、100天零4小时后是什么时候`十二、urllib`12.
文章目录
参考视频:https://ke.qq.com/course/320021
一、常用标准库
官方文档标准库列表:https://docs.python.org/zh-cn/3.8/library/index.html
二、os库
os库主要对目录和文件操作
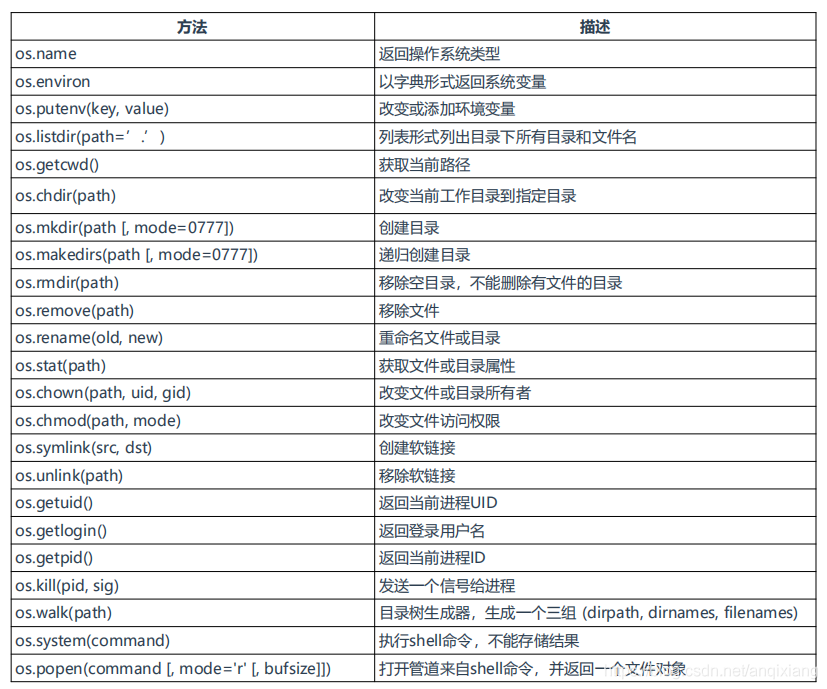

2.1.常用模块方法
>>> import os
>>> os.getcwd() # pwd
>>> os.chdir('/tmp') # cd /tmp
>>> os.listdir('/tmp') # ls /tmp
>>> os.makedirs('/tmp/mydemo/mydir') # mkdir -p创建多级目录
>>> os.mkdir('/tmp/abcde') # mkdir
>>> os.rmdir('/tmp/abcde') # rmdir
>>> os.chdir('/tmp/mydemo/mydir') # cd /tmp/mydemo/mydir
>>> os.mknod('hello') # touch hello
>>> os.symlink('/etc/hosts', 'zhuji') # ln -s /etc/hosts zhuji
>>> os.chmod('hello', 0o644) # chmod 644 hello
>>> os.rename('hello', 'welcome') # mv hello welcome
>>> os.unlink('zhuji') # unlink zhuji # 删除软链接
>>> os.remove('welcome') # 删除文件,等同于rm -f welcome
2.2.os.path子模块
>>> os.path.abspath('.') # 当前路径的绝对路径;获取当前文件的绝对路径
'/tmp/mydemo/mydir'
>>> os.path.dirname('/tmp/demo/abc.txt')
'/tmp/demo'
>>> os.path.basename('/tmp/demo/abc.txt')
'abc.txt'
>>> os.path.join('/tmp/demo', 'abc.txt') # 路径拼接
'/tmp/demo/abc.txt'
>>> os.path.split('/tmp/a.txt') # 分割路径为一个元组
('/tmp', 'a.txt')
>>> os.path.splitext('/tmp/a.txt')[1] # 获取文件后缀
'.txt'
>>> os.path.isdir('/etc') # 存在并且是目录吗?
True
>>> os.path.isfile('/etc/hosts') # 存在并且是文件吗?
True
>>> os.path.islink('/etc/passwd') # 存在并且是链接吗?
False
>>> os.path.ismount('/') # 存在并且是挂载点吗?
True
>>> os.path.exists('/abcd') # 存在吗?
False
2.3.遍历目录
>>> for dirpath,dirname,filename in os.walk('/tmp'):
... print(f"目录路径:{dirpath},目录名:{dirname},文件名:{filename}")

三、sys库
sys库用于与Python解释器交互
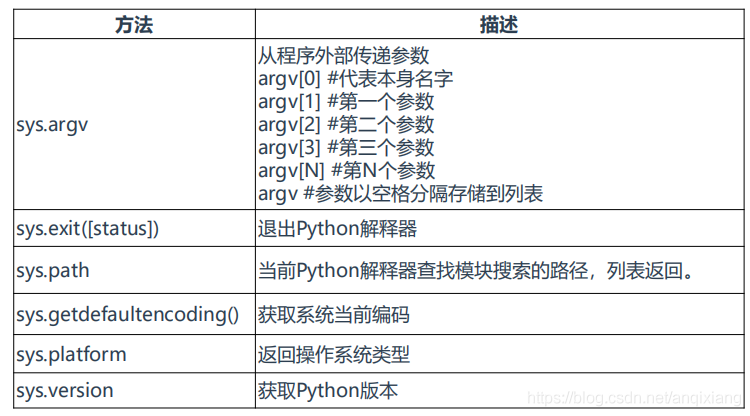
>>> import sys
>>> sys.path #获取Python解释器查找模块的路径,类似于shell的$PATH
四、platform
用于获取操作系统详细信息
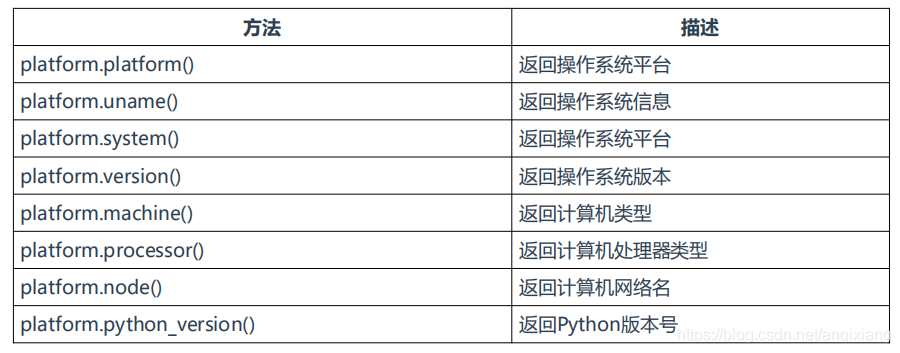
五、glob
用于文件查找,支持通配符(*、?、[])
>>> glob.glob('/home/user/*.sh') #查找目录中所有以.sh为后缀的文件
['/home/user/b.sh', '/home/user/a.sh', '/home/user/sum.sh']
>>> glob.glob('/home/user/?.sh') #查找目录中出现单个字符并以.sh为后缀的文件
['/home/user/b.sh', '/home/user/a.sh']
>>> glob.glob('/home/user/[a|b].sh') #查找目录中出现a.sh或b.sh的文件
['/home/user/b.sh', '/home/user/a.sh']
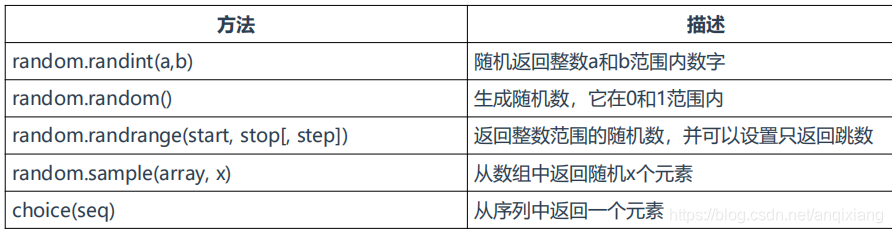
六、random
用于生成随机数
>>> import random
>>> alist = list(range(1,10))
>>> alist
[1, 2, 3, 4, 5, 6, 7, 8, 9]
#随机取出一个数
>>> random.choice(alist)
9
#对列表洗牌
>>> random.shuffle(alist)
>>> alist
[8, 5, 4, 6, 1, 7, 9, 2, 3]
#对列表取样
>>> random.sample(alist, 2)
[8, 6]
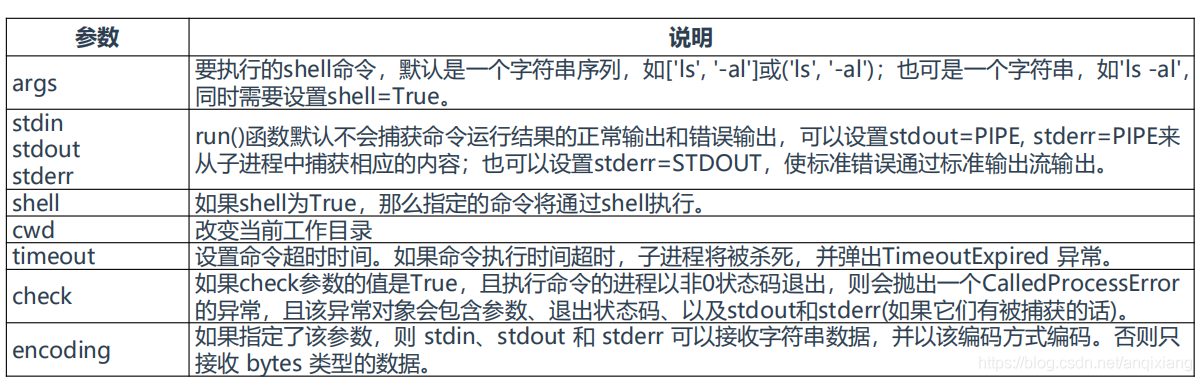
七、subprocess
subprocess库用于执行Shell命令,工作时会fork一个子进程去执行任务,连接到子进程的标准输入、输出、错误,并获得它们的返回代码。
这个模块将取代os.system、os.spawn*、os.popen*、popen2.和commands.。
subprocess的主要方法:
subprocess.run(),subprocess.Popen(),subprocess.call
语法:subprocess.run(args, *, stdin=None, stdout=None, stderr=None, shell=False, cwd=None, timeout=None, check=False, encoding=None)
>>> import subprocess
>>> subprocess.run('ls /home', shell=True)
#返回值
>>> rc = subprocess.run('ping -c2 -i0.2 -w1 192.168.74.133 &>/dev/null', shell=True)
>>> rc.returncode #类似于$?
#捕获输出
>>> rc = subprocess.run('id root; id ddd', shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
>>> rc.returncode
1
>>> rc.stdout.decode()
'uid=0(root) gid=0(root) groups=0(root)\n'
八、pickle
pickle模块实现了对一个Python对象结构的二进制序列化和反序列化。
主要用于将对象持久化到文件存储。
pickle模块主要有两个函数:
• dump() 把对象保存到文件中(序列化),使用load()函数从文件中读取(反序列化)
• dumps() 把对象保存到内存中,使用loads()函数读取
>>> import pickle
>>> shopping_list = ['apple', 'banana', 'orage']
>>> with open('/tmp/shop.data', 'wb') as fobj:
... pickle.dump(shopping_list, fobj) # 序列化
# 取出数据,还是列表的形式
>>> with open('/tmp/shop.data', 'rb') as fobj:
... mylist = pickle.load(fobj) # 反序列化
>>> mylist
['apple', 'banana', 'orage']
九、json
JSON是一种轻量级数据交换格式,一般API返回的数据大多是JSON、XML,如果返回JSON的话,需将获取的数据转换成字典,方便在程序中处理。
json与pickle有相似的接口,主要提供两种方法:
• dumps() 对数据进行编码
• loads() 对数据进行解码
9.1.示例:字典与json互换
import json
computer = {"主机":5000,"显示器":1000,"鼠标":60,"键盘":150}
json_obj = json.dumps(computer)
print(json_obj)
# 将JSON对象转换为字典
data = json.loads(json_obj)
print(data)
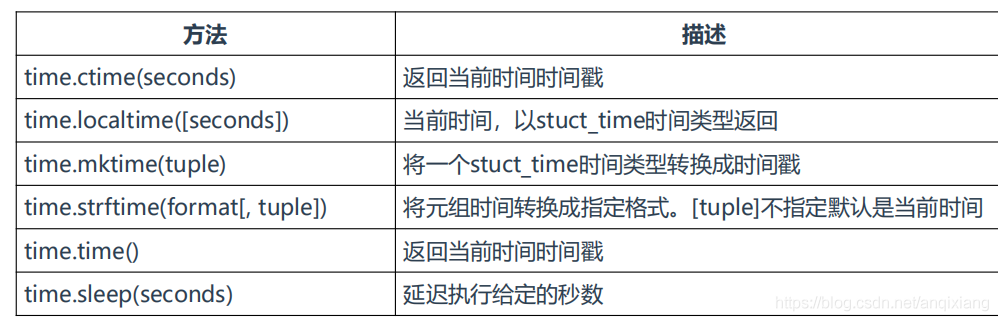
十、time
用于满足简单的时间处理,例如获取当前时间戳、日期、时间、休眠。
>>> import time
>>> time.time() #1970-1-1 0:00:00 到当前时间的秒数
>>> time.ctime() #UTC时间
'Mon Jan 27 10:10:59 2020'
#九元组struct_time
>>> time.localtime()
time.struct_time(tm_year=2020, tm_mon=1, tm_mday=27, tm_hour=10, tm_min=11, tm_sec=20, tm_wday=0, tm_yday=27, tm_isdst=0)
>>> t = time.localtime()
>>> t.tm_year
2020
>> time.sleep(3) # 睡眠3秒
>>> time.strftime('%Y-%m-%d %H:%M:%S')
'2022-01-28 11:46:25
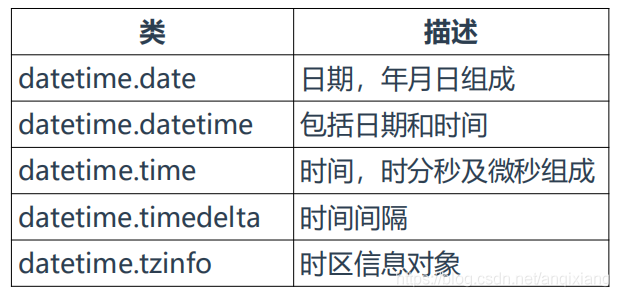
十一、datetime
用于处理更复杂的日期和时间
>>> from datetime import datetime,date
>>> t1 = datetime.now()
>>> t1
datetime.datetime(2020, 1, 27, 10, 21, 39, 621714)
>>> t1.year, t1.month, t1.day, t1.hour, t1.minute, t1.second, t1.microsecond
(2020, 1, 27, 10, 21, 39, 621714)
# 将datetime对象转成时间字符串
>>> datetime.strftime(t1, '%Y-%m-%d %H:%M:%S')
'2019-07-08 10:55:17'
# 将时间字符串转换成datetime对象
>>> datetime.strptime('2019-07-08 10:55:17', '%Y-%m-%d %H:%M:%S')
datetime.datetime(2019, 7, 8, 10, 55, 17)
# 创建指定时间的datetime对象
>>> t = datetime(2019, 7, 8)
>>> t
datetime.datetime(2019, 7, 8, 0, 0)
>>> print(date.today()) #打印年月日
2021-01-10
11.1.练习:计算时间差额,如100天零4小时前、100天零4小时后是什么时候
>>> from datetime import datetime, timedelta
>>> dt = timedelta(days=100, hours=4)
>>> t = datetime.now()
>>> t
datetime.datetime(2019, 7, 8, 11, 38, 13, 922027)
>>> t - dt
datetime.datetime(2019, 3, 30, 7, 38, 13, 922027)
>>> t + dt
datetime.datetime(2019, 10, 16, 15, 38, 13, 922027)
十二、urllib
用于访问URL
urllib包含以下类:
• urllib.request 打开和读取 URL
• urllib.error 包含 urllib.request 抛出的异常
• urllib.parse 用于解析 URL
• urllib.robotparser 用于解析 robots.txt 文件
用的最多是urllib.request 类,它定义了适用于在各种复杂情况下打开 URL,例如基本认证、重定向、Cookie、代理等。
from urllib import request
res = request.urlopen("http://www.ctnrs.com")
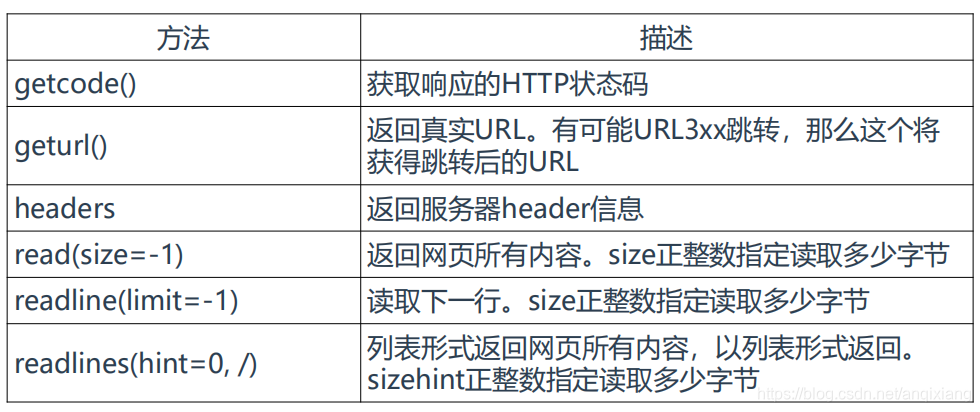
res是一个HTTPResponse类型的对象,包含以下方法和属性
12.1.示例1:自定义用户代理
from urllib import request
url = "http://www.ctnrs.com"
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108Safari/537.36"
header = {"User-Agent": user_agent}
req = request.Request(url, headers=header)
res = request.urlopen(req)
print(res.getcode())
12.2.示例2:向接口提交用户数据
from urllib import request, parse
url = "http://www.ctnrs.com/login"
post_data = {"username":"user1","password":"123456"}
post_data = parse.urlencode(post_data).encode("utf8") #将字典转为URL查询字符串格式,并转为bytes类型
req = request.Request(url, data=post_data, headers=header)
res = request.urlopen(req)
print(res.read())
十三、hashlib模块
用于计算文件的哈希值
# 计算文件的md5值
>>> with open('/etc/passwd', 'rb') as fobj:
... data = fobj.read()
>>> m = hashlib.md5(data)
>>> m.hexdigest()
'decb544ed171583bb1d7722500910d9e'
十四、tarfile模块
实现打包压缩、解压缩,同时支持gzip / bzip2 / xz格式
# 压缩
>>> import tarfile
>>> tar = tarfile.open('/tmp/mytest.tar.gz', 'w:gz') # 用gzip压缩
>>> tar.add('/etc/hosts') # 压缩单个文件
>>> tar.add('/etc/security') # 压缩目录
>>> tar.close() # 关闭
# 解压
>>> tar = tarfile.open('/tmp/mytest.tar.gz') # 自动识别压缩格式,以读方式打开
>>> tar.extractall(path='/var/tmp') # 指定解压目录,默认解到当前目录
>>> tar.close()
十五、shutil
>>> import shutil
>>> shutil.copy2('/bin/ls', '/tmp/list7') #相当于cp -p
>>> shutil.copytree('/etc/security', '/tmp/security') #相当于cp -r
>>> shutil.move('/tmp/security', '/var/tmp/anquan') #相当于mv
>>> shutil.rmtree('/var/tmp/anquan') #相当于rm -rf
十六、requests请问url
get请求
import requests
from requests.auth import HTTPBasicAuth
url = "http://192.168.1.2:8088/artifactory/release/"
username = "admin"
password = "123456"
res = requests.get(url,auth=HTTPBasicAuth(username,password )
data = req.text # 返回网页内容,类型为字符串
post请求

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 41
41 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)