

场景应用:将MySQL的变化数据转为实时流输出到Kafka中。
注意版本问题,版本不同可能会出现异常,以下版本测试没问题:
flink1.12.7
flink-connector-mysql-cdc 1.3.0(com.alibaba.ververica) (测试时使用1.2.0版本时会出现空指针错误)
1. MySQL的配置
在/etc/my.cnf文件中,【mysqld】下面添加以下配置:
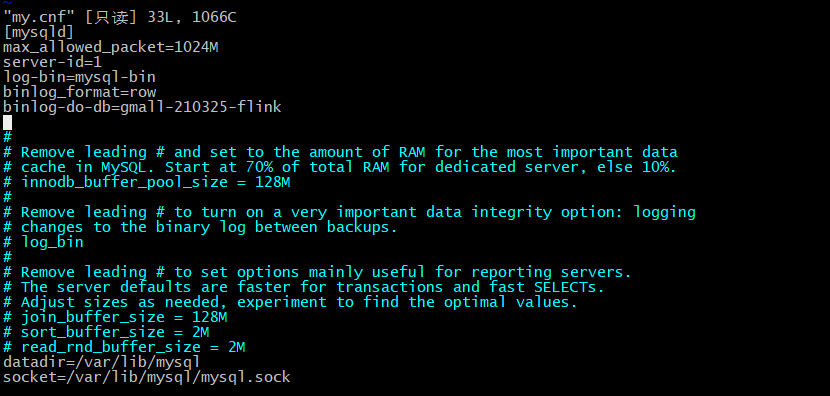
binlog-do-db 是指定要监控的数据库,如果是多个数据库,每个数据库需要单独一行设置。
修改完成后,需要重启数据库,并检查binlog有没有生成。
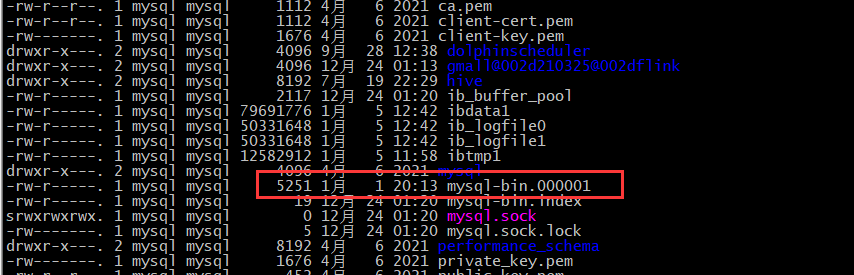
补充几个其他的配置:
1、修改配置
[mysqld]
# 前面还有其他配置
# 添加的部分
server-id = 12345
log-bin = mysql-bin
# 必须为ROW
binlog_format = ROW
# 必须为FULL,MySQL-5.7后才有该参数
binlog_row_image = FULL
expire_logs_days = 15
2、验证
SHOW VARIABLES LIKE '%binlog%';
3、设置权限
-- 设置拥有同步权限的用户
CREATE USER 'flinkuser' IDENTIFIED BY 'flinkpassword';
-- 赋予同步相关权限
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'flinkuser';
创建用户并赋予权限成功后,使用该用户登录MySQL,可以使用以下命令查看主从同步相关信息
SHOW MASTER STATUS
SHOW SLAVE STATUS
SHOW BINARY LOGS
2. FlinkCDC的开发
从这里开始建立flink工程项目,以下项目flink版本为1.12.7,scala版本用的2.12。
大概的思考步骤如下:
1) 获取执行环境
2)开启检查点ck (重点)
3)通过flinkcdc构建sourceFunction,并读取数据 (重点)
4)在执行环境中添加3)中构建的source
5)配置kafka生产者环境(重点)
6)在执行环境中增加5)中的Sink
7)启动任务
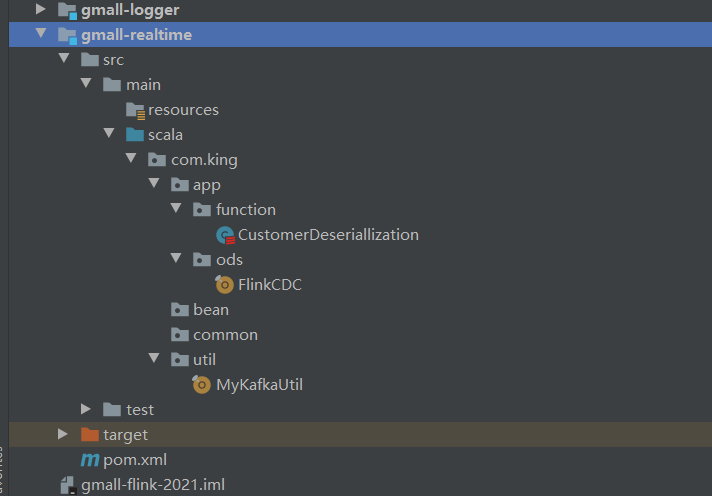
项目结构(gmall-realtime)如下:
2.1 Pom文件配置
由于这是我的一个子项目,所以实际使用的时候自己修改。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>gmall-flink-2021</artifactId>
<groupId>com.king</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>gmall-flink-cdc</artifactId>
<version>1.0</version>
<properties>
<java.version>1.8</java.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<flink.version>1.12.7</flink.version>
<scala.version>2.12</scala.version>
<hadoop.version>3.1.3</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.68</version>
</dependency>
<!--如果保存检查点到 hdfs 上,需要引入此依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>1.3.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.ververica/flink-connector-mysql-cdc -->
<!-- <dependency> 该包仅支持flink1.13版本及以上-->
<!-- <groupId>com.ververica</groupId>-->
<!-- <artifactId>flink-connector-mysql-cdc</artifactId>-->
<!-- <version>2.1.1</version>-->
<!-- </dependency>-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
<!--Flink 默认使用的是 slf4j 记录日志,相当于一个日志的接口,我们这里使用 log4j 作为
具体的日志实现-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.32</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.32</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.17.1</version>
</dependency>
</dependencies>
<build>
<!-- <sourceDirectory>${project.basedir}/src/main/scala</sourceDirectory>-->
<!-- <resources>-->
<!-- <resource>-->
<!-- <directory>${project.basedir}/src/main/resources</directory>-->
<!-- </resource>-->
<!-- </resources>-->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
注意一点:如果使用java开发,可以直接编译成功。但是我这里全部使用scala开发,所以需要在pom文件配置额外的插件,否则打包scala项目会不成功。
<plugins>
<plugin>
<!-- !!必须有这个插件,才可以编译scala代码找到主类,版本我是网上搞来的 -->
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<id>compile-scala</id>
<phase>compile</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>test-compile-scala</id>
<phase>test-compile</phase>
<goals>
<goal>add-source</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
2.2 读取MySQL
Flinkcdc.scala中:
通过引入的flink-connector-mysql-cdc已经提供了读取MySQL的工具类。
val sourceFunction = MySQLSource.builder[String]()
.hostname("hadoop200")
.port(3306)
.username("root")
.password("root")
.databaseList("gmall-210325-flink")
//如果不添加该参数,则消费指定数据库中所有表的数据
//如果添加,则需要按照 数据库名.表名 的格式指定,多个表使用逗号隔开
// .tableList("gmall-210325-flink.base_trademark")
.deserializer(new CustomerDeseriallization())
new CustomerDeseriallization() 是自定义的读取的MySQL的数据输出格式,如果不指定,系统也有个new StringDebeziumDeserializationSchema()可以使用。
2.3 自定义从MySQL读取的数据的输出格式
CustomerDeseriallization类
package com.king.app.function
import com.alibaba.fastjson.JSONObject
import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema
import org.apache.flink.api.common.typeinfo.{BasicTypeInfo, TypeInformation}
import org.apache.flink.util.Collector
import org.apache.kafka.connect.data.{Schema, Struct}
import org.apache.kafka.connect.source.SourceRecord
/**
* @Author: KingWang
* @Date: 2021/12/29
* @Desc:
**/
class CustomerDeseriallization extends DebeziumDeserializationSchema[String]{
/**
* 封装的数据:
* {
* "database":"",
* "tableName":"",
* "type":"c r u d",
* "before":"",
* "after":"",
* "ts": ""
*
* }
*
* @param sourceRecord
* @param collector
*/
override def deserialize(sourceRecord: SourceRecord, collector: Collector[String]): Unit = {
//1. 创建json对象用于保存最终数据
val result = new JSONObject()
val value:Struct = sourceRecord.value().asInstanceOf[Struct]
//2. 获取库名&表名
val source:Struct = value.getStruct("source")
val database = source.getString("db")
val table = source.getString("table")
//3. 获取before
val before = value.getStruct("before")
val beforeObj = if(before != null) getJSONObjectBySchema(before.schema(),before) else new JSONObject()
//4. 获取after
val after = value.getStruct("after")
val afterObj = if(after != null) getJSONObjectBySchema(after.schema(),after) else new JSONObject()
//5. 获取操作类型
val op:String = value.getString("op")
//6. 获取操作时间
val ts = source.getInt64("ts_ms")
// val ts = value.getInt64("ts_ms")
//7. 拼接结果
result.put("database", database)
result.put("table", table)
result.put("type", op)
result.put("before", beforeObj)
result.put("after", afterObj)
result.put("ts", ts)
collector.collect(result.toJSONString)
}
override def getProducedType: TypeInformation[String] = {
BasicTypeInfo.STRING_TYPE_INFO
}
//从Schema中获取字段和值
def getJSONObjectBySchema(schema:Schema,struct:Struct):JSONObject = {
val fields = schema.fields()
var jsonBean = new JSONObject()
val iter = fields.iterator()
while(iter.hasNext){
val field = iter.next()
val key = field.name()
val value = struct.get(field)
jsonBean.put(key,value)
}
jsonBean
}
}
2.4 写入到Kafka
package com.king.util
import org.apache.flink.api.common.serialization.{SerializationSchema, SimpleStringSchema}
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer
/**
* @Author: KingWang
* @Date: 2022/1/1
* @Desc:
**/
object MyKafkaUtil {
val broker_list = "hadoop200:9092,hadoop201:9092,hadoop202:9092"
def getKafkaProducer(topic:String):FlinkKafkaProducer[String] =
new FlinkKafkaProducer[String](broker_list,topic,new SimpleStringSchema())
}
FlinkCDC.scala的完整代码如下:
package com.king.app.ods
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource
import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions
import com.king.app.function.CustomerDeseriallization
import com.king.util.MyKafkaUtil
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
/**
* @Author: KingWang
* @Date: 2021/12/26
* @Desc:
**/
object FlinkCDC {
def main(args: Array[String]): Unit = {
//1. 获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//1.1 开启ck并指定状态后端fs
// env.setStateBackend(new FsStateBackend("hdfs://hadoop200:8020/gmall-flink-210325/ck"))
// .enableCheckpointing(10000L) //头尾间隔:每10秒触发一次ck
// env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) //
// env.getCheckpointConfig.setCheckpointTimeout(10000L)
// env.getCheckpointConfig.setMaxConcurrentCheckpoints(2)
// env.getCheckpointConfig.setMinPauseBetweenCheckpoints(3000l) //尾和头间隔时间3秒
// env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 10000L));
//2. 通过flinkCDC构建SourceFunction并读取数据
val sourceFunction = MySQLSource.builder[String]()
.hostname("hadoop200")
.port(3306)
.username("root")
.password("root")
.databaseList("gmall-210325-flink")
//如果不添加该参数,则消费指定数据库中所有表的数据
//如果添加,则需要按照 数据库名.表名 的格式指定,多个表使用逗号隔开
// .tableList("gmall-210325-flink.base_trademark")
.deserializer(new CustomerDeseriallization())
//监控的方式:
// 1. initial 初始化全表拷贝,然后再比较
// 2. earliest 不做初始化,只从当前的
// 3. latest 指定最新的
// 4. specificOffset 指定offset
// 3. timestamp 比指定的时间大的
.startupOptions(StartupOptions.latest())
.build()
val dataStream = env.addSource(sourceFunction)
//3. sink, 写入kafka
dataStream.print()
val sinkTopic = "ods_base_db"
dataStream.addSink(MyKafkaUtil.getKafkaProducer(sinkTopic))
//4. 启动任务
env.execute("flinkCDC")
}
}
3. 测试项目
准备好kafka,mysql,可以在本地测试。
启动kafka消费者,topic是ods_base_db

在idea中启动flinkcdc程序。
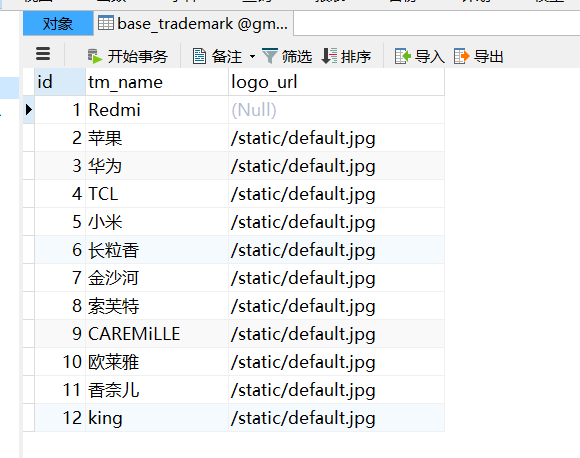
打开mysql编辑器,表base_trademark中原始记录有12条如下:
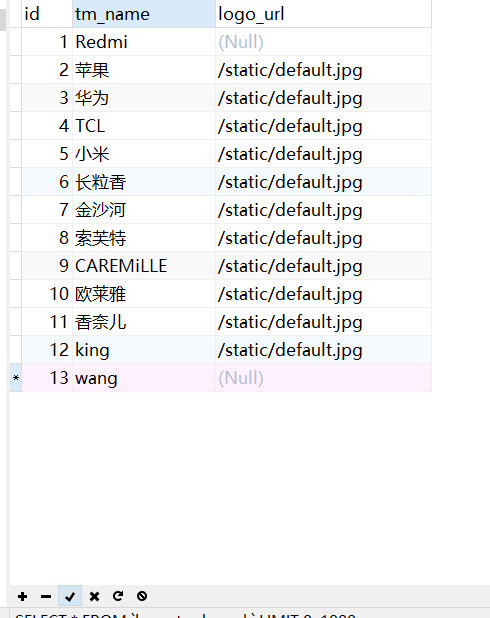
现在手工增加一条记录,编号为13 wang
查看idea控制台显示添加消息如下:
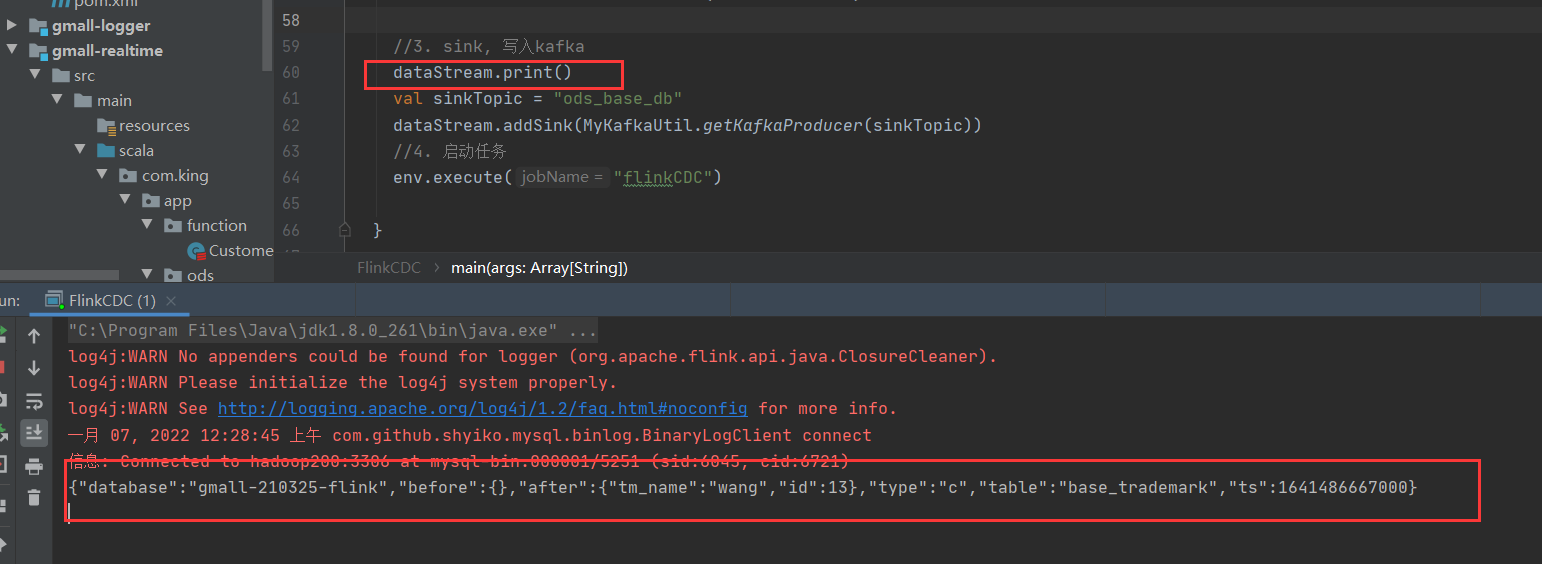
同时在Kafka消费者也看到一条记录如下,字段type为操作类型,c表示创建

再次在MySQL中做修改和删除操作,可以看到控制多了两条记录,操作类型分别为u和d,表示修改和删除操作。

到此flinkcdc的操作基本完成。







 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)