解析吃豆人游戏
【人工智能导论】解析吃豆人游戏Q1: Reflex AgentQ2: MinimaxQ3: Alpha-Beta PruningQ4: Evaluation Function
实验二:吃豆人(对抗搜索)

实验简介: http://ai.berkeley.edu/project_overview.html

实验文件
| 需要编写的文件 | 备注 |
|---|---|
| multiAgents.py | 所有的搜索智能体都将在此文件中 |
| 需要查看的文件 | |
| pacman.py | 运行吃豆人游戏的主文件。该文件包含了GameState类,它将在游戏中被广泛运用 |
| game.py | 该文件实现了吃豆人游戏的运行逻辑,包含了像AgentState,Agent,Direction,Grid等几个起到支持作用的类 |
| util.py | 该文件包含了实现搜索算法需要的数据结构 |
| 可忽略的支撑文件 | |
| ghostAgents.py | 该文件控制幽灵的智能体 |
| graphicsDisplay.py | 该文件实现吃豆人游戏的图形界面 |
| graphicsUtils.py | 该文件为吃豆人游戏的图形界面提供支持 |
| keyboardAgents.py | 该文件实现通过键盘控制吃豆人 |
| layout.py | 该文件包含了读取游戏布局文件和保存布局内容的代码 |
| textDisplay.py | 该文件为吃豆人游戏提供ASCII码形式展现的图形 |
一堆并行的文件看起来很复杂,不知道从哪下手,其实打开文件,会发现我们已经被安排的明明白白了,有一个大大的注释 YOUR CODE HERE,只需要在那里添加进代码即可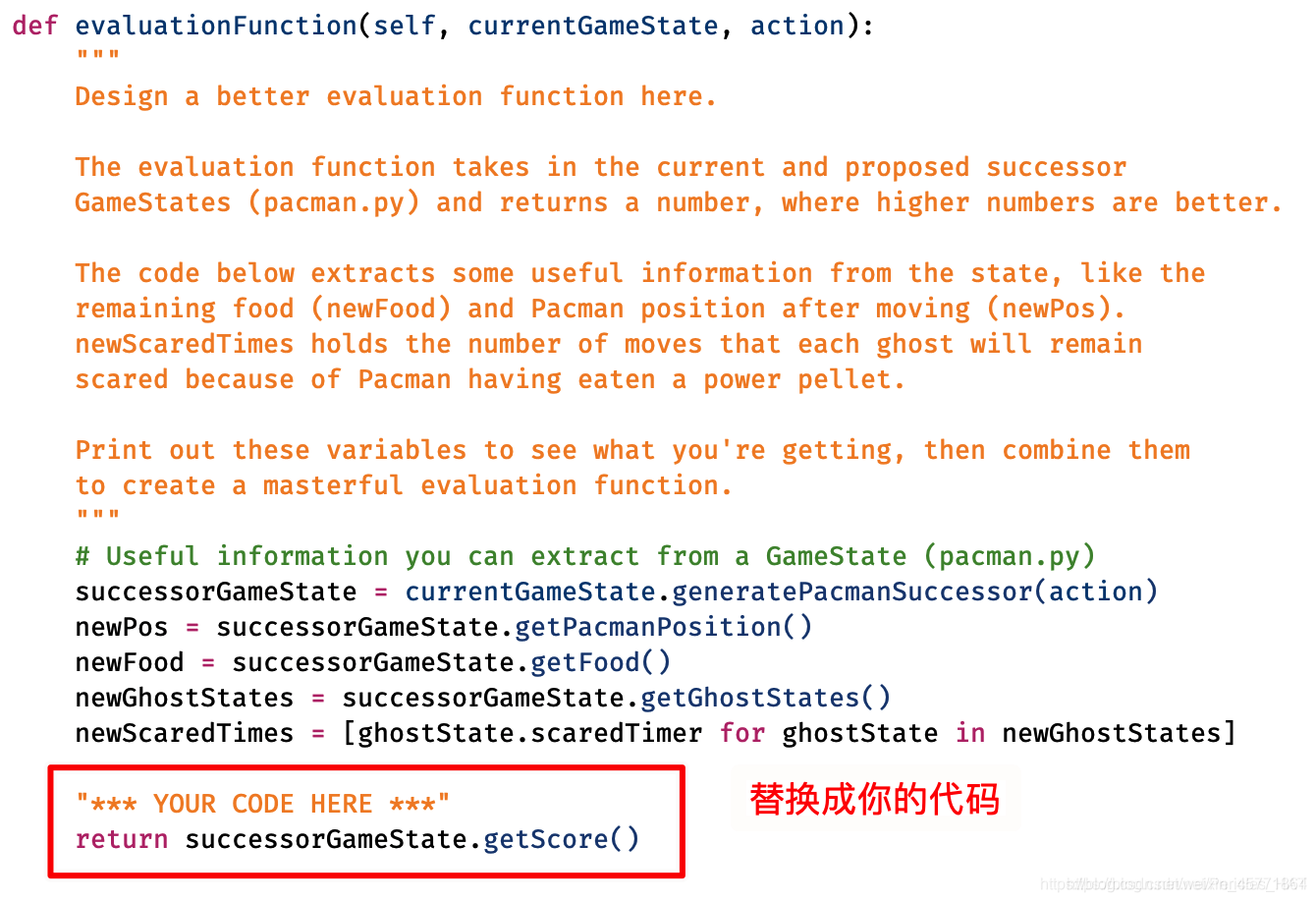
下面说说命令行:
命令 -g DirectionalGhost 使游戏中的幽灵更聪明和有方向性;你也可以通过命令 -n 来让游戏运行多次;使用命令 -q 关闭图形化界面使游戏更快运行;用 –frameTime 0 加速游戏画面。
常用的命令列举(方便测试时复制粘贴):
// 题1:Reflex智能体
python pacman.py // 通过键盘方向键控制
python pacman.py -p ReflexAgent -l testClassic // 在默认布局测试Reflex智能体
python pacman.py -p ReflexAgent -l testClassic -g DirectionalGhost // -g DirectionalGhost 使游戏中的幽灵更聪明和有方向性
python pacman.py -p ReflexAgent -l testClassic -g DirectionalGhost -q -n 10 // -q 关闭图形化界面使游戏更快运行 -n 让游戏运行多次,这段命令是运行了十次
python pacman.py --frameTime 0 -p ReflexAgent -k 2 // 设置2个幽灵,同时提升加速显示
python pacman.py --frameTime 0 -p ReflexAgent -k 1 // 设置1个幽灵,同时提升加速显示
python pacman.py -p ReflexAgent -l openClassic // 在openClassic布局测试Reflex智能体
python pacman.py -p ReflexAgent -l openClassic -q -n 15
python pacman.py -p ReflexAgent -l openClassic -g DirectionalGhost
python pacman.py -p ReflexAgent -l openClassic -g DirectionalGhost -q -n 10
......
// 题2:Minimax
python pacman.py -p MinimaxAgent -l minimaxClassic -a depth=4
python pacman.py -p MinimaxAgent -l trappedClassic -a depth=3
python pacman.py -p MinimaxAgent -l minimaxClassic -a depth=3 -q -n 10
python pacman.py -p MinimaxAgent -l openClassic -a depth=3 -g DirectionalGhost
python pacman.py -p MinimaxAgent -l mediumClassic -a depth=3 -g DirectionalGhost
python pacman.py -p MinimaxAgent -l smallClassic -a depth=3 -g DirectionalGhost
// 题3: Alpha-Beta
python pacman.py -p AlphaBetaAgent -a depth=3 -l smallClassic -k 1 -q -n 10
python pacman.py -p AlphaBetaAgent -a depth=3 -l smallClassic -k 1 -g DirectionalGhost -q -n 10
python pacman.py -p AlphaBetaAgent -a depth=2 -l smallClassic -g DirectionalGhost
python pacman.py -p AlphaBetaAgent -a depth=3 -l smallClassic -g DirectionalGhost
......
其实无非就是在命令行后面更改后缀而已,还有其他组合形式的命令,我就不贴了
(知识点概要很多是从其他人的博客复制粘贴的,因为是片段摘取,所以可能会导致缺乏连贯性,建议拉到底看参考资料链接。如果想直接看代码解析,那就跳过知识点概要即可)
对抗搜索(博弈搜索)
最典型的例子便是: 井字棋


井字棋是一种在3 × 3格子上进行的连珠游戏,和五子棋类似,分别代表O和X的两个游戏者轮流在格子里留下标记(一般来说先手者为X),任意三个标记形成一条直线,则为获胜
什么是对抗搜索?
对抗搜索涉及几个常见概念:智能体、对抗搜索和博弈树
智能体
智能体(agents):在信息技术尤其是人工智能和计算机领域,可以看作是能够通过传感器感知其环境,并借助于执行器作用于该环境的任何事物。以人类为例,我们是通过人类自身的五个感官(传感器)来感知环境的,然后我们对其进行思考,继而使用我们的身体部位(执行器)去执行操作。类似地,机器智能体通过我们向其提供的传感器来感知环境(可以是相机、麦克风、红外探测器),然后进行一些计算(思考),继而使用各种各样的电机/执行器来执行操作。现在,你应该清楚在你周围的世界充满了各种智能体,如你的手机、真空清洁器、智能冰箱、恒温器、相机,甚至你自己。
对抗搜索
对抗搜索也称为博弈搜索,在人工智能领域可以定义为:在一定规则条件下,有完整信息的、确定性的、轮流行动的、两个游戏者的零和游戏(如象棋)
游戏:意味着处理互动情况,互动意味着有玩家会参与进来(一个或多个);
确定性的:表示在任何时间点上,玩家之间都有有限的互动;
轮流行动的:表示玩家按照一定顺序进行游戏,轮流出招;
零和游戏:意味着游戏双方有着相反的目标,换句话说:在游戏的任何终结状态下,所有玩家获得的总和等于零,有时这样的游戏也被称为严格竞争博弈;
关于零和,也可以这样来理解:自己的幸福是建立在他人的痛苦之上的,二者的大小完全相等,因而双方都想尽一切办法以实现“损人利己”。零和博弈的结果是一方吃掉另一方,一方的所得正是另一方的所失,整个社会的利益并不会因此而增加一分。
例如下井字棋,一个游戏者赢了+1,则另一个一定输了-1,总和等于零。
博弈树
考虑两个游戏者:MIN和MAX,MAX先行,然后两人轮流出招,直到游戏结束。在游戏最后,给优胜者积分,给失败者罚分。
游戏可以形式地定义成含有下列组成部分的一类搜索问题:
初始状态,包含棋盘局面和确定该哪个游戏者出招。
后继状态,返回(move,state)对(这两项分别为招数、状态)的一个列表,其中每一对表示一个合法的招数和其结果状态。
终止测试,测试判断游戏是否结束,游戏结束的状态称为终止状态。
效用(收益)函数,效用函数(又称为目标函数或者收益函数),对终止状态给出一个数值。在井字棋中,结果是赢、输或平,分别赋予数值+1、-1或0。有些游戏有更多的可能结果,例如双陆棋的收益范围从-192到+192。
每方的初始状态和合法招数定义了游戏的博弈树。下图给出井字棋的部分博弈树。在初始状态,MIN有9个可能的走法。游戏交替执行,MAX下X,MIN下O,直到我们到达了树的叶节点对应的终止状态,也就是说一方的三个棋子连成一条直线或者所有棋位都填满了。叶节点上的数字指示了这个终止状态对于MAX来说的效用值;值越高被认为对MAX越有利,而对MIN则越不利。所以MAX的任务是利用搜索树(特别是终止状态的效用值)来确定最佳的招数,即求解终止状态为+1的招数
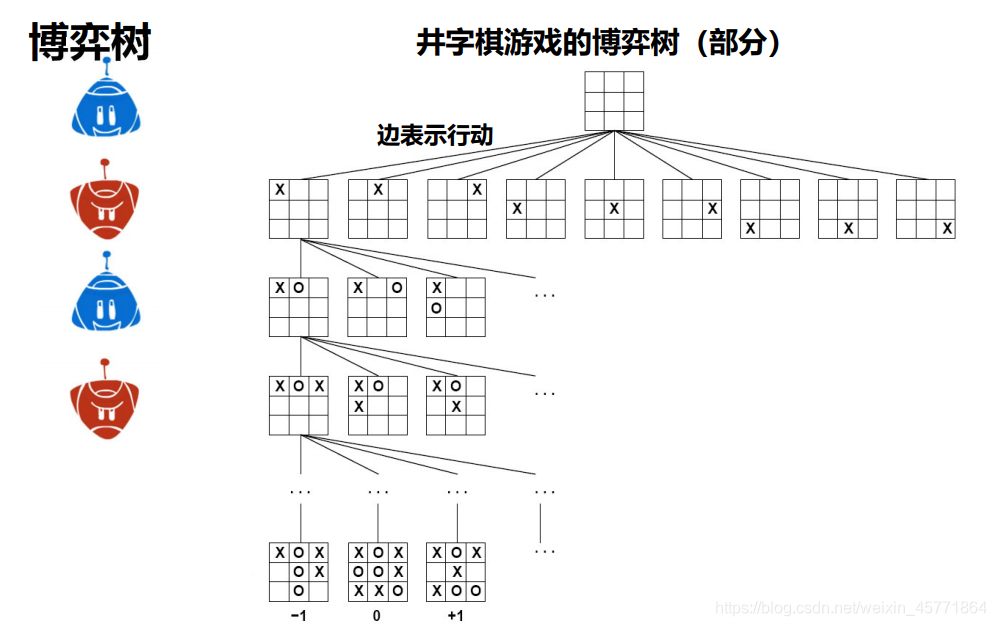
有了这样一棵博弈树之后,有没什么方法找到最优解呢?
我们介绍三种常见算法: Minimax算法(极小极大值算法)、α-β剪枝、 蒙特卡罗树搜索算法
Minimax(极小极大值算法) —— 冷酷的“上帝”

在网上查阅资料,别人用 冷酷的“上帝” 来形容 minimax 算法实在是太贴切了,将所有的可能下法全部枚举出来,导致游戏最终变成了只能靠猜先来赢的游戏 (猜先,围棋术语。是围棋比赛中用来决定双方谁先行子的方法)
Minimax也被称作一种悲观算法,即假设对手每一步都会将我方引入从当前看理论上价值最小的格局方向,即对手具有完美决策能力。因此我方的策略应该是选择那些对方所能达到的让我方最差情况中最好的,也就是让对方在完美决策下所对我造成的损失最小
Minimax不找理论最优解,因为理论最优解往往依赖于对手是否足够愚蠢,Minimax中我方完全掌握主动,如果对方每一步决策都是完美的,则我方可以达到预计的最小损失格局,如果对方没有走出完美决策,则我方可能达到比预计的最悲观情况更好的结局。总之我方就是要在最坏情况中选择最好的
在此推荐一个Minimax算法的模拟网站,可以自己试试添加节点和值: Minimax Simulator
简单总结下: Minimax算法 是由 min-value() 和 max-value() 互相调用来实现,最终搜索到终盘得出结果
Game tree 的大小主要由两个数字决定:
- 分支因子b: 代表了游戏典型的每步走棋的可行(合法)走法
- 特征深度m: 游戏典型的走棋步数/深度
很容易得出,一个游戏的 Game tree 的大小,约为 bm
算法分析:
- 搜索方法: 类似DFS
- 时间复杂度: O(bm)
- 空间复杂度: O(bm)
只要是一个不太 toy 的游戏, bm 都是一个天文数字。例如对于围棋而言,这个数字超过了可观测宇宙中的原子数
当 Game tree 过于庞大,使得我们难以枚举树上的所有结点,进而难以达到“完美”的境界,这就迫使我们进行改进 Minimax
减少特征深度m方法有:
- 函数近似。我们构造一个所谓的估值函数(evaluation function),它的目的是估计某个局面的 Minimax 评分,这样我们我们就不用搜索到终盘才能得知结果。一般而言,越接近终盘估计会越准确(因为游戏往往越到残局越简单),所以估值函数不能完全替代搜索
- 模拟估计。我们可以从某个局面开始,使用一个相对简单的对弈系统(如果和主程序一样复杂就没有意义了),快速下到终局,用得到的结果作为这个局面的 Minimax 评分的近似。显然这个方法也往往越到终盘越准确。此方法又称为 rollout
- 上面两种方法的混合,比如两个的结果加权平均。这是 AlphaGo-Fan 和 AlphaGo-Lee使用的方式
可以看出,减少特征深度 m 的核心思想就是直接近似得到某个盘面 Minimax 评分,而不是依赖后续的搜索,以截断 Minimax 的搜索深度
而减少分支因子b的方法有:
- 剪枝。剪枝就是去除掉某些明显劣势的走法,最著名的便是 Alpha-beta 剪枝。它充分利用了 Minimax 算法的特点,并且仍然可以得到和 Minimax相同的结果(也就是不是近似),是首选的优化
- 采样估计。其思路是蒙特卡洛(monte-carlo)模拟。我们可以先预估出一个先验概率分布 P,然后再根据 P 采样部分路径用作估计。这种手段对分支因子的减少比较激进,在围棋等分支因子较大的棋类中较常用。Alpha系列采用的就是此类方法
α-β剪枝
Alpha-beta剪枝是一种找到最佳minimax步骤的方法,同时可以避免搜索不可能被选择的步骤的子树
Alpha-beta剪枝的名称源于搜索过程中传递的两个边界参数,这些边界基于已经看到的搜索树部分来限制候选步骤
- Alpha是可能步骤的最大下界
- Beta是可能步骤的最小上界
- 任何新结点被认为是步骤的可能路径结点当且仅当 α ≤ value ≤ β
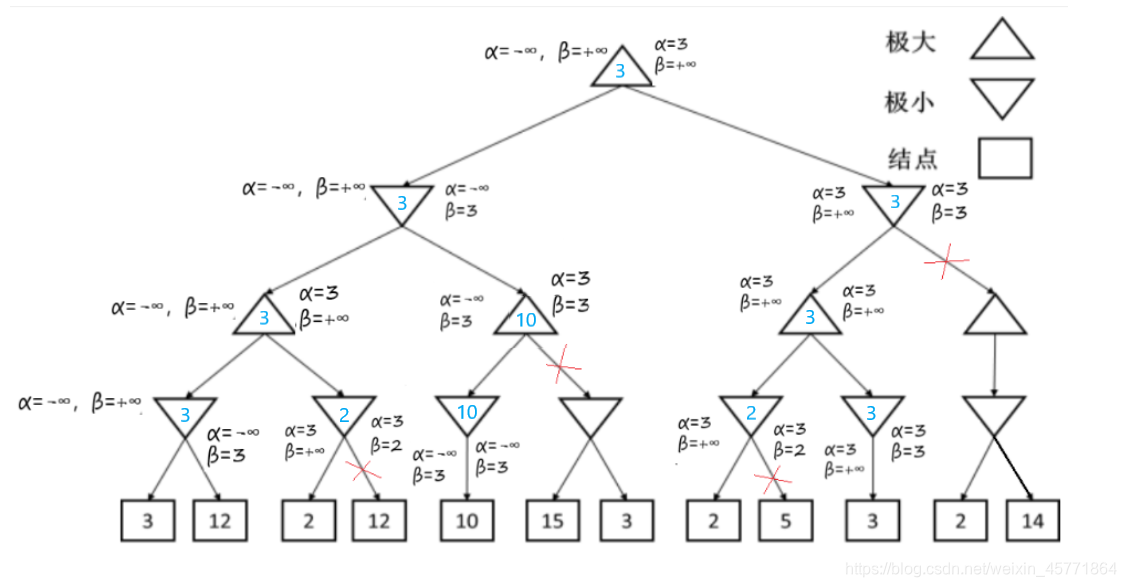
蒙特卡罗树搜索算法
Pac-Man #1 反射体
前面的知识铺垫完后,接下来看看实验的问题一
吃豆人实验第一题是写一个简单的Reflex Agent,这一问在默认情况下并没有墙壁以及只有一只幽灵(但我接下来是按照多个幽灵的情况来说明)
我们的任务很简单: 1) 吃完图中的所有豆子; 2) 躲避幽灵的追击; 3) 尽可能地得高分
针对1):
要吃完所有的豆子,即要写出吃豆人该怎么走才能吃完豆子的代码,看了代码就知道,这个我们不需要管,因为 getAction() 这个函数已经很完善了,getAction() 的大致思路就是: 获得后继所有的合法动作 (若右边有墙,则右边就不是个合法的动作),对这些合法的动作进行评估 (简单解释就是,评估值相当于考试得分,对每一个合法动作进行算分,得分越高越好) ,选出评估值最高的合法动作作为吃豆人下一步要走的动作 (比如说算出走右边评估值最高,那么吃豆人下一步就会走右边),如果有同样分数的评估值,那么在这几个合作动作中随机选择一个即可。而我们第一问的主要目标就是写评估函数这一块,即对合法动作进行评估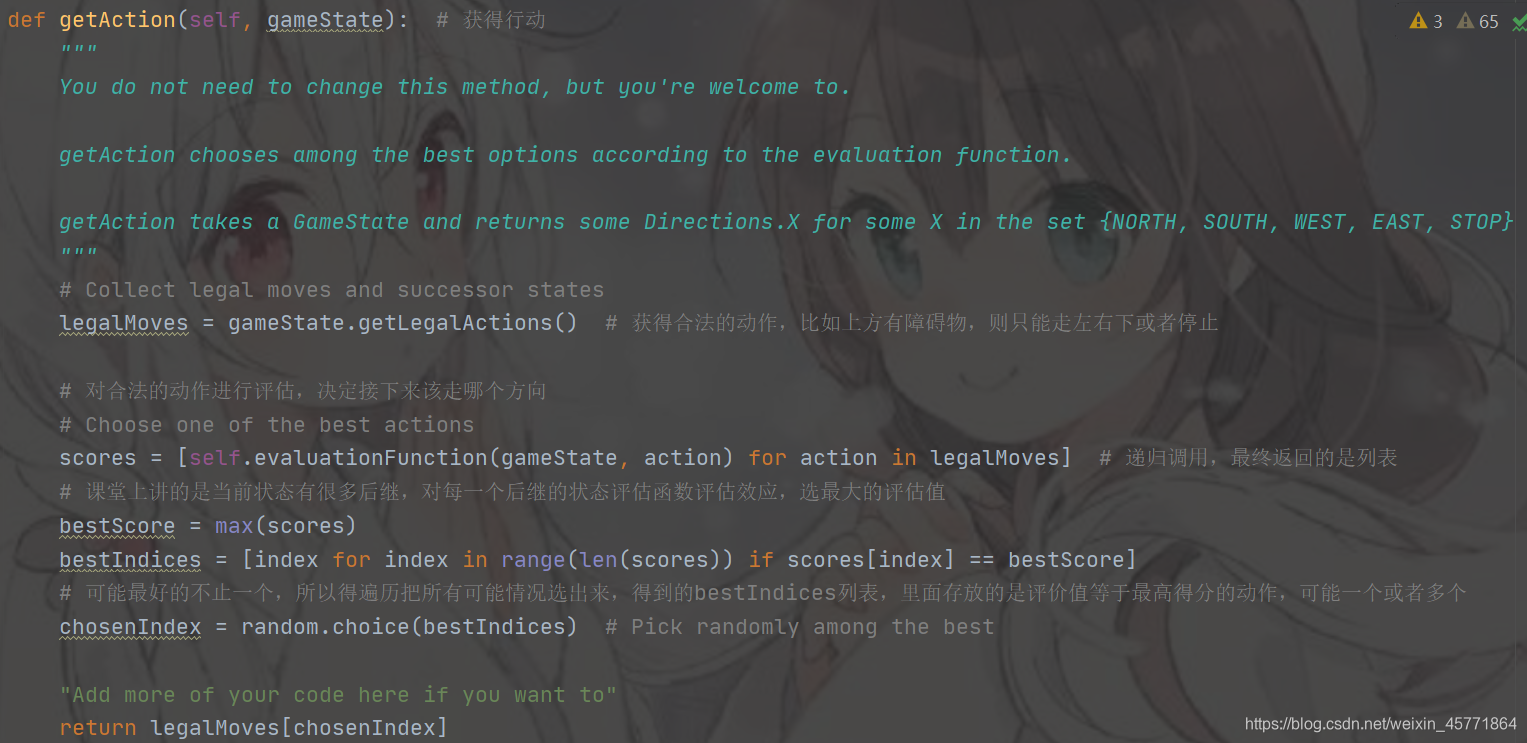
针对2):
既然要躲避幽灵的追击,首先我们得知道幽灵的位置,以及它距离吃豆人的位置,即也要知道吃豆人的位置,然后算两点间距离,这里用的是曼哈顿距离。
newPos = successorGameState.getPacmanPosition() # 获取当前吃豆人的位置
GhostPos = successorGameState.getGhostPositions() # 获取幽灵的位置
x_pacman, y_pacman = newPos # 当前吃豆人x,y坐标
# 幽灵可能不止一个,真正造成威胁的是离吃豆人最近的一个幽灵,所以获取其离吃豆人的距离
dist = min([(abs(each[0] - x_pacman) + abs(each[1] - y_pacman)) for each in GhostPos])
好了,知道了距离,接下来是如何根据距离的远近来判断评估值大小,我们先来看一下代码中对于评估值函数的解释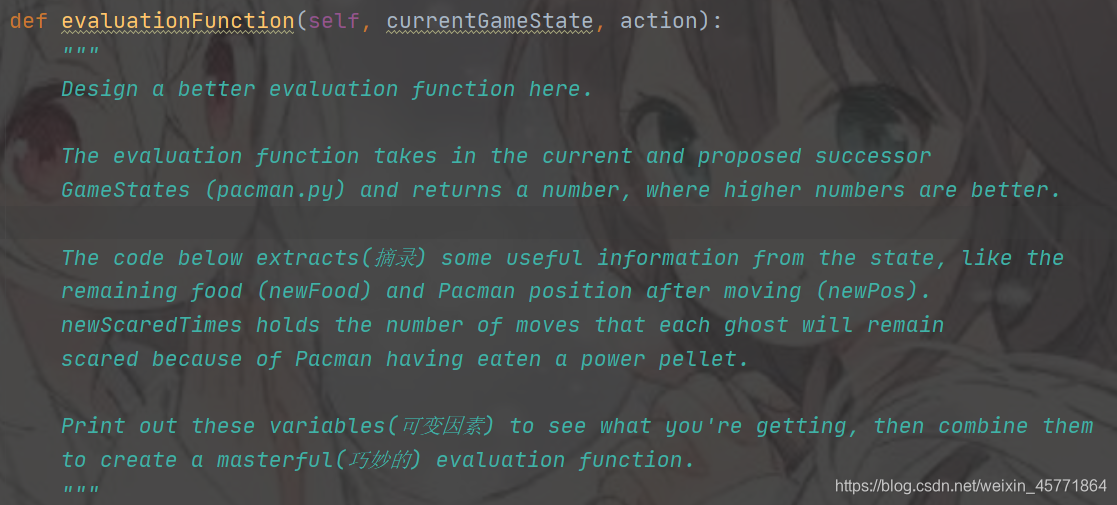
食物对于吃豆人来说是正反馈,但幽灵对于吃豆人来说是负反馈,所以我用正数表示食物带来的的正反馈(相当于考试的加分),用负数表示鬼怪带来的的负反馈(相当于考试的扣分),我们知道幽灵距离吃豆人越近越危险,那该怎样用距离来量化幽灵带给吃豆人的危险程度以及该如何量化食物对于吃豆人的正反馈大小?
还有一点需要强调的是这个评估函数是对吃豆人下一个合法动作的评估,脑瓜子想想都清楚,我们是要远离幽灵和吃豆子,也就是要决定下一步应该是走上下左右的哪一个方向,这就需要我们提前预判下一步是否距离幽灵足够远,以及下一步是否有食物,所以评估的是下一个动作。如果是评估当前动作得到一个评估值,有什么用,走都走到这了。
首先我们已经算出了吃豆人与最近那个幽灵距离,当距离很大时,就不需要考虑幽灵的危险了,只需要一心一意地吃豆子,这里我设置当距离 < 4 的时候才考虑幽灵的负反馈,当然你也可以设置 < 2 的时候才考虑,最后会发现在这一问中 < 2 也可以达到躲避幽灵的目的,但如果有墙这些地形影响,就难免会被逼入死胡同,然后gameover,第一问没有障碍物,所以先不讨论
if dist != 0 and dist < 4: # 计算鬼怪给吃豆人带来的负反馈,当吃豆人与幽灵距离小于4的时候才考虑负反馈
ghostScore = -11 / dist
else:
ghostScore = 0
ghostScore就是评估幽灵给吃豆人带来的负反馈,负数大家应该都很好理解,但为什么是11,而且为何是除以距离?
不难发现这是个分式,即当距离越小,ghostScore的绝对值就会越大,对于分数的影响更大,也就是扣的分越多,这样子分数就会越低,而我们要得高分,所以就会往扣分越少的方向走,即距离幽灵越远的方向,这样子dist很大,整个分式的绝对值越小,扣的分越少,就达到了远离幽灵的目的
举个例子,假设下一步是向左移一格,假设计算出与幽灵的距离为 dist = 1,那么算出 ghostScore = -11。如果不是走左边,而是走右边,假设计算出与幽灵的距离 dist = 2,计算出 ghostScore = -5.5,假设最初的得分是20,加上ghostScore,最终分数分别为9和14.5,我们要得分越高越好,所以就会选择走右边,这就达到了远离幽灵的目的
11这个值可以修改,但得根据食物的启发值来修改,所以现在来说食物对吃豆人的影响
针对3):
吃豆人如果在不被幽灵吃掉的前提下把豆子吃完所耗费时间越短,那分数就会更高,而且我们知道测试中食物是分散的,如果漫无目的地寻找食物,会很费时,得分就会低,所以我们让吃豆人优先吃距离最近的豆子,即得求出距离当前位置最近的食物的位置
可能有人问,为什么评估值会与时间有关?
答案就在 generatePacmanSuccessor() 里
successorGameState = currentGameState.generatePacmanSuccessor(action) # 产生动作对应的状态


所以现在目标是求出距离当前位置最近的食物的位置,并算出食物的启发值
看过代码的都会知道别人已经帮我们写好了获取食物分布的代码,我们只需调用即可
newFood = successorGameState.getFood() # 获取当前状态食物的分布
按着 ctrl,点击 getFood() 来查看这个函数的返回值是什么,也可以自己打印出newFood查看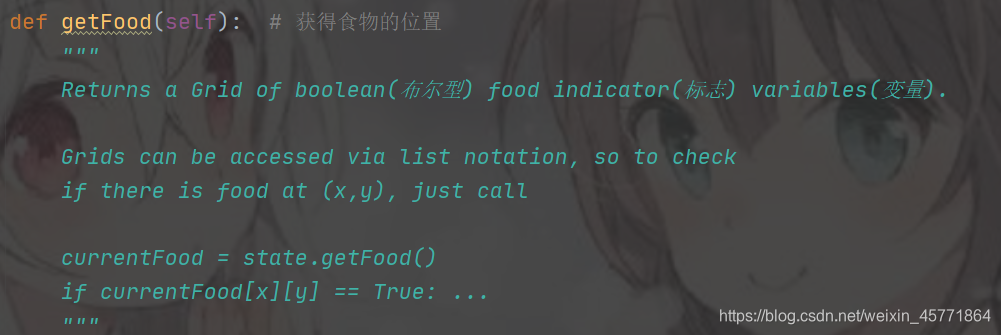
可以看到返回的是布尔类型。所以我们可以暴力枚举查看某一点的 if newFood[i][j] == True 来判断该点是否有食物
aroundfood = [] # 存放的是点坐标,表示该点有食物
Width = newFood.width
Height = newFood.height
# print('The width of grid: ', Width, ', the height of grid: ', Height)
# 针对openClassic的测试 --> The width of grid: 25 , the height of grid: 9
# 针对testClassic的测试 --> The width of grid: 5 , the height of grid: 10
for i in range(Width):
for j in range(Height):
if newFood[i][j]: # 表示该点有食物
aroundfood.append((i, j))
下面就是写出食物的启发值:
if dist >= 2 and len(aroundfood) > 0: # 周围有豆子
# 求出与吃豆人最近的食物距离
nearestFood = min([(abs(each[0] - x_pacman) + abs(each[1] - y_pacman)) for each in aroundfood])
foodScore = 10 / nearestFood # 离食物越远值越小
else:
foodScore = 0
因为食物带来的是正反馈,所以为正值,为何用分式,理由与前面的ghostScore一样,这里我设置的是10,所以食物计算的启发值总是不超过10,所以我设置ghostScore为 -11,比+10对结果带来的影响更大,当 foodScore 和 ghostScore 相加为负数时,就可以抵消食物对吃豆人的诱惑,起到让吃豆人远离幽灵的作用 (举个例子,吃豆人右边那个格子上有豆子,还有幽灵,也就是说食物与吃豆人距离为1,幽灵与吃豆人的距离也为1,算出 foodScore 为10,ghostScore为-11,两者相加为-1,也就是说吃豆人往右边走,不仅没得分,反而还扣分,是个傻子都知道不会走右边)
并且这里我在if条件判断中多添加了一个语句,当吃豆人与幽灵的距离 dist >= 2 的时候才考虑食物带来的正反馈,如果 dist < 2 吃豆人将一心躲避幽灵
最后把全部启发值加起来就是评估值
originalScore = successorGameState.getScore() # 获取此时的分数
# 把计算好的各种启发值加在游戏得分上,就能得到下一个合法动作的评估值
return originalScore + foodScore + ghostScore # 返回评估值
当然如果想要让吃豆人80%的精力吃豆子,20%的精力用来躲避幽灵,只要设置百分比即可
到这 evaluationFunction() 函数的代码就基本实现了
openClassic用暴力枚举测试结果
运行了100次,平均得分: 1223.45,正确率: 100%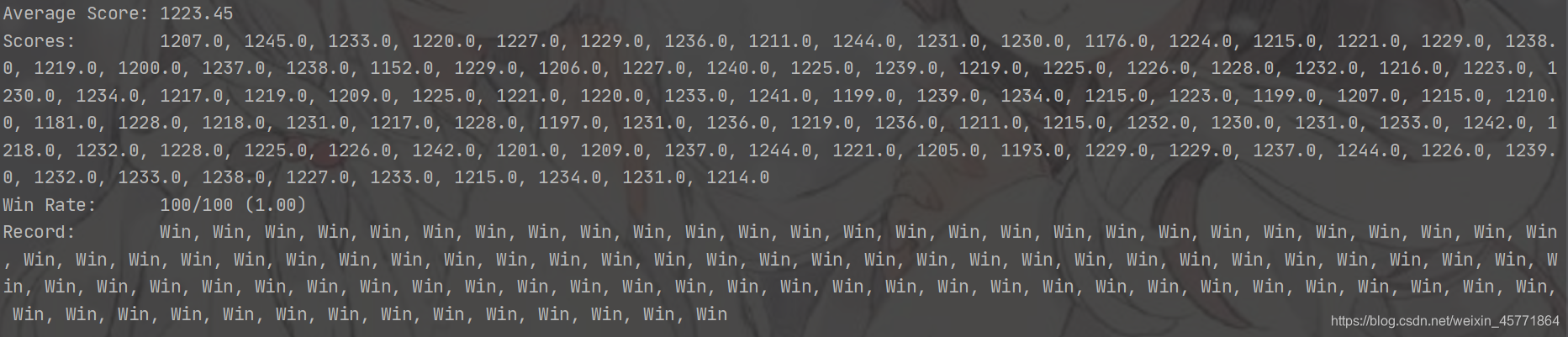
[补充] 在获取最近食物的点坐标那里,我想应该也可以用 DFS,BFS 来实现,毕竟grid有边界,遍历搜索就行了
BFS 常用于找单一的最短路线,它的特点是 "搜到就是最优解"
而 DFS 用于找所有解的问题,它找到的不一定是最优解,必须记录并完成整个搜索
故一般情况下,深搜需要非常高效的剪枝
BFS代码:
# 搜索距离吃豆人最近的豆子的第二种实现方式: 'BFS'
nearestFood = float('inf') # 设为无穷大
if dist >= 2: # 如果吃豆人距离幽灵大于等于2
# 右下左上
dx = [1, 0, -1, 0]
dy = [0, 1, 0, -1]
List = [] # 用列表模拟队列
d = {} # 用来标记某一状态是否之前遍历过
List.append(newPos)
d.update({(x_pacman, y_pacman): 1})
while List:
temp = List[0]
List.pop(0)
tx, ty = temp
if newFood[tx][ty]:
nearestFood = min(nearestFood, (abs(tx - x_pacman) + abs(ty - y_pacman)))
break
for i in range(len(dx)):
x = tx + dx[i]
y = ty + dy[i]
if 0 <= x < Width and 0 <= y < Height: # 判断该点是否出界
temp = (x, y)
if temp not in d: # 之前没有遍历过的状态,就添加到队列末尾
d[temp] = 1
List.append(temp)
if nearestFood != float('inf'):
foodScore = 10 / nearestFood
else:
foodScore = 0
代码很简单,就是在BFS模板稍作修改即可,和八数码的思想很像,不懂八数码的,可以看我的另一篇博客 无信息搜索模板题
这里就大致描述下BFS的过程:
首先 nearestFood (nearestFood用来存储距离吃豆人最近的食物距离,当然也可以存储点坐标) 设置为无穷大。在python中我们可以用列表来模拟队列,只要遵循 “队列先进先出” 的性质即可。
将最初状态入队。判断队列是否为空,如果不为空,则pop出队首结点,先判断该结点是否有食物,如果有食物,则计算出与吃豆人的距离并与nearestFood进行比较,如果值比nearestFood还小,就更新nearestFood (不用看,肯定比nearestFood要小,毕竟nearestFood初始值设为无穷大)
搜到了一个解,这时候就可以退出了,这就是BFS性质,它与DFS搜索不同,DFS是每一种情况都遍历一遍,才给出结果,而BFS搜到就是最优解。
如果该位置没有食物,就开始对该结点进行拓展(就是将它的孩子结点入队,这里孩子结点就是该位置的上下左右位置)
我们需要判断该位置的上下左右的位置是否在界内,如果在界内则判断是否之前访问过,如果没访问过就添加进队列中,重复该过程…
这里可能会有疑问: 找最近食物点是否真的搜到就是最优解?
这里推荐一个网址,可以将搜索算法进行可视化:
https://www.redblobgames.com/pathfinding/a-star/introduction.html
openClassic用BFS测试结果
运行了100次,平均得分: 1226.74,正确率: 100%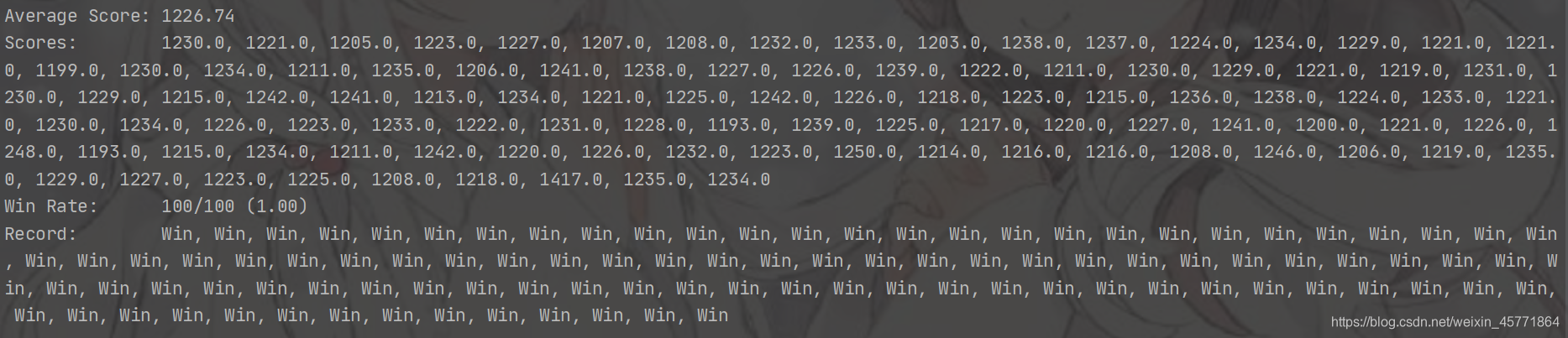
Pac-Man #2 Minimax
前面已经介绍了Minimax算法,现在开始做题,先看下getAction()函数中给我们的提示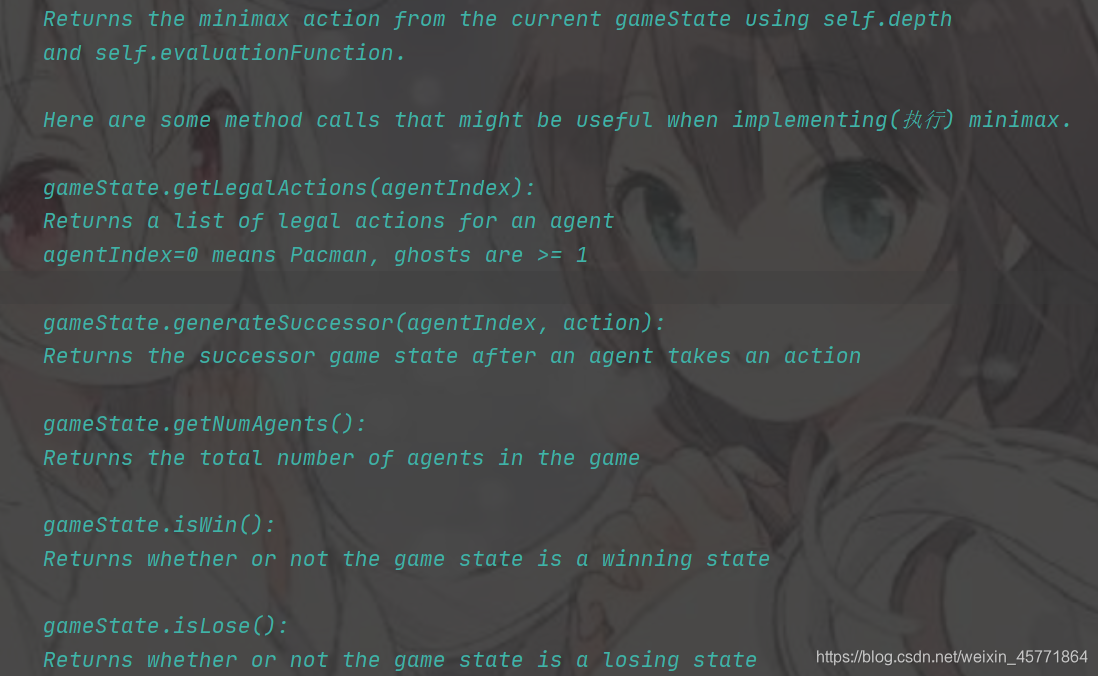
由注释可以得出哪些信息:
- 看到 self.depth and self.evaluationFunction 就可以知道 game tree 规模过于庞大,无法枚举树上的所有结点。self.depth是用来结束 min-value() 和 max-value() 互相递归的调用,self.evaluationFunction() 用来评估得分
- isWin() 和 isLose() 肯定是用来结束递归的调用
根据得到的信息,可以写出个大概的模型,这里我们把 min-value() 和 max-value() 合并成一个函数来写 - 题目2有一个注意事项: 单个搜索层被定义为包含吃豆人单次移动和所有幽灵的反应。因此深度为2的搜索将包含吃豆人和各个幽灵各两次的移动,所以深度需要 × 2,当然如果你之前有看过其他人的博客,可能会发现有些博客没 有x 2,有些却有 x 2,这里需不需要 x 2 得根据代码而定,后面我代码中注释有讲解
def minimax(self, agentIndex, gameState, Depth):
# agentIndex == 0 表示吃豆人,>= 1 表示幽灵,gameState 表示当前状态,depth表示深度
# 如果超过了限制的深度,或者已经输了或者赢了,就可以直接返回评估值
if Depth >= self.depth * 2 or gameState.isWin() or gameState.isLose():
return self.evaluationFunction(gameState) # minimax() 函数返回的是评估值
if agentIndex == 0: # 吃豆人
MAX = float("-inf") # 初始化MAX为负无穷
...
return MAX
else: # 幽灵
MIN = float("inf") # 初始化MIN为正无穷
...
return MIN
- getLegalActions(agentIndex) 传入的参数 agentIndex = 0 表示吃豆人,>= 1 表示幽灵,表明不止一只幽灵,当然也可以从提示中的 getNumAgents() 这个函数名得出该结论 (getNumAgents() – 获取Agents的数目,如果就一个吃豆人和一个幽灵,需要这个函数干嘛,所以幽灵肯定不止一个) 。getLegalActions() 最后返回的是列表的形式的合法动作
- generateSuccessor() 对每一个合法的动作生成对应的状态,那肯定是搭配 getLegalActions(agentIndex)来使用。又 getLegalActions(agentIndex) 返回的是列表,所以要用一个for loop 来遍历每一个合法动作,然后对这些合法动作生成相应的状态
if agentIndex == 0: # 吃豆人
MAX = float("-inf") # 初始化MAX为负无穷
pacmanActions = gameState.getLegalActions(agentIndex) # 获取吃豆人合法的动作
for each_action in pacmanActions:
successor_state = gameState.generateSuccessor(agentIndex, each_action) # 对每一个合法的动作生成对应的状态
value = self.minimax(1, successor_state, Depth + 1) # 下一轮是到幽灵开始行动
MAX = max(MAX, value)
return MAX
else: # 幽灵
values = []
MIN = float("inf") # 初始化MIN为正无穷
ghostActions = gameState.getLegalActions(agentIndex)
for each_action in ghostActions:
successor_state = gameState.generateSuccessor(agentIndex, each_action)
if agentIndex >= gameState.getNumAgents() - 1: # 遍历完幽灵才到吃豆人环节
values.append(self.minimax(0, successor_state, Depth + 1))
# 这里我Depth有+1,如果这里没有+1,那么整个代码只有if判断语句中Depth有+1,那么就不用x2,自己领悟一下
else: # >= 1代表幽灵,因为不止一只幽灵,这里是个坑点
values.append(self.minimax(agentIndex + 1, successor_state, Depth)) # 这里得注意代入递归函数的Depth不加1
value = min(values)
MIN = min(MIN, value)
return MIN
- 从前面那张提示的截图就可以知道我们最终返回的是 the minimax action 这个动作,而不是单单的评估值,当然从函数名 def getAction() 这个函数名也能得出该结论 (
不会有人不知道getAction的中文意思吧) 。通过代码我们知道 minimax() 返回的是评估值,所以我们需要根据每一个合法动作的评估值来判断下一步要走哪里
def getAction(self, gameState):
bestaction = "stop"
maxvalue = float('-inf')
# 遍历所有可行的下一步,取效用最佳的action作为best_action
for each_action in gameState.getLegalPacmanActions():
successor_state = gameState.generateSuccessor(0, each_action)
value = self.minimax(agentIndex=0, gameState=successor_state, Depth=0)
if value is not None and maxvalue < value:
maxvalue = value
bestaction = each_action
return bestaction # 最后返回最佳的合法动作
minimaxClassic实验结果
运行了100次,平均得分: 334.38,正确率: 82%
如果你运行了 openClassic 或者是默认的 mediumClassic 的更大的游戏空间里,你会发现吃豆人很难死亡,但也很难取胜。智能体常常会在一个区域翻来覆去,没有进展。智能体甚至有可能在一个点周围翻来覆去,但不吃那个点,因为它不知道吃掉那个点之后要怎么走
如果运行 trappedClassic 你还会发现吃豆人有一定的“自杀倾向”,当吃豆人发现它将不可避免地死亡时,它会尝试尽快结束游戏因为不断的存活罚分,有时候,这个是跟随机幽灵有关的错误做法,有可能有一定的生机,但 Minimax智能体 会毫不犹豫地"自杀",因为它一直都假定最坏情况,这就是为什么我们说该算法是“悲观的”
Pac-Man #3 Alpha-Beta剪枝
Alpha-Beta代码其实就是在Minimax代码的基础上添加几行代码而已
def new_minimax(self, agentIndex, gameState, Depth, alpha, beta):
# agentIndex == 0 表示吃豆人,>= 1 表示幽灵,gameState 表示当前状态,depth表示深度
# 这里我没有×2,因为我幽灵那里的递归调用深度没有+1
if Depth >= self.depth or gameState.isWin() or gameState.isLose():
return self.evaluationFunction(gameState)
if agentIndex == 0: # 吃豆人
MAX = float("-inf") # 初始化MAX为负无穷
legal_actions = gameState.getLegalActions(agentIndex) # 获得当吃豆人所有合法的下一步动作
for each_action in legal_actions:
successor_state = gameState.generateSuccessor(agentIndex, each_action) # 对每一个合法的动作生成对应的状态
value = self.new_minimax(1, successor_state, Depth + 1, alpha, beta) # 下一轮是到幽灵开始行动
if value is not None:
MAX = max(MAX, value)
if MAX > beta: # α-β剪枝算法
return MAX
if MAX > alpha: # 更新α值
alpha = MAX
return MAX
else: # 幽灵
values = []
MIN = float("inf") # 初始化MIN为正无穷
legal_actions = gameState.getLegalActions(agentIndex)
for each_action in legal_actions:
successor_state = gameState.generateSuccessor(agentIndex, each_action)
values.append(self.new_minimax((agentIndex+1) % gameState.getNumAgents(), successor_state, Depth, alpha,beta))
if values is not None:
value = min(values)
MIN = min(MIN, value)
if MIN < alpha:
return MIN
# 按照α-β剪枝算法,这里需要更新β的值
if MIN < beta:
beta = MIN
return MIN
getAction代码
def getAction(self, gameState):
maxvalue = float('-inf')
bestaction = []
for each_action in gameState.getLegalPacmanActions():
alpha = float('-inf')
beta = float('inf')
# 求出后继状态的评估值,并和maxvalue比较,求出最大值
successor_state = gameState.generateSuccessor(0, each_action)
value = self.new_minimax(agentIndex=0, gameState=successor_state, Depth=0, alpha=alpha, beta=beta)
# 如果当前的value比maxvalue要大,则更新maxvalue,并记下bestaction
if maxvalue < value:
bestaction = [] # 将列表中元素置空
maxvalue = value
bestaction.append(each_action)
elif maxvalue == value:
bestaction.append(each_action)
if maxvalue > alpha: # 按照α-β剪枝算法,需要更新α值
alpha = maxvalue
return random.choice(bestaction) # 随机选择最优的合法动作
有个非常有意思的现象想要提一提,你运行代码可能会发现当幽灵不在吃豆人附近时,吃豆人时常会在原地不动,只有当幽灵来了才跑,原因是吃豆人不知道下一步该走哪,但至少动一下啊,咸鱼一样呆在原地会让人很捉急的,那该怎么办?
在game.py中我们可以看到有个Directions的类,里面有关于方向的定义,我们可以看到有一个STOP的定义
然后我们打开pacman.py,下面两张图第一张是PacmanRules,第二张是GhostsRules,Ghost的合法动作中有去除掉Stop操作,但是Pacman竟然没有
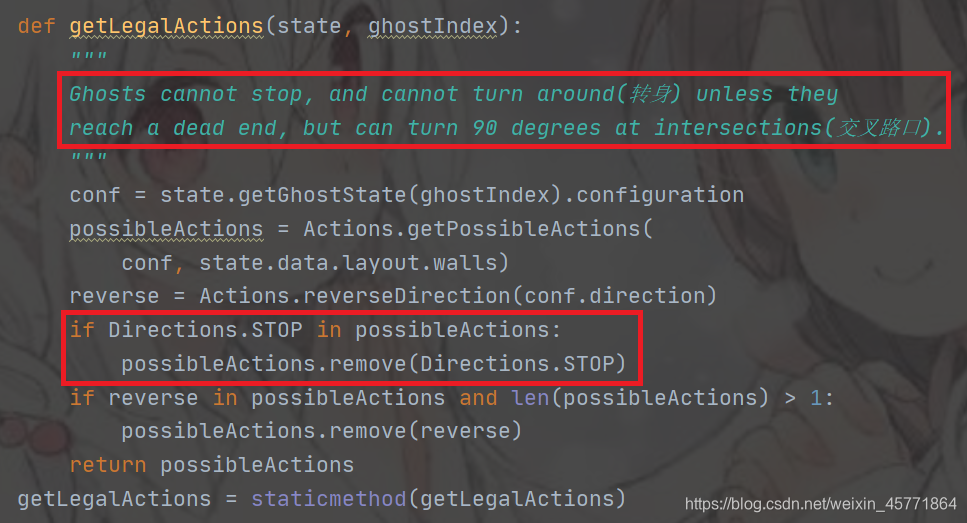
所以我们只需要getAction代码中添加两行即可
if each_action == 'Stop':
continue
Pac-Man #4 betterEvaluationFunction
第一问已经写过一个 EvaluationFunction 了,但相比于第一题,这次的难度变大了,因为要求得分更苛刻,需要1000分以上,而且还有墙壁障碍以及幽灵个数不再只是一个
食物的启发值和幽灵的启发值
思路跟之前的一样,用分式即可,这里有一点点不同的是,就是在考虑幽灵的启发值的时候,一开始我想的是跟之前一样,只考虑最近幽灵对于吃豆人的影响,但会出大问题,当吃豆人一心躲避最近幽灵的追击时,不关心另一只幽灵的走向的话,会不自觉地陷入两只幽灵夹击的情况,所以这里我是考虑了两只幽灵与吃豆人距离的和
# 计算食物的启发值
nearestFood = float('inf')
for food in newFoodList:
food_distance = util.manhattanDistance(newPos, food)
nearestFood = min(nearestFood, food_distance)
foodScore = 1 / float(nearestFood)
# 计算幽灵的启发值
distances_to_ghosts = 1
for ghost_state in currentGameState.getGhostPositions():
ghost_distance = util.manhattanDistance(newPos, ghost_state)
distances_to_ghosts += ghost_distance
ghostScore = 1 / float(distances_to_ghosts)
return currentGameState.getScore() + foodScore - ghostScore + ...
注意
值得一提的是 betterEvaluationFunction 考虑的是当前状态,不是对后来动作的评价, 前面我说过走都走到这了,对当前状态评价有什么用。所以我自己当时也是很疑惑
而且如果你有打印 ghost_distance 看的话
print(ghost_distance)
你会发现 ghost_distance == 0 的情况经常出现,当 ghost_distance == 0 不就是幽灵和吃豆人在同一个位置吗,但游戏界面中吃豆人和幽灵却没有在同一个位置,游戏仍旧继续进行,这是为什么?
后来我想了想,因为 betterEvaluationFunction 是用于 Alpha-Beta 中,而 Alpha-Beta 是 Gametree 向下推演几层,当depth大于限制深度时才执行评价函数,所以评价的是几步后的状态,那个时候 ghost_distance == 0 是有可能出现的
胶囊启发值
我们会发现如果仅仅只是把地图中的所有豆子吃完,分数也超不过1000分,所以这时候得考虑吃胶囊,因为吃胶囊可以让幽灵处于恐惧状态,吃掉幽灵可以加分,所以接下来是讨论胶囊的启发值
一开始我的想法是胶囊对于吃豆人来说是正反馈,那思路就跟食物启发值一样,先计算吃豆人与胶囊的距离,然后用分式的形式,当然为了区别于食物,把胶囊的权重设大一些
可能会问为什么要把胶囊权重设的比食物要大?
因为如果胶囊的启发值和食物一样,当幽灵来的时候,吃豆人只会去躲避幽灵,不会想到去吃胶囊让幽灵变成恐惧状态。把胶囊权重设大一些,就可以抵消幽灵对于吃豆人的消极影响
当然,是达到了预期: 吃豆人会去吃胶囊,但是迎来了新的问题,就是吃豆人会直奔胶囊而去。吃胶囊的目的是什么,是为了让幽灵处于恐惧状态,然后可以吃掉幽灵得高分,所以胶囊的正确用途就是,幽灵追杀吃豆人,然后吃豆人吃掉胶囊完成反杀。但问题是吃豆人不管幽灵是否在自己身边,直奔胶囊,吃完胶囊幽灵变成恐惧状态,但吃豆人距离幽灵很远,等跑到幽灵那里幽灵都已经回复到正常状态了,那胶囊就没有发挥到它的真正用途
为什么吃豆人会直奔胶囊而去?
因为胶囊启发值是基于吃豆人与胶囊的距离,距离越近,得分越高。这会驱使吃豆人往胶囊位置跑,所以就出现了吃豆人直奔胶囊而去的现象
一种解决方法便是,把胶囊当作豆子来处理,也就是计入 foodScore 里面,当然为了区别于豆子,权重依旧是要设大一些。一般情况下豆子离吃豆人肯定更近一些,所以豆子对于吃豆人的诱惑会大于胶囊(前提是胶囊的权重不要设置太大),只有当胶囊距离吃豆人很近的时候,胶囊对于吃豆人的诱惑才会大于豆子
newCapsule = currentGameState.getCapsules()
foodScore = float('-inf')
nearfood = [util.manhattanDistance(newPos, food) for food in newFood]
for capsule in newCapsule:
nearfood.append(util.manhattanDistance(newPos, capsule) / 1.1) # 胶囊的权重
# print(nearfood)
for each in nearfood:
foodScore = max(foodScore, 1 / float(each))
return currentGameState.getScore() + foodScore - ghostScore + ...
也可以把胶囊个数当作胶囊的启发值
newCapsule = currentGameState.getCapsules() # 获取胶囊信息
numberOfCapsules = len(newCapsule) # 计算胶囊的个数
return currentGameState.getScore() + foodScore - ghostScore - numberOfCapsules + ...
最后,为了减少吃豆人被包抄的情况出现,可以多加一个启发值 proximity_to_ghosts
proximity_to_ghosts = 0
for ghost_state in currentGameState.getGhostPositions():
ghost_distance = util.manhattanDistance(newPos, ghost_state)
if ghost_distance <= 3:
proximity_to_ghosts += 1
return currentGameState.getScore() + foodScore - ghostScore - proximity_to_ghosts - numberOfCapsules
实验结果
运行命令python pacman.py -p AlphaBetaAgent -a depth=3 -l smallClassic -k 1 -q -n 10

运行命令python pacman.py -p AlphaBetaAgent -a depth=3 -l smallClassic -k 1 -g DirectionalGhost -q -n 10
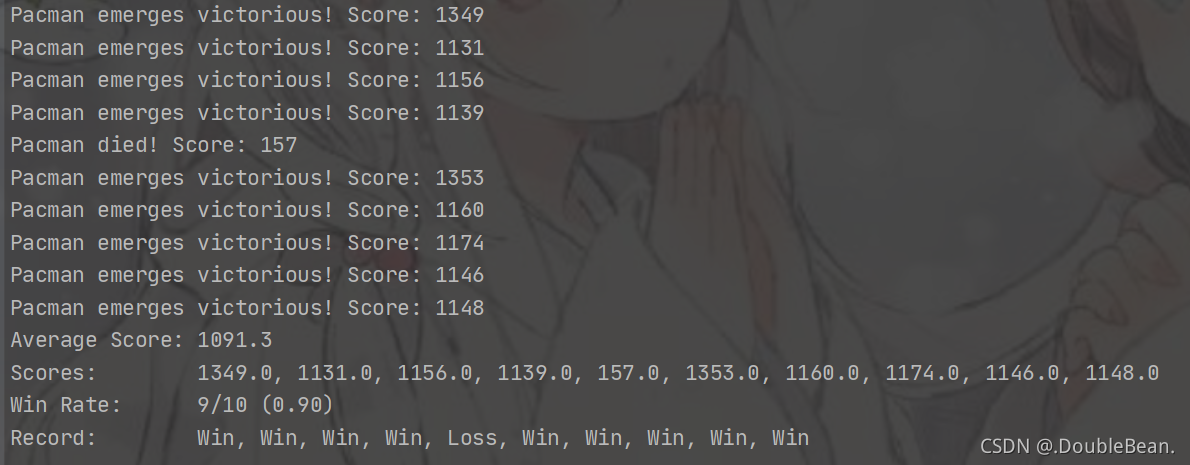
资源下载
https://download.csdn.net/download/weixin_45771864/20353542
总结
吃豆人游戏的代码应该没有所谓的标准答案一说,所以我的代码也不一定是对的,你只要按照自己的思路来写就行,合理即可
全部代码我放到了我的资源那里…
参考资料:
(我的博客在最开始的知识点概念讲解有很多都是直接复制粘贴别人的博客)
https://www.jianshu.com/p/f48e0191c2ee
https://blog.csdn.net/Pericles_HAT/article/details/116901139
https://www.bilibili.com/video/BV1Bf4y11758?share_source=copy_web
https://zhuanlan.zhihu.com/p/31809930?utm_source=wechat_timeline
https://github.com/iamjagdeesh/Artificial-Intelligence-Pac-Man

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 59
59 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)