kafka部分partition消息堆积问题解决记录01
项目场景: 某个实时高流量的数据流的数据统计模块,需要实时读取kafka数据并进行数种数据统计分析。问题描述: 负责关注数据流部分后,发现监控系统不断向我手机发送短信报警,报警内容指明是kafka的某个ConsumerGroup:topic的某些分区消息延迟Lag过高! 马上监控系统web端可以看到:kafka对应ConsumerGroup:topic的消息延迟Lag非常不均匀,部分分区的L
项目场景:
某个实时高流量的数据流的数据统计模块,需要实时读取kafka数据并进行数种数据统计分析。
问题描述:
负责关注数据流部分后,发现监控系统不断向我手机发送短信报警,报警内容指明是kafka的某个ConsumerGroup:topic的某些分区消息延迟Lag过高!
马上监控系统web端可以看到:
kafka对应ConsumerGroup:topic的消息延迟Lag非常不均匀,部分分区的Lag处于正常水平,而部分分区的Lag却不断堆积,甚至Lag值超过上亿。
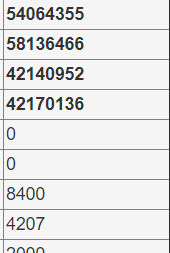
原因分析:
1、确定排查方向
1、初次进行kafka实战,通过查阅相关资料,得知kafka的partition积攒过多的原因大致有:
- 生产速度过高,消费速度低于生产速度
- 客户端的消息消费逻辑耗时太长,如果生产端消息发送速度增加,这时就很容易导致堆积
- 部分堆积情况下,可能是部分kafka消费者出现问题
对应场景分析:
- 原因一:如果是消费速度低于生产速度,出现场景应该是所有partition均产生消息堆积问题!因此,该问题是次要的。
- 原因二:如果是消费逻辑耗时过长,出现场景应该同原因一,而且消费者模块的消费逻辑仅仅是统计数据,消费逻辑反而是耗时很短的。因此该问题也是次要的。
- 原因三:显然,这种情况很可能是部分kafka消费者出现问题。初次接触询问同事时,同事也是第一时间通过重启消费者模块以尝试解决问题。
由此初步确定问题来源于消费端模块。需要重点排查消费端模块运行情况。
2、找到问题源头
已经确定重点排查方向,但是通过监控系统web界面,只能得知该topic的partition有 75 个,消费者数量有 48 个及各消费者的服务器部署情况,如何确定造成partition消息延迟的消费者是哪个或哪些呢?
2.1、partition与consumer的绑定关系
通过查询大量资料,得知kafka的consumer采用pull(拉)模式从broker中读取数据,而一条数据只能被一个consumer Group消费一次。每条消息只消费一次的实现原理很简单:
- 将同一consumer Group的每个consumer与对应的partition(一个或多个)一一绑定。这样就能保证一个partition中产生的消息只能被一个consumer消费。
- producer端生产的消息只能发送到topic的其中一个partition中。
这样就实现了每条消息只消费一次
2.2、消费者分区分配策略:在构建KafkaConsumer类的时候可以配置。(默认是Range策略)
1、range范围策略:(默认情况)
1、思想:首先对同一个Topic里面的分区按照序号进行排序,并对消费者id按照字典序进行排序。
然后用Partitions分区的个数除以消费者的消费者线程总数来决定每个消费者消费哪几个分区;
如果除不尽,则前面的几个消费者线程会多消费一个分区。
2、具体实现:假设区分数量为pCout,消费者数量为cCount
n = pCout / cCount
m = pCount % cCount
前m个消费者得到n+1个分区,剩余的消费者分配到n个分区
具体分配:遍历消费者并判断,如果当前消费者是前m个消费者,则分配连续的n+1个分区,否则分配n个分区
3、优缺点:弊端在于如果分区和消费者不能平均分配的话就会造成前几个消费者多分配分区,导致资源负载不均衡。
如果前几个消费者订阅多个主题,且这些主题的分区均不能平均分配,就会导致前几个消费者消费分区数比其他消费者要多很多
2、roudRobin轮询策略:(这里是指遍历partition,轮询消费者)
1、思想:首先对同一个Topic里面的分区按照序号进行排序,并对消费者按照字母进行排序。
然后,它继续执行从分区到消费者的循环分配。如果消费者没有订阅主题,则会跳过该消费者
2、具体实现:循环遍历partition,维护一个消费者环和一个指针,每次将指针向后移动一次以实现轮询、
如果当前指针指向的消费者没有订阅本次遍历到的partition的topic,则会跳过该消费者,继续移动指针
3、优缺点:弊端在于如果消费者之间订阅的主题不相同时,则会造成资源分配不均衡。
3、Sticky粘性分配策略:(待补充)
4、自定义策略:(待补充)
可以通过继承AbstractPartitionAssignor抽象类,实现它的assign方法,来自定义消费者分区分配策略,
根据消费者数据统计模块的源码及配置,可以确定没有配置消费者分区策略,因此应该是默认的Range策略。由此可以得知partition的分配情况了。
2.3、但是问题又出现了。已经知道partition的分配策略,但是具体partition分配到哪个consumer呢?网上没有相关的consumerId生成情况的资料!
通过查看kafka源码的RangeAssignor类(Range策略),可以看到确实是按ConsumerId排序并进行分配的,但consumerId是通过函数传参Map<String, Subscription> subscriptions已经提供了:
@Override
public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic,
Map<String, Subscription> subscriptions) {
//topic:consumer集合
Map<String, List<String>> consumersPerTopic = consumersPerTopic(subscriptions);
// 存储实际分配结果,结构为consumerId:消费的分区
Map<String, List<TopicPartition>> assignment = new HashMap<>();
// key为所有的consumerId
for (String memberId : subscriptions.keySet())
assignment.put(memberId, new ArrayList<TopicPartition>());
//遍历topic:消费者
for (Map.Entry<String, List<String>> topicEntry : consumersPerTopic.entrySet()) {
String topic = topicEntry.getKey();
List<String> consumersForTopic = topicEntry.getValue();
//获取该topic的分片数
Integer numPartitionsForTopic = partitionsPerTopic.get(topic);
if (numPartitionsForTopic == null)
continue;
// consumerId排序
Collections.sort(consumersForTopic);
int numPartitionsPerConsumer = numPartitionsForTopic / consumersForTopic.size();
int consumersWithExtraPartition = numPartitionsForTopic % consumersForTopic.size();
List<TopicPartition> partitions = AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic);
for (int i = 0, n = consumersForTopic.size(); i < n; i++) {
int start = numPartitionsPerConsumer * i + Math.min(i, consumersWithExtraPartition);
int length = numPartitionsPerConsumer + (i + 1 > consumersWithExtraPartition ? 0 : 1);
assignment.get(consumersForTopic.get(i)).addAll(partitions.subList(start, start + length));
}
}
return assignment;
}
万般无奈下,突然想到kafka集群是需要在zookeeper上注册节点信息的,会不会consumerId信息也有注册呢?!
赶紧来到kafka注册的zookeeper集群服务器并通过zkCli.sh进入zookeeper客户端,仔细查找后终于找到了!!!
查看ConsumerId的zookeeper节点具体路径是:
/【...kafka注册根路径】/consumers/【具体consumer group】/ids/*
通过get命令查看其下的ConsumerId可以看到对应的信息,其中的subscription指明了该consumerId消费的topic名称。
通过对比查询发现,consumerId的生成规则是:
[具体consumer Group] _ [服务器主机host] - [ 13位时间戳 ] - [8位随机字符]
按该规则对48个consumer进行排序,并结合前面Range策略即可获取到partition与consumer的一一对应关系!!!
到此,问题具体源头成功定位!开始排查问题产生原因并加以解决!
3、问题产生原因排查
该数据统计模块是java程序,且默认配置是一个java进程配置有8个consumer线程进行kakfa读取消费;
因此,首先根据消息堆积partition推断出具体consumer所在服务器主机、服务器内java进程号pid等相关信息;
来到对应服务器进行具体排查:
3.1、首先分析程序运行状态:
1、首先通过 以下命令 分析consumer线程的运行情况:
1.1、查看consumer线程状态:
jstack [pid] | grep [consumer名] //查看consumer状态
可以结合 watch命令 进行持续监控,分析其状态信息。
结果发现线程大部分时间处于Wait on condition状态,网上查询得知该状态出现在线程等待某个条件的发生。具体是什么原因,可以结合stacktrace来分析。
1.2、生成thread dump文件,查看consumer线程堆栈及死锁情况:
jstack -l [pid] > [dump文件].log
分析dump文件发现没有发生死锁的情况,程序正常推进。结合其stacktrace,发现其一直卡在unsafe.unpark()处。网上查询找不到原因,推测以下因素可能导致consumer持续阻塞:
- JVM资源分配不合理,GC太过频繁导致工作线程频繁阻塞
- 外部服务器资源不足导致进程因竞争资源而阻塞
3.2、排查GC问题:
1、通过 jstat 配合 watch 命令监听程序GC情况:
watch -n [间隔时间] -d "jstat -gc [pid]"
发现GC频率很低,对象生产速率极其缓慢。思考后发现由于工作线程均大部分时间处于阻塞状态。
3.3、排查服务器资源问题:
1、首先通过 top命令 查看服务器整体资源情况:
top
发现CPU、Mem内存、系统负载情况均处于正常水平,不存在资源不足情况。
2、由于该模块主要是读取kafka消息,需要占用一定带宽。因此猜测可能内网带宽存在限制。
网上查询到几种可用的查看网络IO情况的命令均属于第三方命令,需要安装后才可使用。显然我并没有安装权限。
通过大量查询后得知可以通过以下命令对比查看总体网络IO情况通过以下命令监控当前服务器的带宽情况:
watch -n 1 -d "ifconfig [网卡] | grep bytes"
发现内外带宽达到了60~70MBps。询问同事后,得知该带宽是平均每台机器的带宽峰值了。由此初步确定本台服务器内网带宽达到瓶颈。再细看发现该服务器部署了两个该数据统计模块的进程,难怪容易达到瓶颈。看来需要调整数据统计模块的部署了。
3、同样命令查看其他服务器内网带宽情况并调整部署;再次查看consumer线程情况,发现均持续处于Runnable状态高速消费kafka消息了。
回到监控系统web界面监听一会kafka,发现消息堆积的partition,其Lag也在匀速降低中。
至此,kafka部分分区消息堆积问题得以解决。
4、后续:一次consumer进程JVM调优:
1、记录一次JVM简单调优01
2、观察到即使在高峰期,一个consumer也能有余力同时消费两个partition,为节省服务器资源,后续调整consumer数为40个。
5、思考:
1、对于各模块的部署,我们应该要有目的的选择服务器,根据模块的主要需求资源进行有针对性的部署,充分利用服务器的资源,同时也不能让服务器资源超用,导致资源竞争,反而拖慢各模块的运行情况。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)