redis基础入门
key-value是redis的数据存储基本格式。
文章目录
redis总结
1.数据类型
key-value是redis的数据存储基本格式
key
命名规范:
表名:主键名:主键值:字段名
new:ID:1:name
key的常用命令:
exists key:判断键是否存在
del key:删除键值对
move key db:将键值对移动到指定数据库
expire key second:设置键值对的过期时间
type key:查看value的数据类型
value
value的种类
value有五种基本类型:string、set、zset、list、hash、hyperloglog、geospatial、bitmaps等。
zest和set的区别
zset和set都可以用于存储不重复的数据,但其中zset和set的区别在于前者是排好序的,而后者是无序的,zset的底层是dict(hash)加skiplist(用于排序)的结构,但set则只是dict的结构,只能用于快速查找和是否有重复的。
2.锁和事务
锁
分布式锁
setnx lock-key value//加锁
del lock-key//解锁
expire lock-key second //给该key加一个失效时间,以防忘记解锁。
lock-key也是key,不过其命名规范要求是需要被加锁的key前加上lock-,以表明这个lock-key是key的锁,改变key的value时,需要执行setnx lock-key value加锁,比如:
set num 10
setnx lock-num 1//加锁
incr num
del lock-key//解锁
//通过lock-num的命名格式就知道lock-num是用于num的锁
基于特定条件的事务执行——锁
watch key1 [key2……]// 对 key 添加监视锁,在执行exec前如果key发生了变化,终止事务执行
unwatch//取消对所有 key 的监视
事务
加入事务的命令暂时进入到任务队列中,并没有立即执行,只有执行exec命令才开始执行
multi //开启事务
exec// 执行事务
discard//终止当前事务
在事务开启之前 ,执行watch money观察数据,该客户端就会一直观察此数据,如果被其他客户端修改,则本此客户端之后的事务就会执行失败。
127.0.0.1:6379> set money 100 # 设置余额:100
OK
127.0.0.1:6379> set use 0 # 支出使用:0
OK
127.0.0.1:6379> watch money # 监视money (上锁)
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> DECRBY money 20
QUEUED
127.0.0.1:6379> INCRBY use 20
QUEUED
127.0.0.1:6379> exec # 监视值没有被中途修改,事务正常执行
1) (integer) 80
3.持久化
RBD
持久化就是将redis内存中的数据保存在磁盘的文件中。
RDB:将当前内存中的redis数据保存到磁盘中。
save//手动执行一次保存操作,立即执行
bgsave//手动启动后台保存操作,但不是立即执行
注意: bgsave命令是针对save阻塞问题做的优化。Redis内部所有涉及到RDB操作都采用bgsave的方式,save命令可以放弃使用
在conf文件中添加以下命令,服务器会自动执行bgsave:
dbfilename dump.rdb
说明:设置本地数据库文件名,默认值为 dump.rdb
经验:通常设置为dump-端口号.rdb
dir
说明:设置存储.rdb文件的路径
rdbcompression yes
说明:设置存储至本地数据库时是否压缩数据,默认为 yes,采用 LZF 压缩
rdbchecksum yes
说明:设置是否进行RDB文件格式校验,该校验过程在写文件和读文件过程均进行
stop-writes-on-bgsave-error yes
说明:后台存储过程中如果出现错误现象,是否停止保存操作
save second changes
说明:满足限定时间范围内key的变化数量达到指定数量即进行持久化
AOF(append only file)
AOF保存RESP(REdis Serialization Protocal)格式的数据。存入的是redis服务器的执行过的指令。
AOF持久化策略的选择:always,second,no。
在conf文件写入以下内容,会自动开启aof持久化:
appendonly yes # 默认是不开启aof模式的,默认是使用rdb方式持久化的,在大部分的情况下,rdb完全够用
appendfilename "appendonly.aof"
dir #AOF持久化文件保存路径,与RDB持久化文件保持一致即可
# appendfsync always # 每次修改都会sync 消耗性能
appendfsync everysec # 每秒执行一次 sync 可能会丢失这一秒的数据
# appendfsync no # 不执行 sync ,这时候操作系统自己同步数据,速度最快
AOF重写
执行bgrewriteaof,可以执行一次AOF重写。
在conf中添加以下内容可以自动重写:
自动重写触发条件设置
auto-aof-rewrite-min-size size
auto-aof-rewrite-percentage percentage
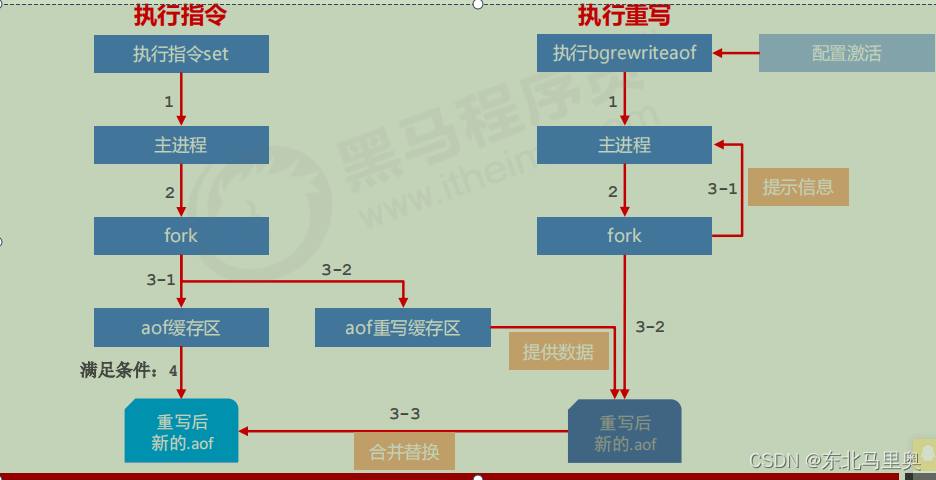
执行aof的子进程中有两个缓冲区aof缓冲区和aof重写缓冲区,在执行bgrewriteaof时,新建一个子进程,将aof重写缓冲器的内容写到aof文件中,重写缓冲区的内容就是根据redis当前的内容生成对应的指令,之后再将aof缓冲区的内容写到aof文件中。
RDB-AOF混合持久化
AOF持久化可以将丢失数据的时间窗口限制在1s之内,但是协议文本格式的AOF文件的体积将比RDB文件要大得多,并且数据恢复过程也会相对较慢
如果打开了服务器的AOF持久化功能,并且将aof-use-rdb-preamble 选项的值设置成了yes
那么 Redis服务器 在执行 AOF重写操作时,就会像执行BGSAVE命令那样,根据数据库当前的状态 生成出 相应的RDB数据,并将这些数据 写入 新建的AOF文件中,至于那些 在AOF重写开始之后 执行的Redis命令,则会继续以协议文本的方式 追加到 新AOF文件的末尾,即已有的RDB数据的后面
换句话说,在开启了RDB-AOF混合持久化功能之后,服务器生成的AOF文件将由两个部分组成,其中位于AOF文件开头的是RDB格式的数据,而跟在RDB数据后面的则是AOF格式的数据

通过使用RDB-AOF混合持久化功能,可以同时获得RDB持久化和AOF持久化的优点:服务器既可以通过AOF文件包含的RDB数据来实现快速的数据恢复操作,又可以通过AOF文件包含的AOF数据来将丢失数据的时间窗口限制在1s之内
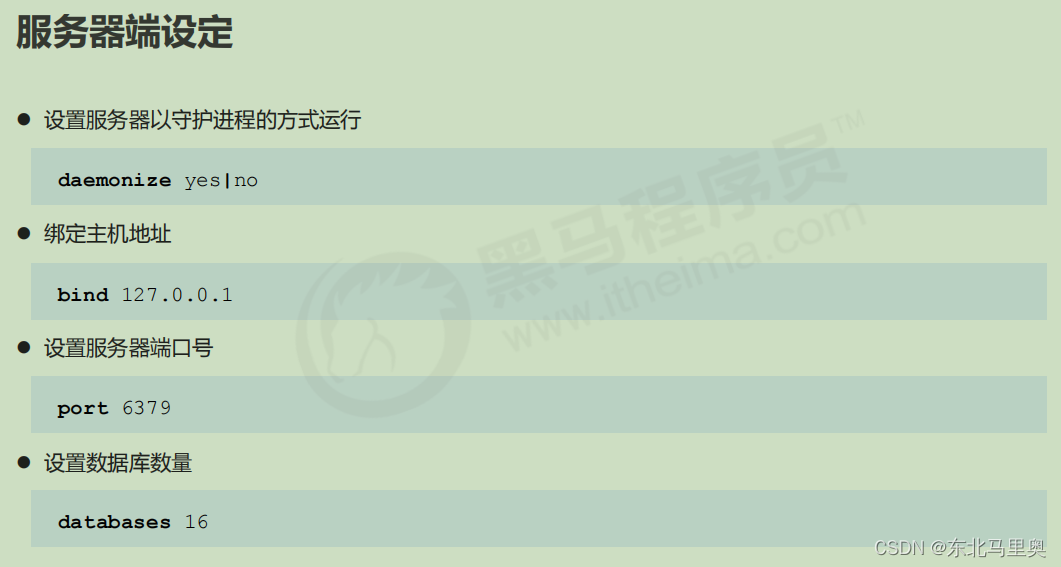
4.redis的conf文件的一些重要参数配置


5.主从复制
主从服务器的连接与断开
slave连接master方式
客户端发送命令:slaveof
启动服务器参数:redis-server -slaveof
服务器配置:slaveof
主从断开连接
客户端发送命令:slaveof no one ,从服务器不在作为主服务器的从机。
slave断开连接后,不会删除已有数据,只是不再接受master发送的数据
主从复制的工作流程
master可读可写,一般用于写,slave只能读。
部分复制的三个核心要素:
- 服务器的运行 id(run id)
- 主服务器的复制积压缓冲区
- 主从服务器的复制偏移量
服务器运行ID(runid):每个服务器都有一个运行id,用于身份识别,每次服务器重启,运行id都会重新生成。
复制缓冲区:master会把所有的命令以RESP格式存储起来并陆续发给从机。
复制偏移量:master存储每个slave的offset,offset表明slave接受到复制缓冲区的哪个字节。并根据slave的offset判断,slave是否出现由于网络等问题而发生的数据丢失现象。

全量复制阶段:slave和master建立socket。master会执行bgsave生成rdb发给slave和runid和offset,slave也将自己的runid发给master。
部分复制阶段:master根据offset将缓冲区的数据发给slave。
6.哨兵sentinel
哨兵在进行主从切换过程中经历三个阶段
监控
通知
故障转移
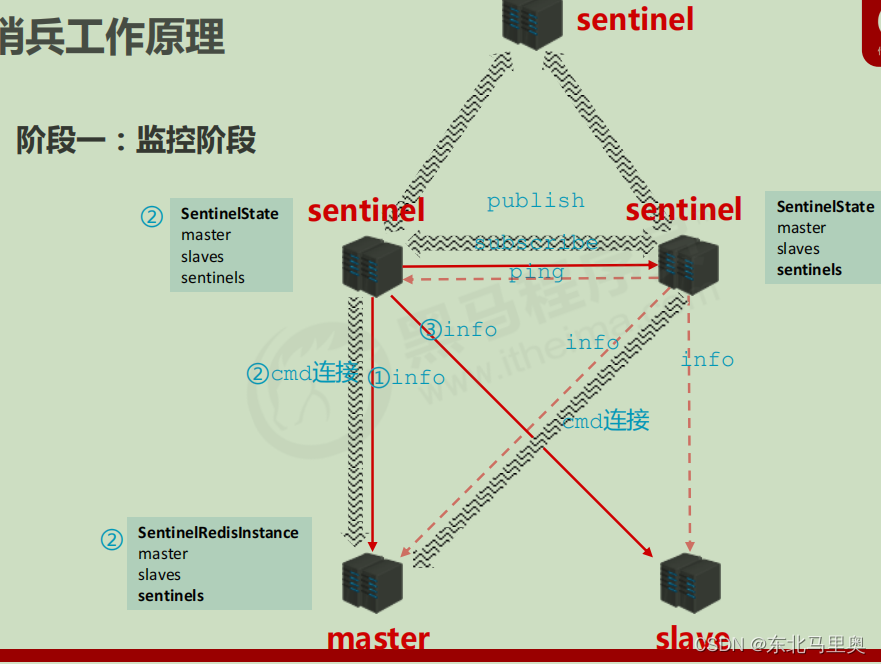
阶段一:监控阶段
每个sentinel都和master和slave建立cmd连接,获取info信息,得到master和 slave的runid和ip以及role等信息。然后所有sentinel相互ping,保持连接。
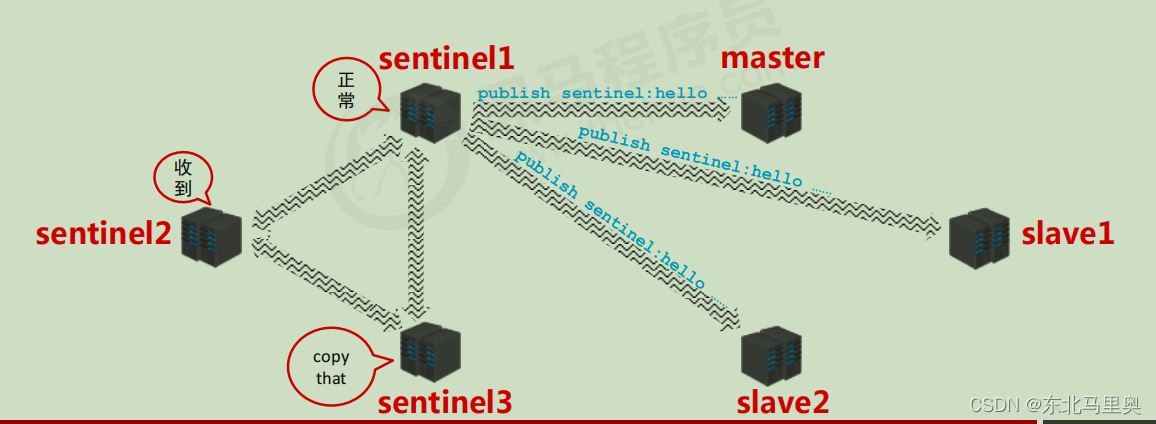
阶段二:通知阶段
sentinel相互通信,sentinel1负责与master和slave通信,判断是否有服务器故障。
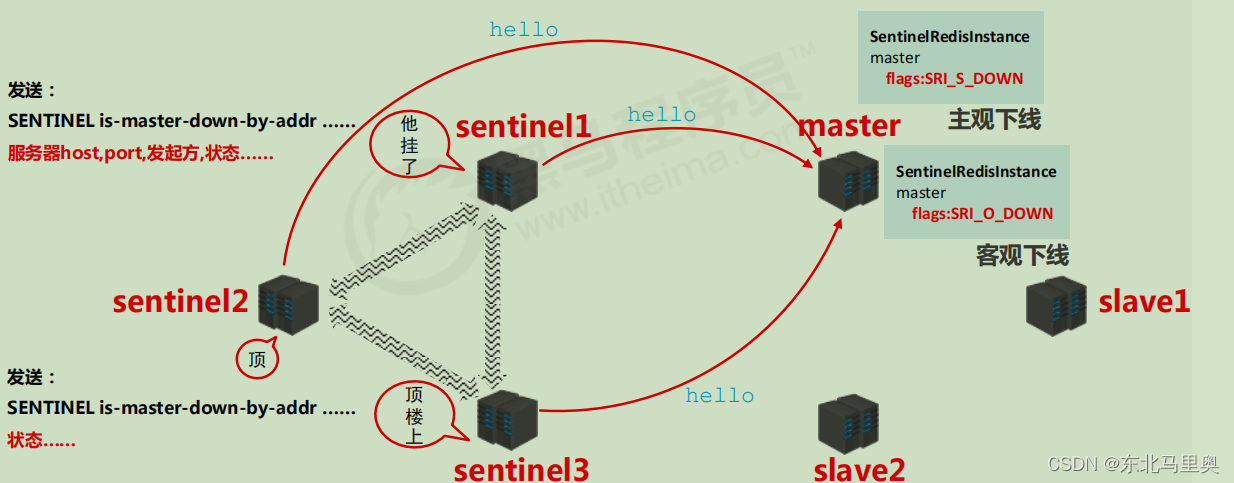
阶段三:故障转移阶段
sentinel1发现master故障时,此时哨兵将master标记为主观下线其他sentinel会接续和master通信,如果多数sentinel认为master故障,则将master下线(客观下线),并选择某个slave作为新的master。
7.cluster
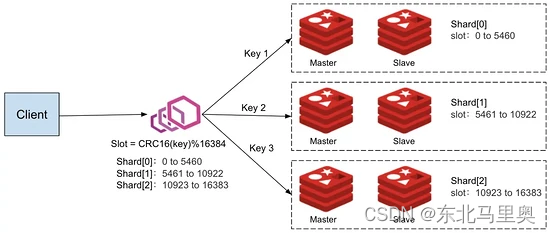
去中心化架构,不依赖外部存储,每个节点都有槽位信息、以及一部分数据,各节点之间使用gossip协议交互信息
划分为16384个slot槽位,每个key按照分片规则,对key做crc16 % 16384得到slot id
每个Redis节点存储了一部分槽位数据,各个Redis节点共同分担16384个slot槽位
客户端需遵守Redis cluster规范读写数据,客户端连接集群时,会得到一份集群的槽位配置信息,客户端本地缓存了slot到node的映射关系,以便直接定位到对应的Redis节点
用key计算出slot
通过本地缓存的slot到node映射关系(某个slot范围映射到某个node),用slot得出node
请求对应的node节点,如果key对应的槽位在Redis节点存储的各槽位中,则查询结果
如果key对应的槽位不在Redis节点存储的各槽位中(即key所在的槽位不归该节点管理),则返回moved <节点> 提示客户端再次请求指定的节点,并更新本地映射关系
如果请求的key对应槽位正在迁移,则返回ask <节点> 提示客户端再次请求指定的节点

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)