
如何使用python实现一个优雅的词云?(超详细)
什么是词云“词云”就是对网络文本中出现频率较高的“关键词”予以视觉上的突出,形成“关键词云层”或“关键词渲染”。从而过滤掉大量的文本信息,使浏览网页者只要一眼扫过文本就可以领略文本的主旨。在网络上,我们经常可以看到一张图片,上面只有一堆大小不一的文字,有些通过文字生成一个人物的轮廓。像这样的图像,我们称之为词云。词云”就是数据可视化的一种形式。给出一段文本的关键词,根据关键词的出现频率而生成的一幅
什么是词云
“词云”就是对网络文本中出现频率较高的“关键词”予以视觉上的突出,形成“关键词云层”或“关键词渲染”。
从而过滤掉大量的文本信息,使浏览网页者只要一眼扫过文本就可以领略文本的主旨。
在网络上,我们经常可以看到一张图片,上面只有一堆大小不一的文字,有些通过文字生成一个人物的轮廓。像这样的图像,我们称之为词云。
词云”就是数据可视化的一种形式。给出一段文本的关键词,根据关键词的出现频率而生成的一幅图像,人们只要扫一眼就能够明白文章主旨。



jieba
"结巴"中文分词:做最好的Python中文分词组件 "Jieba"
安装
pip install jieba

jieba的分词模式
支持三种分词模式:
这里我就以昨日爬取微博鸿星尔克的评论为测试内容。
“网友:我差点以为你要倒闭了!”鸿星尔克捐款5000w后被网友微博评论笑哭...
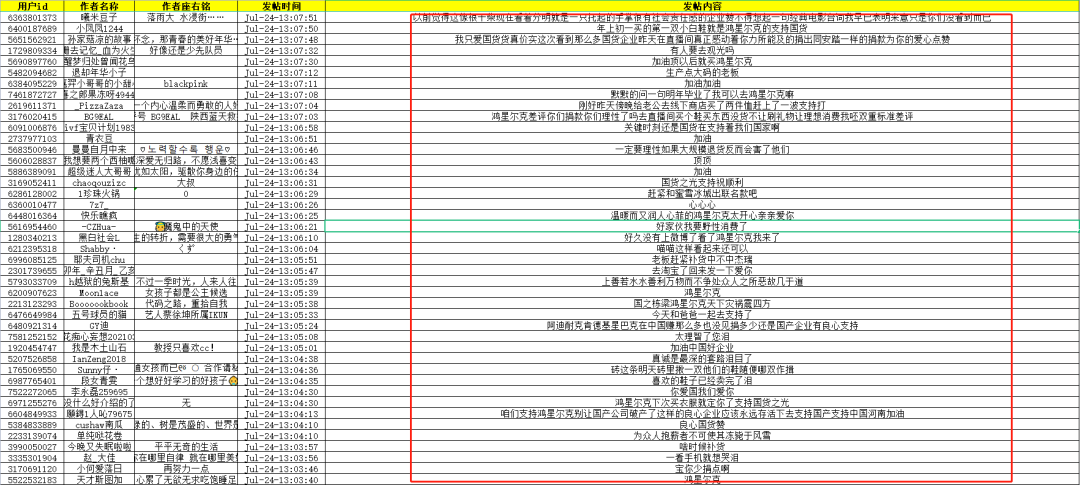
精确模式,试图将句子最精确地切开,适合文本分析;
它可以将结果十分精确分开,不存在多余的词。
常用函数:cut(str)、lcut(str)
import pandas as pd
import jieba
# 读取文件
pd_data = pd.read_excel('鸿星尔克.xlsx')
# 读取内容
text = pd_data['发帖内容'].tolist()
# 切割分词
wordlist = jieba.cut(''.join(text))
result = ' '.join(wordlist)
print(result)
全模式,它可以将结果全部展现,也就是一段话可以拆分进行组合的可能它都给列举出来了
把句子中所有的可以成词的词语都扫描出来, 速度非常快
常用函数:lcut(str,cut_all=True) 、 cut(str,cut_all=True)
import pandas as pd
import jieba
# 读取文件
pd_data = pd.read_excel('鸿星尔克.xlsx')
# 读取内容
text = pd_data['发帖内容'].tolist()
# 切割分词
wordlist = jieba.lcut(''.join(text), cut_all = True)
result = ' '.join(wordlist)
print(result)

搜索引擎模式,在精确模式的基础上,对长词再次切分
它的妙处在于它可以将全模式的所有可能再次进行一个重组
常用函数:lcut_for_search(str) 、cut_for_search(str)
import pandas as pd
import jieba
# 读取文件
pd_data = pd.read_excel('鸿星尔克.xlsx')
# 读取内容
text = pd_data['发帖内容'].tolist()
# 切割分词
wordlist = jieba.lcut_for_search(''.join(text))
result = ' '.join(wordlist)
print(result)

处理停用词
在有时候我们处理大篇幅文章时,可能用不到每个词,需要将一些词过滤掉
这个时候我们需要处理掉这些词,比如我们比较熟悉的‘你’ ‘了’、 ‘我’、'的' 什么的
import pandas as pd
import jieba
from stylecloud import gen_stylecloud
# 读取文件
pd_data = pd.read_excel('鸿星尔克.xlsx')
# 读取内容
text = pd_data['发帖内容'].tolist()
# 切割分词
wordlist = jieba.lcut_for_search(''.join(text))
result = ' '.join(wordlist)
# 设置停用词
stop_words = ['你', '我', '的', '了', '们']
ciyun_words = ''
# 过滤后的词
for word in result:
if word not in stop_words:
ciyun_words += word
print(ciyun_words)
可以看到,我们成功去除了我们不需要的词 ‘你’ ‘了’、 ‘我’、'的' ,那么这到底是个什么骚操作呢?
其实很简单,就是将这些需要摒弃的词添加到列表中,然后我们遍历需要分词的文本,然后进行读取判断
如果遍历的文本中的某一项存在于列表中,我们便弃用它,然后将其它不包含的文本添加到字符串,这样生成的字符串就是最终的结果了。

权重分析
很多时候我们需要将关键词以出现的次数频率来排列,这个时候就需要进行权重分析了,这里提供了一个函数可以很方便我们进行分析,
jieba.analyse.extract_tags
import pandas as pd
import jieba.analyse
# 读取文件
pd_data = pd.read_excel('鸿星尔克.xlsx')
# 读取内容
text = pd_data['发帖内容'].tolist()
# 切割分词
wordlist = jieba.lcut_for_search(''.join(text))
result = ' '.join(wordlist)
# 设置停用词
stop_words = ['你', '我', '的', '了', '们']
ciyun_words = ''
for word in result:
if word not in stop_words:
ciyun_words += word
# 权重分析
tag = jieba.analyse.extract_tags(sentence=ciyun_words, topK=10, withWeight=True)
print(tag)
'''
[('尔克', 0.529925025347557),
('国货', 0.2899827734123779),
('加油', 0.22949648081224758),
('鸿星', 0.21417335917247557),
('支持', 0.18191311638625407),
('良心', 0.09360297619470684),
('鞋子', 0.07001117869641693),
('之光', 0.06217569267289902),
('企业', 0.061882654176791535),
('直播', 0.059315225448729636)]
'''topK就是指你想输出多少个词,withWeight指输出的词的词频。
分词介绍完了,接下来我们介绍一下绘图库
wordcloud
我们词云的主要实现是用过 wordcloud 模块中的 WordCloud 类实现的,我们先来了解一个 WordCloud 类。
安装
pip install wordcloud生成一个简单的词云
我们实现一个简单的词云的步骤如下:
导入 wordcloud 模块
准备文本数据
创建 WordCloud 对象
根据文本数据生成词云
保存词云文件
我们按照上面的步骤实现一个最简单的词云:
# 导入模块
from wordcloud import WordCloud
# 文本数据
text = 'he speak you most bueatiful time|Is he first meeting you'
# 词云对象
wc = WordCloud()
# 生成词云
wc.generate(text)
# 保存词云文件
wc.to_file('img.jpg')
可以看到,目标是实现了,但是效果不怎么好。我们继续往下看
WordCloud 的一些参数
我们先看看 WordCloud 中的一些参数,
如下表,各个参数的介绍都写了。
| 参数 | 参数类型 | 参数介绍 |
| width | int(default=400) | 词云的宽 |
| height | int(default=200) | 词云的高 |
| background_color | color value(default=”black”) | 词云的背景颜色 |
| font_path | string | 字体路径 |
| mask | nd-array(default=None) | 图云背景图片 |
| stopwords | set | 要屏蔽的词语 |
| maxfontsize | int(default=None) | 字体的最大大小 |
| minfontsize | int(default=None) | 字体的最小大小 |
| max_words | number(default=200) | 要显示词的最大个数 |
| contour_width | int | 轮廓粗细 |
| contour_color | color value | 轮廓颜色 |
| scale | float(default=1) | 按照原先比例扩大的倍数 |
我们来测试一下上面的参数:
# 导入模块
from wordcloud import WordCloud
# 文本数据
text = 'he speak you most bueatiful time Is he first meeting you'
# 准备禁用词,需要为set类型
stopwords = set(['he', 'is'])
# 设置参数,创建WordCloud对象
wc = WordCloud(
width=200, # 设置宽为400px
height=150, # 设置高为300px
background_color='white', # 设置背景颜色为白色
stopwords=stopwords, # 设置禁用词,在生成的词云中不会出现set集合中的词
max_font_size=100, # 设置最大的字体大小,所有词都不会超过100px
min_font_size=10, # 设置最小的字体大小,所有词都不会超过10px
max_words=10, # 设置最大的单词个数
scale=2 # 扩大两倍
)
# 根据文本数据生成词云
wc.generate(text)
# 保存词云文件
wc.to_file('img.jpg')
生成一个有形状的词云
我们设置的图形形状是

import pandas as pd
import jieba.analyse
from wordcloud import WordCloud
import cv2
# 读取文件
pd_data = pd.read_excel('鸿星尔克.xlsx')
# 读取内容
text = pd_data['发帖内容'].tolist()
# 切割分词
wordlist = jieba.lcut_for_search(''.join(text))
result = ' '.join(wordlist)
# 设置停用词
stop_words = ['你', '我', '的', '了', '们']
ciyun_words = ''
for word in result:
if word not in stop_words:
ciyun_words += word
# 读取图片
im = cv2.imread('11.jpg')
# 设置参数,创建WordCloud对象
wc = WordCloud(
font_path='msyh.ttc', # 中文
background_color='white', # 设置背景颜色为白色
stopwords=stop_words, # 设置禁用词,在生成的词云中不会出现set集合中的词
mask=im
)
# 根据文本数据生成词云
wc.generate(ciyun_words)
# 保存词云文件
wc.to_file('img.jpg')
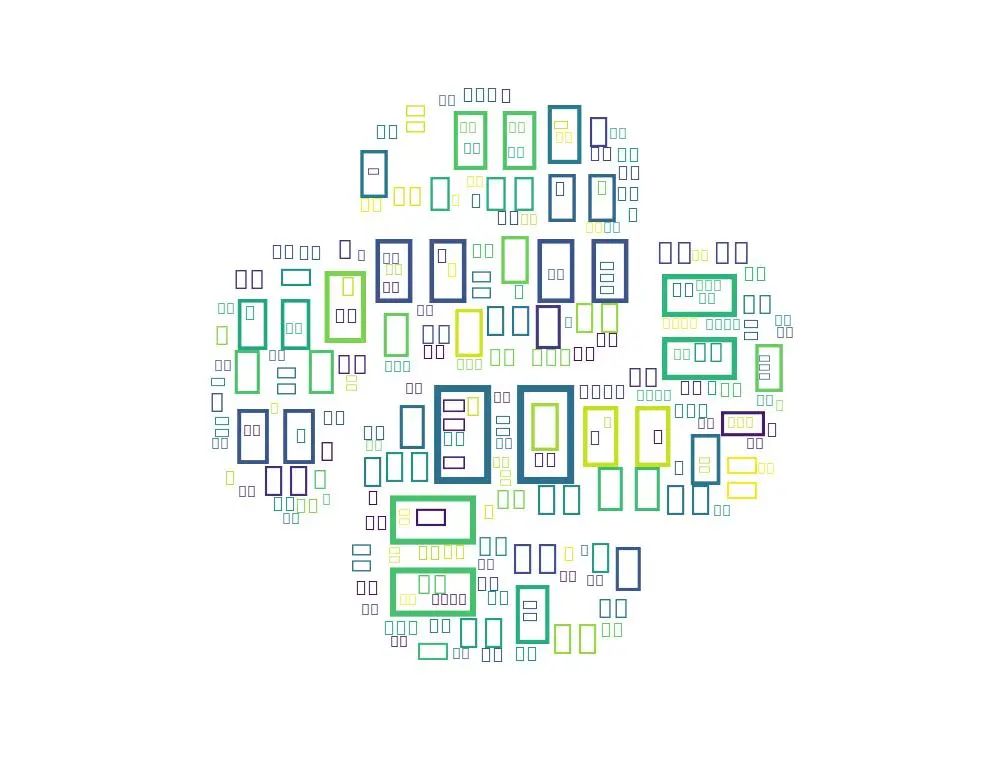
发现全是矩形,这是因为 WordCloud 默认不支持中文的缘故,我们需要设置一个可以支持中文的字体,我们添加代码如下:
# 创建词云对象
wc = WordCloud(font_path='msyh.ttc')
文末再给大家介绍一个宝藏库
stylecloud使用它设置词云再简单不过了,为什么?
因为它有7865个词云图标供你选择。
需要使用那个图标只需复制下面的图标名称即可!
而且自带停用词的那种
import pandas as pd
import jieba.analyse
from stylecloud import gen_stylecloud
# 读取文件
pd_data = pd.read_excel('鸿星尔克.xlsx')
exist_col = pd_data.dropna() # 删除空行
# 读取内容
text = exist_col['发帖内容'].tolist()
# 切割分词
wordlist = jieba.cut_for_search(''.join(text))
result = ' '.join(wordlist)
gen_stylecloud(text=result,
icon_name='fas fa-comment-dots',
font_path='msyh.ttc',
background_color='white',
output_name='666.jpg',
custom_stopwords=['你', '我', '的', '了', '在', '吧', '相信', '是', '也', '都', '不', '吗', '就', '我们', '还', '大家', '你们', '就是', '以后']
)
print('绘图成功!')





又方便又好看,是我现在制作词云的首选!

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 89
89 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)